Fab downtime costs $1M+ per hour—your remote support stack determines whether issues resolve in minutes or cascade into dispatch.
Bruviti deployment data shows AI remote support cuts parts returns by 12 to 18% while resolving issues 20 to 30% faster. For tool builders, the cost case is concrete: fewer wrongly-returned components, shorter resolution cycles, and engineers spending less time diagnosing what the system already identified remotely.
Support engineers spend hours parsing tool logs, chamber sensor data, and recipe parameters across multiple systems. Complex semiconductor equipment generates gigabytes of telemetry per shift—pattern recognition is human-limited.
Remote sessions escalate to field service when diagnostics don't converge—often because support engineers lack visibility into full equipment state or historical failure patterns. Each escalation adds dispatch costs and extends downtime.
Resolution knowledge stays trapped in email threads, tribal expertise, and individual support engineers' notebooks. New engineers ramp slowly; veteran engineers become bottlenecks. No systematic capture of what worked.
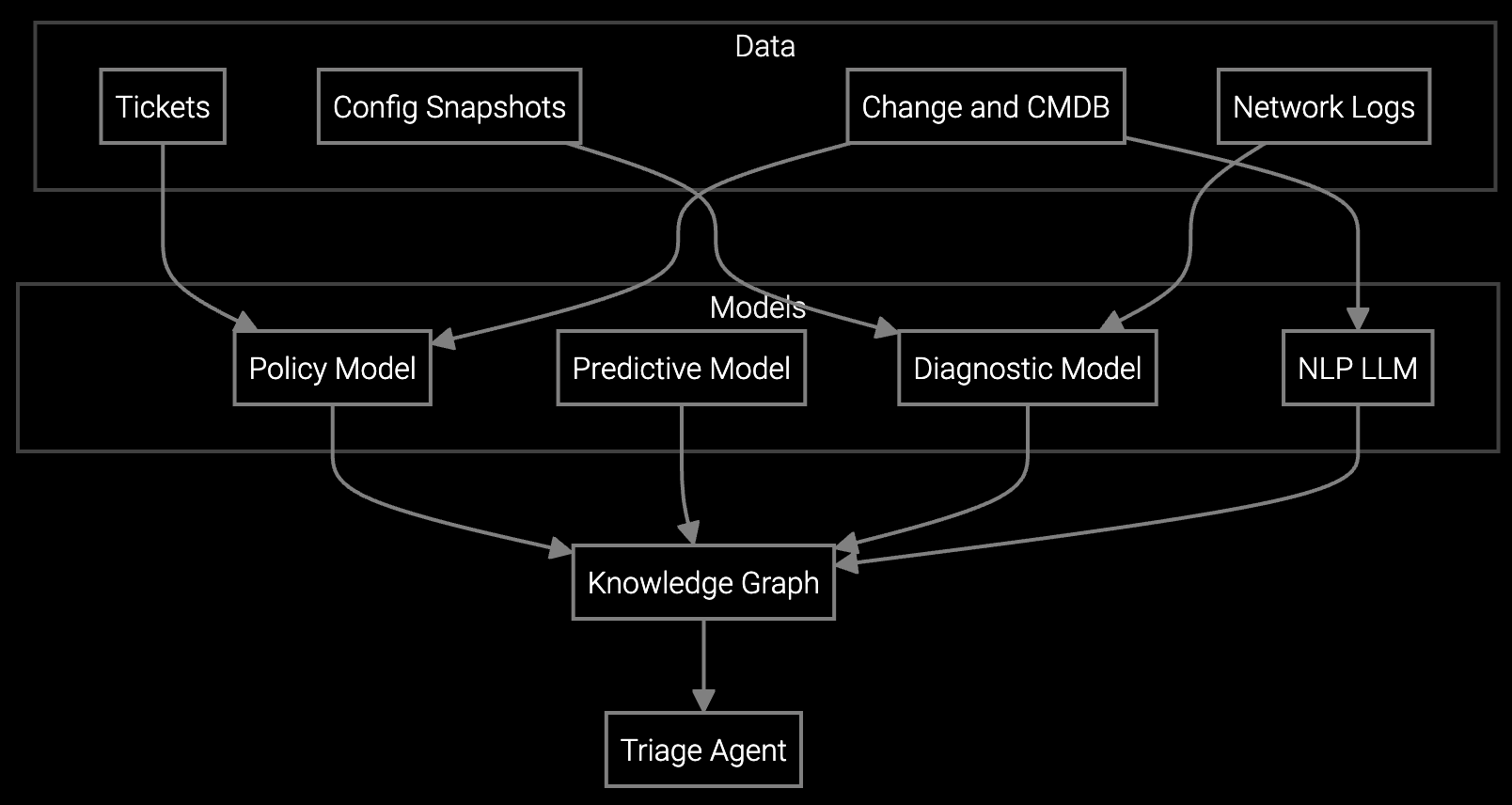
Bruviti's platform ingests tool telemetry via Python SDKs and REST APIs, parsing chamber sensor data, recipe logs, and alarm histories in real time. Machine learning models trained on historical incident data identify root cause patterns—matching current symptoms to known failure modes without human log reading. Support engineers receive ranked diagnostics with confidence scores and suggested troubleshooting steps.
