
Keep your data safe: Bring LLMs to you instead of sending data out

The global artificial intelligence market size is projected to be US$1,811.8 billion by 2030.1
The growth of AI has been compared to the early, untamed days of the Wild West, with technology quickly moving into uncharted areas. This expansion raises several issues, especially around data security and privacy.
75% of organizations across the world, in fact, are considering or implementing bans on ChatGPT and other generative AI applications in the workplace, with 67% of business leaders citing potential risk to data security and privacy as the biggest reason for doing so.2
Companies fear that data storage of these AI systems on external servers could potentially be leaked publicly, posing a security risk for the organization and its clients.
In this blog, we will discuss AI’s unique data privacy challenges and explore strategies to tackle them.
Data privacy challenges in AI environments
The global average cost of a data breach in 2023 was USD 4.45 million, a 15% increase over 3 years.3
AI solutions hold great promise, but they require access to vast amounts of data for training and ongoing operation. This demand for data raises a host of concerns and risks unique to AI:
1. Data ownership and control
The first and foremost challenge organizations face in the AI-driven era is related to data ownership and control. When enterprises share their data with AI providers, it raises several pertinent questions: Who owns the data? How is the data being utilized? Can it be misused or monetized without consent?
The concept of data sovereignty becomes critical here. Data sovereignty refers to the idea that data is subject to the laws and governance structures of the country in which it is located. Organizations must have a clear understanding of data ownership and control agreements with AI vendors. They should also consider the geographical location of data storage to comply with regional data protection regulations.
2. Data leakage
Data leakage is a major concern in the context of AI. Transmitting sensitive data to external AI platforms introduces vulnerabilities that could lead to data breaches or unauthorized access. The consequences of data leakage can be disastrous, including reputational damage, legal repercussions, and financial losses.
To mitigate this risk, organizations should prioritize secure data transmission protocols, end-to-end encryption, and comprehensive access control mechanisms. Regular audits and vulnerability assessments can help identify and rectify potential weaknesses in data handling processes.
3. Intellectual Property concerns
AI systems, while designed to learn, have the capability to generate intellectual property (IP) that comprises inventive algorithms, original content, or exclusive insights derived from data. To safeguard the organization’s interests, it is crucial to establish explicit policies and agreements pertaining to the ownership and utilization rights of any IP created by AI systems.
Moreover, it is important to consider the potential risks associated with IP infringement, particularly when AI-generated IP is derived from the organization’s data. This raises concerns about competitors benefiting from models trained on your data, highlighting the necessity for comprehensive monitoring and legal expertise in drafting contracts and agreements that protect the organization’s interests.
4. Accuracy and hallucination
AI models must prioritize not only accuracy but also consistency, ensuring that the same question elicits a consistent answer each time. This concept, known as ‘drift,’ emphasizes the necessity for AI systems to deliver reliable results consistently. While AI-generated outcomes should be accurate, any deviation from this standard can lead to significant consequences, including financial losses and compromised safety.
To address this challenge, organizations should implement comprehensive strategies such as meticulous data pre-processing, rigorous model validation, continuous monitoring, and human oversight. Collaborative efforts between human experts and AI can significantly enhance the reliability and consistency of AI-generated insights.
5. Data privacy regulations
The landscape of data privacy regulations is evolving rapidly. Regulations like the European Union’s General Data Protection Regulation (GDPR) and the California Consumer Privacy Act (CCPA) impose strict requirements on organizations to protect personal and sensitive data. Failing to comply with these regulations can result in hefty fines and legal repercussions.
Organizations must invest in robust data governance frameworks and data protection technologies to align with these regulations. Data anonymization, pseudonymization, and consent management tools should be part of the toolkit to ensure compliance.
Mitigating data privacy risks in AI
Addressing these challenges requires a multifaceted approach, encompassing technological solutions, ethical considerations, and proactive measures. Here are some key strategies and techniques to mitigate data privacy risks in an AI environment:
1. Data minimization
Data minimization involves limiting the amount of data shared with AI systems to only what is necessary for their intended purpose. By reducing the volume of data exposed to external AI providers, organizations can lower the risk of data breaches and privacy violations.
