Hyperscale operators demand 99.99% uptime—every unresolved remote session escalates into a costly emergency dispatch and SLA penalty.
Bruviti deployment data shows AI remote support cuts parts returns 12 to 18% by confirming the right diagnosis before a part ships. For data center OEMs, fewer no-fault-found returns means lower reverse-logistics cost and reclaimed inventory. Builders capture this by gating part dispatch behind a validated remote diagnosis instead of a technician guess.
Support engineers spend hours parsing IPMI logs and BMC sensor data across thousands of servers, delaying diagnosis and increasing session duration. Pattern recognition is manual, inconsistent, and cannot scale to hyperscale volume.
Solutions discovered during remote sessions are documented inconsistently or not at all. Support engineers repeatedly solve the same thermal anomalies, power distribution issues, and firmware conflicts without reusable knowledge capture.
First-line support engineers lack access to historical failure patterns and configuration drift analysis, leading to unnecessary escalations to senior engineers or product teams. Each escalation adds delay and labor cost.
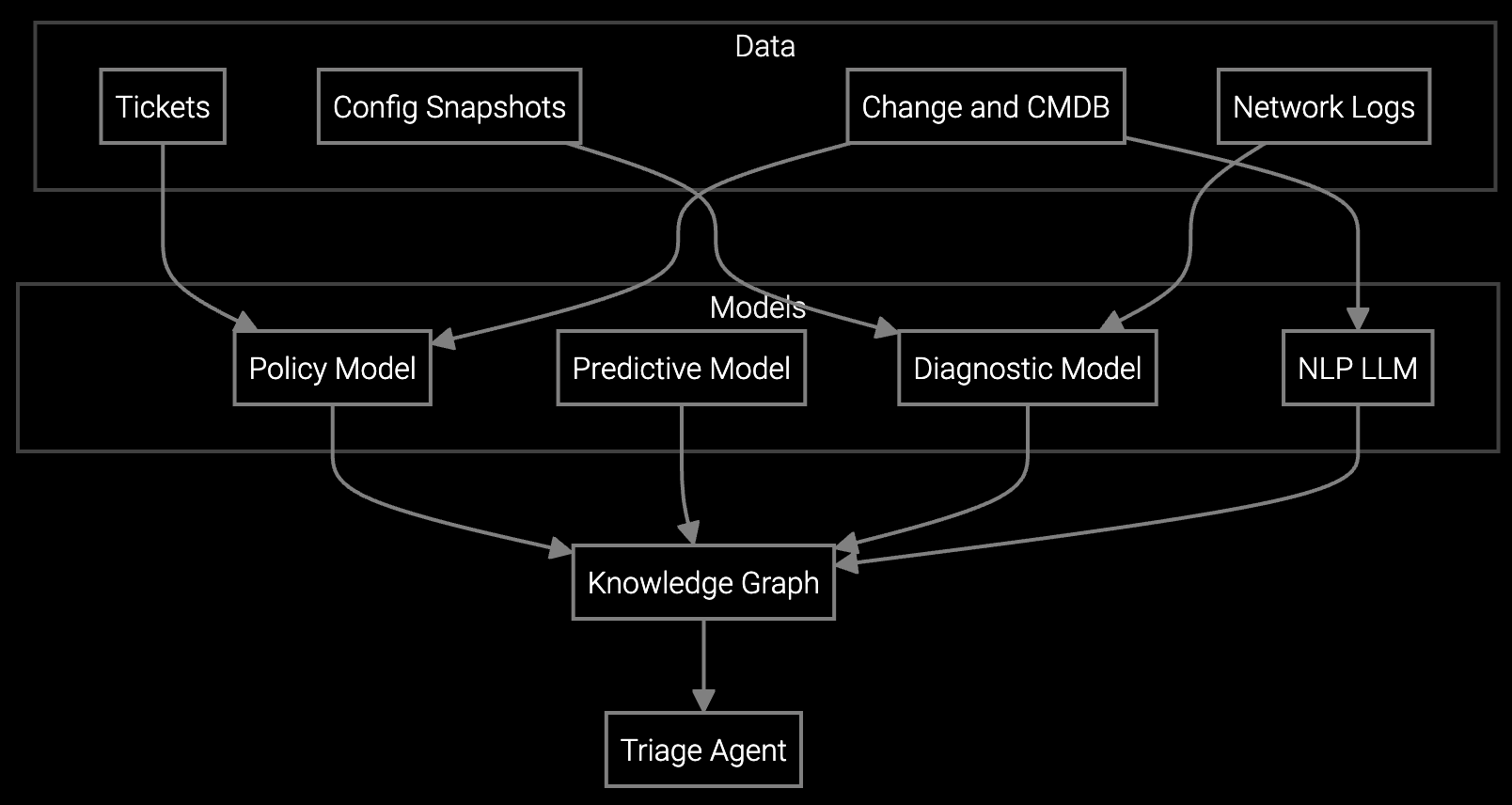
Bruviti's platform ingests BMC telemetry, IPMI logs, and configuration data via API to execute automated root cause analysis during remote sessions. Support engineers query the system in natural language—"Why is rack 42 thermal throttling?"—and receive diagnostic results correlating sensor data, firmware versions, and historical failure patterns across your installed base.
