Hyperscale customers demand sub-hour response times, but legacy ticketing systems can't keep pace with multi-vendor infrastructure complexity.
Bruviti deployment data shows AI email automation saves more than 300 agent hours per week while holding under 2 minute median handling time. For builders sizing ROI, that recovered capacity is the core return, redirecting agents from repetitive replies toward high-value data center support work.
Agents spend 3-5 minutes per case manually tagging equipment type, symptom category, and urgency level. High-volume OEMs handle 50K+ monthly cases, making triage time a significant cost driver that delays SLA clock starts.
Server, storage, and cooling systems each have separate knowledge bases. Agents toggling between BMC logs, firmware docs, and thermal reports lose 6-8 minutes per case searching for relevant troubleshooting steps.
Inconsistent answers across agent shifts cause 28-35% of hyperscale customers to reopen cases. Each repeat contact doubles handling cost and erodes SLA compliance, especially for four-nines availability contracts.
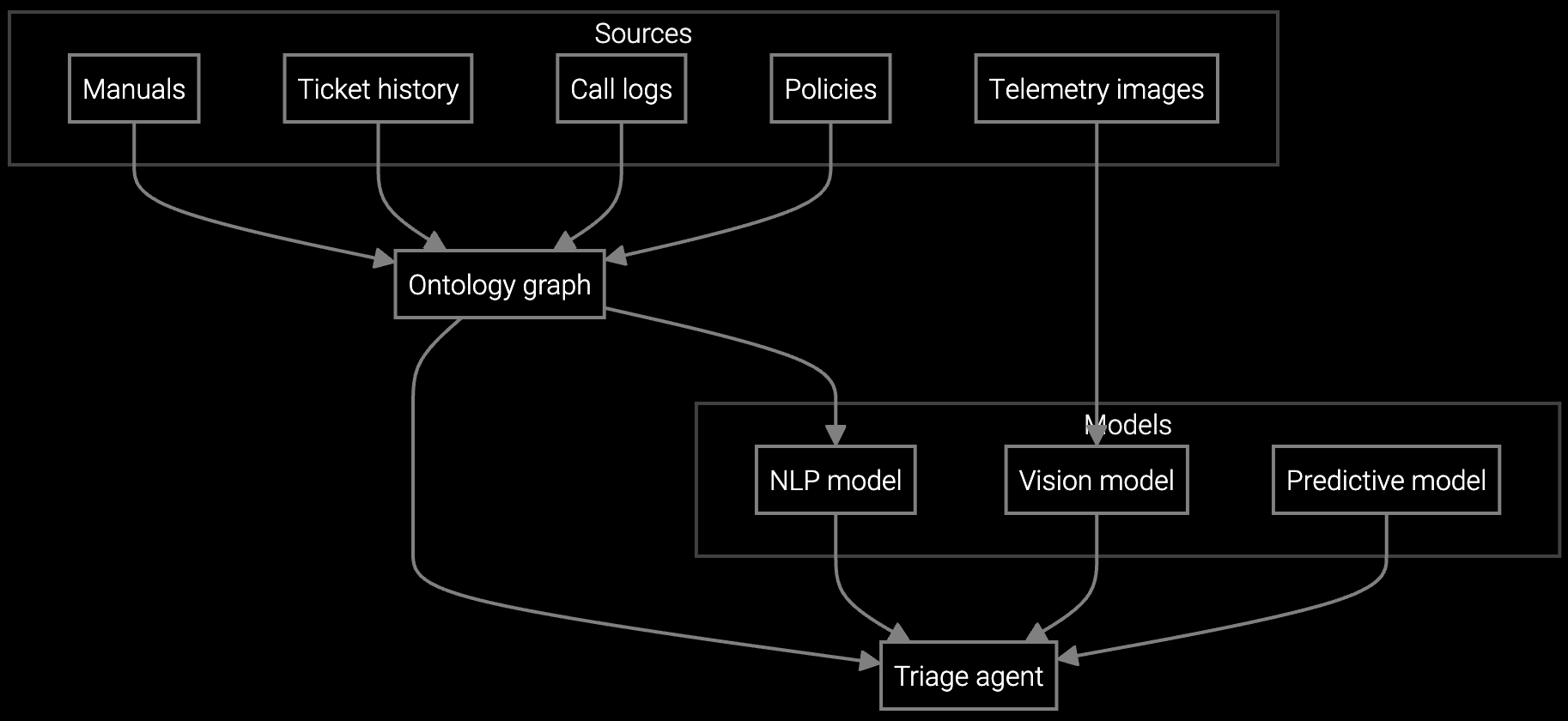
Bruviti's platform exposes REST APIs for case ingestion, classification, and knowledge retrieval. Your developers connect existing CRM systems (Salesforce Service Cloud, Zendesk, custom ticketing) using Python or TypeScript SDKs. The platform reads case descriptions, correlates BMC/IPMI telemetry, and returns diagnostic context in JSON—no black-box UI required.