This cuts session duration by automating the most time-intensive phase: correlation and pattern matching across thousands of log entries. Escalations drop because engineers get actionable guidance before connectivity or visibility constraints force handoff. Integration with existing remote access tools means no platform migration—your stack stays intact, augmented by AI inference endpoints.
Semiconductor tools generate multi-layered telemetry: chamber pressure, RF power, gas flow, wafer temperature, recipe parameters. Remote diagnosis requires correlating these streams with alarm codes, maintenance logs, and process history. Standard remote access tools provide screen sharing—they don't parse this data.
Bruviti APIs ingest SECS/GEM data, equipment logs, and recipe files, applying pattern recognition to identify drift, contamination, or component degradation. Support engineers see root cause hypotheses ranked by probability—eliminating manual log sifting. For EUV lithography or etch tools where downtime costs exceed $1M per hour, 30 minutes saved per incident translates to $500K per downtime event avoided.
Focus on remote resolution rate, escalation rate to field service, and average session duration. Secondary metrics include time-to-diagnosis and knowledge base utilization rate. Track these monthly and compare pre/post implementation. Expect measurable improvements within 90 days—if you're not seeing movement, integration or model training needs adjustment.
Session duration improvements appear within 30-60 days once telemetry ingestion is live. Escalation reduction follows at 60-90 days as support engineers trust AI guidance. Full ROI realization—including reduced field service costs and faster new hire ramp—typically occurs at 6-9 months. The timeline depends on integration scope and historical data volume for model training.
Python and TypeScript SDKs support SECS/GEM, FDC, and standard syslog formats. Initial integration takes 2-4 weeks for a single tool type—parsing alarm codes, correlating recipe parameters, and mapping sensor streams. Once one tool family is integrated, similar tools follow faster. REST API endpoints return structured diagnostics, so your existing remote support UI can consume results without rebuilding.
Bruviti operates as an inference layer—your telemetry data stays in your infrastructure, models run via API calls, and diagnostics return as JSON. No proprietary data schemas, no forced migration of your remote access tools. If you stop using the platform, your data pipelines remain intact. This is headless AI: you control the stack, we provide the intelligence endpoints.
Yes. The platform supports fine-tuning on your historical incident data, recipe logs, and sensor patterns. You retain ownership of trained models and can export weights if needed. Custom model training typically requires 500+ labeled incidents per tool type for accuracy—but pre-trained models provide value immediately while custom training progresses.

Software stocks lost nearly $1 trillion in value despite strong quarters. AI represents a paradigm shift, not an incremental software improvement.

Function-scoped AI improves local efficiency but workflow-native AI changes cost-to-serve. The P&L impact lives in the workflow itself.
Five key shifts from deploying nearly 100 enterprise AI workflow solutions and the GTM changes required to win in 2026.
Review API integration requirements and calculate savings based on your incident volume.
Talk to an Engineer