The platform integrates with your existing remote access tools (TeamViewer, LogMeIn, SSH) and ticketing systems to auto-populate case notes with diagnostic findings, resolution steps, and knowledge base article candidates. Python and TypeScript SDKs allow you to customize telemetry parsing logic, define escalation rules, and export session data for your own analytics pipelines without vendor lock-in.
Data center OEMs support thousands to millions of servers across geographically distributed facilities, where rapid provisioning and four-nines availability targets leave no room for prolonged remote sessions. AI-driven telemetry analysis parses BMC sensor streams, RAID controller logs, and IPMI event data in real time, identifying thermal hot spots, impending drive failures, and power distribution anomalies before they trigger customer escalations.
For data center customers managing mixed hardware generations—legacy PDUs alongside modern liquid-cooled racks—the platform normalizes telemetry formats and correlates events across vendors, accelerating root cause identification. Support engineers gain instant visibility into configuration drift (firmware mismatches, BIOS settings) that typically require manual audits, cutting session duration and improving first-contact resolution.
Baseline your current first-session resolution rate (percentage of cases closed without escalation or follow-up) and mean time to resolution across your support tiers. After deployment, measure the same metrics at 30, 60, and 90 days. ROI is calculated from reduced escalation labor costs, faster MTTR reducing SLA penalties, and improved support engineer productivity (cases closed per hour).
Start with BMC/IPMI feeds for server health, PDU power logs, and cooling system sensor data. The platform also ingests RAID controller logs, firmware version databases, and historical failure records. Python SDKs allow you to add custom telemetry parsers for proprietary sensors or legacy equipment without vendor dependencies.
Yes. Use TypeScript or Python SDKs to define escalation thresholds (e.g., escalate if thermal anomaly persists >15 minutes), create custom diagnostic queries, and route findings to your existing ticketing system. API-first architecture means you control the logic and data flows—no black box decisions.
Automated log analysis and pattern matching allow first-line support engineers to resolve issues previously requiring escalation to senior engineers or product specialists. Fewer escalations mean lower labor costs per case, shorter resolution times, and reduced SLA penalty exposure. At hyperscale volumes, a 10-point improvement in first-session resolution saves millions annually.
Most data center OEMs see positive ROI within 6-9 months, driven by reduced escalation labor costs, improved SLA performance, and faster resolution of high-severity incidents. Hyperscale customers with >10,000 servers often achieve payback in 4-6 months due to volume leverage and the high cost of emergency responses.

Software stocks lost nearly $1 trillion in value despite strong quarters. AI represents a paradigm shift, not an incremental software improvement.

Function-scoped AI improves local efficiency but workflow-native AI changes cost-to-serve. The P&L impact lives in the workflow itself.
Five key shifts from deploying nearly 100 enterprise AI workflow solutions and the GTM changes required to win in 2026.
See how API-first remote diagnostics reduce escalation costs and improve MTTR for your data center customers.
Schedule Technical Demo