Classification models train on your historical case data (ticket descriptions, resolution notes, equipment SKUs). You control model retraining schedules via API, avoiding vendor lock-in. Knowledge retrieval pulls from your existing documentation sources (Confluence, GitHub wikis, internal PDFs) using vector embeddings. The architecture is headless—your contact center UI stays unchanged while backend intelligence improves routing speed and agent answer accuracy.
Correlates BMC error logs with thermal sensor readings to route server failures to compute specialists versus cooling teams, cutting misrouting by 40%.
Parses customer emails describing RAID rebuild failures, auto-classifies severity, and drafts responses with relevant KB articles—reducing tier-1 email AHT by 35%.
Generates case summaries from multi-day email threads involving UPS firmware updates, so escalation engineers understand context in 30 seconds instead of 8 minutes.
Data center OEMs supporting hyperscale operators face unique cost pressures. A single hyperscaler may deploy 100K+ servers per quarter, each generating BMC telemetry, firmware alerts, and thermal warnings. Contact centers handling this volume see 60K+ monthly cases spanning compute, storage, power, and cooling failures. Manual classification burns 4-5 FTE hours daily just tagging cases correctly.
Knowledge retrieval compounds costs because agents support multi-vendor environments—Dell servers, NetApp storage, APC UPS units. Searching across fragmented documentation adds 6-8 minutes per case. When agents give inconsistent answers about PUE optimization or hot-aisle containment best practices, 30% of cases reopen, doubling handling costs. For OEMs with $45-60 average cost per contact, repeat interactions destroy margin on maintenance contracts.
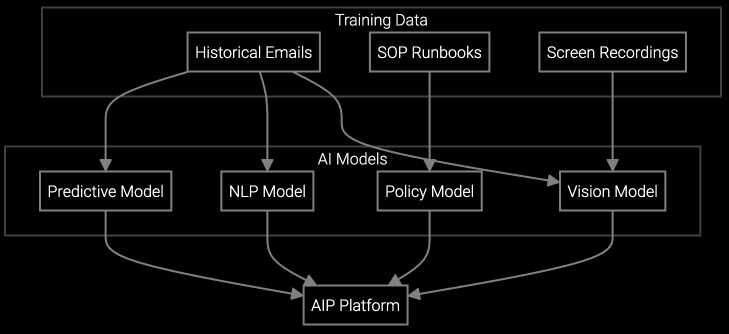
Bruviti provides REST APIs and Python/TypeScript SDKs for CRM integration. Typical implementation runs 4-6 weeks for Salesforce Service Cloud or Zendesk, including model training on historical case data. You control API endpoints and authentication, avoiding proprietary connectors that create vendor lock-in.
Classification models train on your case history, learning to distinguish server failures from cooling issues or power distribution faults. For multi-vendor environments (Dell servers, NetApp storage, APC UPS), the model correlates equipment SKUs with symptom keywords. You can retrain models via API as product lines evolve.