When implementing data minimization strategies for AI, particularly in the context of Language Models (LLMs), it is crucial to strike a balance between limiting data exposure and ensuring optimal model performance. Excessively minimizing data can lead to a higher likelihood of drift and hallucinations within the LLMs, ultimately compromising the quality and reliability of the AI-generated outcomes. It is essential to maintain an adequate dataset that allows LLMs to learn effectively without sacrificing the necessary data for accurate model training and performance. This ensures that the AI models retain their integrity and produce consistent and dependable results, minimizing the risks associated with drift and hallucinations.
2. Federated learning
Federated learning is an emerging technique that allows AI models to be trained on decentralized data sources without centralizing the data itself. This approach significantly enhances data privacy by keeping sensitive information in its original location.
In federated learning, AI algorithms are sent to the data sources, rather than the other way around. This eliminates the need to transfer sensitive data to external locations, reducing the risk of data exposure. Federated learning has its limits as general data often leads to hallucination and drift. The solution lies in deploying domain-specific models tailored to your specific industry or use case, ensuring accurate and relevant AI outcomes.
3. Privacy-preserving AI
Privacy-preserving AI technologies, such as homomorphic encryption and secure multi-party computation, play a pivotal role in safeguarding data privacy. These techniques allow data to remain encrypted and confidential throughout the AI processing pipeline.
Certain encryptions, for instance, enable computations on encrypted data without exposing the underlying information. This means AI models can analyze data without ever ‘seeing’ the raw data, making it a powerful tool for preserving privacy.
4. Transparent AI algorithms
Transparency is a fundamental element of responsible AI. Organizations should prioritize the use of AI models and algorithms that are interpretable and explainable. Transparent AI models provide insights into how decisions are made, making it easier to identify and address biases and errors.
Interpretable AI models also enhance trust among stakeholders, as they can understand the rationale behind AI-generated recommendations or decisions.
5. Data anonymization
Before sharing data with AI providers, organizations should employ data anonymization techniques to protect the privacy of individuals. Anonymization involves removing or obfuscating personally identifiable information (PII) from datasets while retaining their utility for AI training.
By anonymizing data, organizations can strike a balance between data utility and privacy protection, ensuring compliance with regulations like GDPR and CCPA.
While these are all valid solutions for privacy and protection, it’s important to note that there is a trade-off, as they can make the AI less intelligent and accurate. That is why Bruviti follows a different approach to data security.
Bruviti’s unique ‘embedded’ approach to data security
Building AI for the last six years, we learned early on that in a business context, the ability to manage and transform proprietary data and IP that feeds the AI was as important as developing the AI models themselves – for a solution to be practically usable in the real world.
Our approach has been to develop an enterprise-grade foundational platform to ingest large, diverse datasets and transform it so usable for machine learning (ML) techniques and natural language processing (NLP) that then feed our fine-tuned, domain-specific models. Critically, this foundation is designed to be embedded within your existing, secure enterprise IT environment ensuring that your data remains in-house, mitigating the risk of data leakage and that LLMs are trained on your specifically relevant data sets delivering precise and consistent outputs, providing you with the confidence to make informed decisions.
Benefits of embedded AI
The benefits of this embedded enterprise environment approach include:
Firewalled data: Ensuring that your proprietary data remains protected and secure within your system.
Hallucination-free: Delivering accurate and reliable results, you can trust to act upon, without errors or misinterpretations.
Persistent context: Maintaining the context of your data throughout the AI processes, ensuring reduction of drift and consistent outcomes.
Traceable answers: Allowing you to trace the origins of the provided answers, ensuring transparency and accountability.
PII anonymized: All data used in LLMs is automatically stripped of any personally identifiable information.
