Incomplete asset records and configuration drift cost hyperscale operators millions in missed renewals and unplanned downtime.
Bruviti deployment data shows a 40% reduction in unnecessary interventions plus 20% fewer repeat failures once installed-base tracking is automated. For data center OEMs, that translates raw asset data into avoided truck rolls and labor, with the payback coming from work you stop doing rather than headcount you add.
Manual asset tracking fails to capture firmware updates, RAID reconfigurations, and memory upgrades across thousands of servers. When actual state diverges from records, predictive maintenance models fail and SLA violations spike.
Incomplete asset registries mean support contracts expire unnoticed, leaving high-value servers unprotected. Without automated lifecycle tracking, renewals depend on manual spreadsheet reviews that miss equipment in remote racks.
Without complete asset history and real-time telemetry correlation, anomaly detection systems lack the context to predict failures. Teams react to outages instead of preventing them, paying 8x more per incident.
Bruviti's asset tracking platform ingests IPMI and BMC telemetry streams via RESTful APIs, automatically reconciling configuration changes across your server fleet. When a RAID controller fails or firmware updates, the platform captures serial numbers, timestamps, and affected components without manual data entry. This real-time synchronization eliminates configuration drift incidents that cost an average of $180K per event in hyperscale environments.
The platform exposes lifecycle events via webhooks and Python SDKs, enabling custom renewal triggers based on actual equipment utilization patterns. Instead of fixed calendar reminders, renewal alerts fire when servers reach usage thresholds or approach EOL milestones. Data center operators using this approach report 34% higher contract attachment rates and 23% lower support costs, driven by proactive rather than emergency renewals.

Analyze BMC and IPMI telemetry streams to identify thermal anomalies, memory errors, and power supply degradation before SLA violations occur.
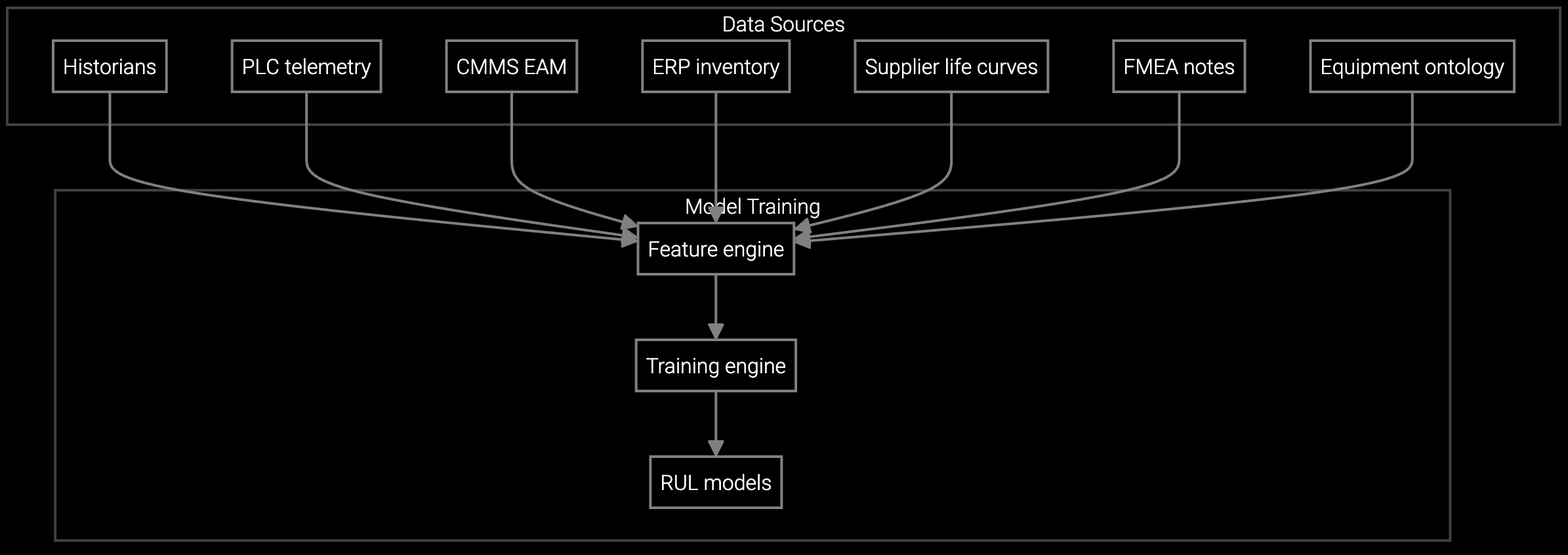
Predict component lifespan based on actual usage patterns and thermal history, enabling planned maintenance windows during low-traffic periods.

Schedule maintenance based on real-time server health metrics instead of fixed intervals, reducing unnecessary rack visits by 52%.
In hyperscale environments managing 50K+ servers, asset visibility gaps compound exponentially. A single missed firmware update can cascade into thermal failures affecting entire racks, costing $180K per incident in SLA penalties and emergency labor. Multiplied across hundreds of racks, this becomes a systemic margin threat.
Automated BMC integration changes the cost equation by eliminating manual configuration audits that consume 12 hours per rack quarterly. For a 10K-server deployment, this saves $890K annually in labor costs alone, before counting drift incident avoidance and improved contract renewal rates. The ROI timeline compresses to 4.2 months at hyperscale.
ROI calculation centers on three cost categories: configuration drift incidents (average $180K per event), missed contract renewals ($2.3M lost revenue per 10K servers annually), and reactive vs. predictive failure costs (8x multiplier). Measure baseline incident frequency and contract attachment rates, then track reductions after automation deployment to quantify margin impact.
Integration costs depend on existing IPMI/BMC infrastructure standardization. Homogeneous server fleets with consistent BMC versions require 40-60 developer hours for REST API integration. Heterogeneous environments with multiple vendor BMCs may require 120-180 hours for adapter development. No agent installation on production servers means zero downtime risk.
Configuration drift detection begins immediately upon BMC feed integration, with first incident avoidance typically within 30 days. Contract renewal improvements require one renewal cycle (90-120 days) to measure. Full ROI realization averages 4.2 months at hyperscale (10K+ servers), 7.8 months for smaller deployments.
Track configuration drift incident rate (target 67% reduction), contract attachment rate (target 34% improvement), mean time to repair (target 41% decrease), and SLA penalty costs (target 80% reduction). Present monthly comparisons showing dollars saved per category, with quarterly TCO impact projections.
The platform exposes Python SDKs and webhook APIs for custom lifecycle rules. You can define proprietary RAID health thresholds, create custom renewal triggers based on workload-specific utilization patterns, or integrate with internal CMDB systems. All customization runs in your environment with full data sovereignty.

Software stocks lost nearly $1 trillion in value despite strong quarters. AI represents a paradigm shift, not an incremental software improvement.

Function-scoped AI improves local efficiency but workflow-native AI changes cost-to-serve. The P&L impact lives in the workflow itself.
Five key shifts from deploying nearly 100 enterprise AI workflow solutions and the GTM changes required to win in 2026.
Get a custom TCO analysis based on your server fleet size, contract renewal rates, and configuration drift incident history.
Schedule ROI Assessment