ROI calculations depend on case volume and current cost per contact. OEMs handling 50K+ monthly cases typically recover integration costs in 6-9 months through AHT reduction (25-35% improvement) and FCR gains (15-22 point improvement). Cost per contact drops $8-14 per case once classification and knowledge retrieval APIs are live.
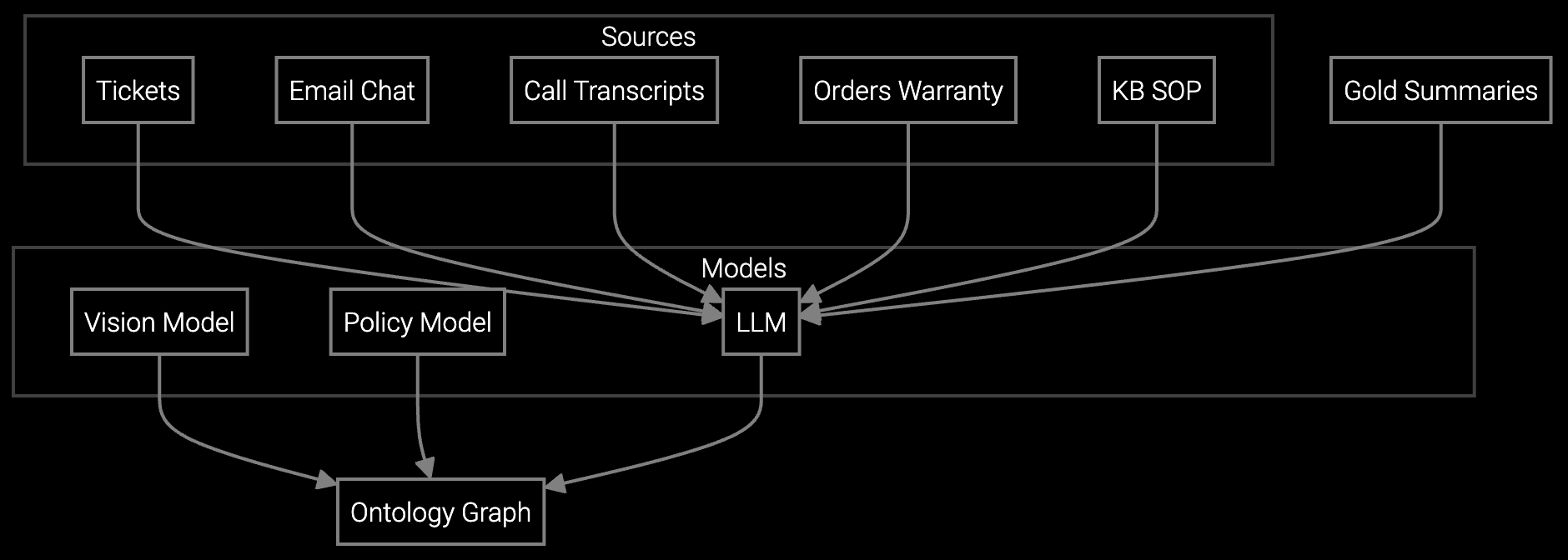
Yes. Knowledge retrieval APIs accept custom document sources (Confluence wikis, GitHub repos, internal PDFs). You configure retrieval ranking via API parameters, prioritizing internal runbooks over generic vendor docs. Vector embeddings update automatically when you add new documentation, maintaining answer accuracy without manual reindexing.
Bruviti's architecture is API-first and headless. Your developers own case routing logic, model retraining schedules, and knowledge source configuration. All integrations use standard REST APIs and open SDKs (Python, TypeScript). No proprietary UI or closed data formats—you can migrate models or export training data at any time.

Understanding and optimizing the issue resolution curve.

Part 1: The transformation of IT support with AI.

Part 2: Implementing AI in IT support.
Talk to our team about API integration timelines and cost per contact modeling for your case volume.
Schedule Technical Demo