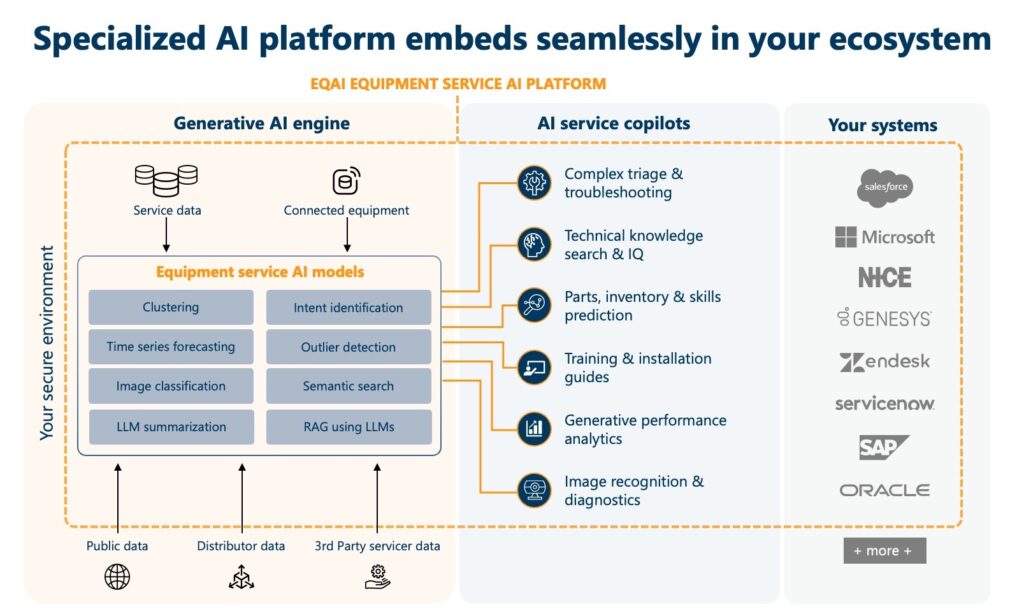
How Bruviti Equipment AI (EQAI) foundation works
Recognizing that the foundation of any successful AI project lies in the quality, security, and machine readiness of the data it uses, Bruviti’s domain-specialized EQAI is designed to be delivered as a service, embedded within your environment and under your control. Pre-built to do the heavy lift of transforming your data to be AI ready, it can be deployed in 5-7 weeks.
Seamless integration
EQAI seamlessly integrates with your existing systems and data sources, ensuring that AI operates securely within your organizational firewall. By embedding AI directly into your environment, you retain full control over your data, strengthening your ability to protect sensitive information. This approach guarantees that any intellectual property resulting from model learning or training stays with you, preserving ownership and data integrity.
Retrieval models and vector stores
EQAI leverages advanced retrieval models and vector stores to enhance data accessibility and utilization within your secure environment. These models are designed to facilitate efficient data search, analysis, and extraction, enabling users to swiftly locate and retrieve relevant information. By employing sophisticated vectorization techniques, EQAI transforms data into a format that is accessible for real-time querying and analysis by tuned LLMs.
Domain-specific language models
EQAI’s domain-specific LLMs enhance the precision and effectiveness of AI-powered operations. Tailored for specific tasks including search, triage, and prediction, and functioning within your secure environment, these specialized models trained on your specific domain data, ensure that sensitive data remains protected and that AI-generated outputs are accurate, reliable and can be used with confidence.
Furthermore, the delivery of AI within your existing system of record applications, including your Customer Relationship Management (CRM) system, offers additional security, safeguarding your data as effectively as the applications themselves. This ensures that your data remains protected throughout its integration with various systems.
Conclusion
In the AI industry, success depends on combining great AI performance with strong security measures. While public LLMs and techniques are good starting points, their limitations and risks become clear in real-world business settings. It’s important to use a thorough AI strategy that values both AI excellence and strong security.
At Bruviti, our goal is to help you use AI to achieve important business results, with a focus on control, security, and reducing risks. By placing the power of AI in your hands, we empower you to extract sustainable value from the training and learning of AI models to deliver outcomes tailor-made to your organization’s unique requirements and goals.