Incomplete asset data and configuration drift are costing you renewal revenue and creating unplanned service costs at scale.
Bruviti deployment data shows service resolution time cut by 50% and time to root cause down 65% with AI-driven asset lifecycle management. For data center OEMs, faster resolution converts directly into lower service cost per asset and higher contract margin, with returns grounded in fielded deployments, not models.
Missing serial numbers, outdated firmware versions, and incomplete configuration data prevent proactive service and create blind spots across your deployed base. When you can't identify what's in the field, you can't predict failures or plan capacity upgrades.
Actual equipment configurations diverge from recorded state as customers modify BIOS settings, firmware versions, and RAID configurations without notification. This drift creates service failures, longer diagnostic times, and missed SLA commitments.
Without visibility into equipment age, usage patterns, and EOL timelines, sales teams miss upsell windows and contract renewals expire unnoticed. The result is lost recurring revenue and customer churn to competitors who engage proactively.
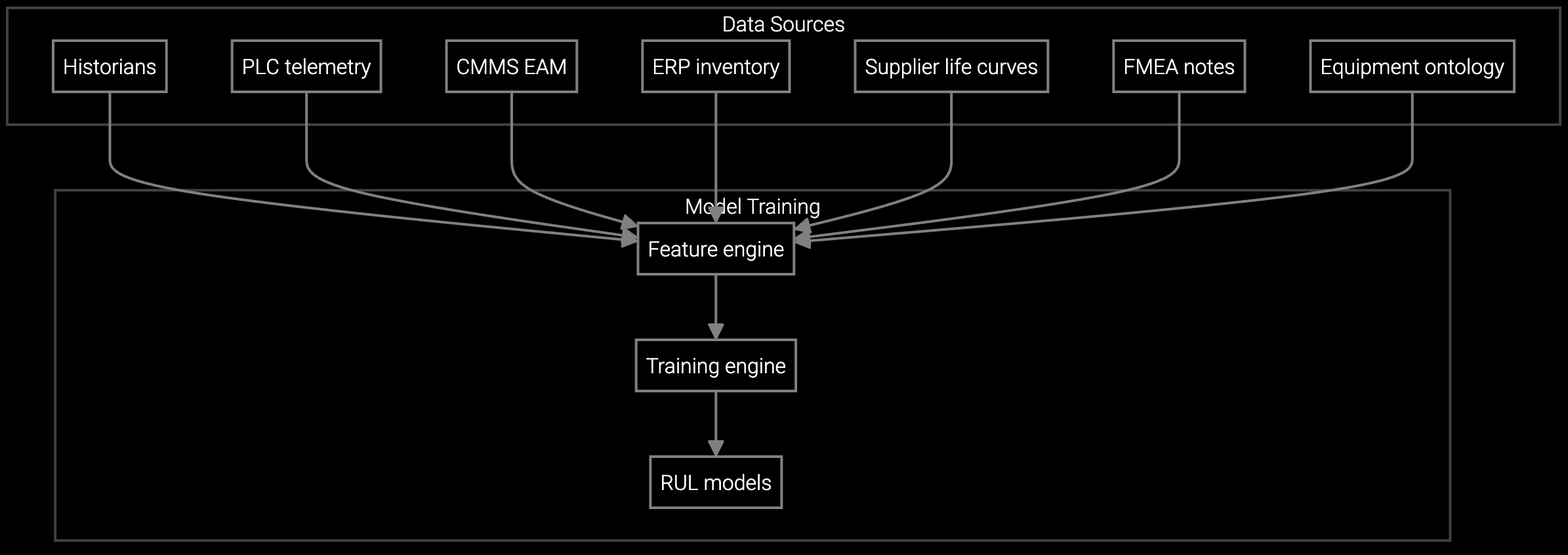
Bruviti's platform ingests BMC telemetry, IPMI data feeds, and service history to build a continuously updated digital representation of every deployed server, storage array, and infrastructure component. The AI correlates serial numbers with configuration states, tracks firmware versions across millions of nodes, and identifies assets approaching EOL or requiring proactive intervention.
This automated asset intelligence eliminates manual tracking overhead while surfacing high-value opportunities—contract renewals coming due, upgrade candidates based on usage patterns, and predictive maintenance windows that prevent unplanned downtime. The platform transforms installed base data from a compliance burden into a strategic revenue driver.

Virtual models of deployed data center equipment track real-time performance against baseline, enabling proactive intervention before thermal or power anomalies cause failures.
AI analyzes drive SMART data, memory ECC events, and power supply metrics to estimate when components will fail, enabling planned maintenance during customer-approved windows.

Maintenance schedules shift from fixed intervals to condition-based triggers, reducing unnecessary service visits while preventing unplanned downtime through early intervention.
Data center OEMs generate massive telemetry volumes—BMC heartbeats, IPMI sensor readings, firmware update logs—but lack the infrastructure to extract lifecycle intelligence at scale. A single hyperscale customer may deploy 50,000+ nodes across multiple sites, each with unique RAID configurations, CPU generations, and memory densities. Manual tracking fails beyond 5,000 assets.
The platform ingests these telemetry streams continuously, correlating hardware identifiers with service histories and contract status. When a customer's storage arrays show elevated read latency patterns typical of drive degradation, the system alerts account teams to propose proactive drive refresh—turning potential downtime into an upsell opportunity. Configuration drift detection prevents the "it worked last week" failures that damage OEM credibility and trigger SLA penalties.
AI continuously monitors usage patterns, firmware update frequency, and service ticket volume to identify accounts with high engagement—these signal renewal likelihood. The platform flags expiring contracts 90 days out and prioritizes outreach based on predicted lifetime value. Manual tracking relies on static renewal dates and misses behavioral signals that indicate upsell readiness or churn risk.
The platform ingests BMC/IPMI data feeds, firmware update logs, service ticket systems, and warranty databases. For data center OEMs, this includes server node telemetry, storage array health metrics, and power/thermal sensor readings. Integration typically starts with existing telemetry infrastructure—no new hardware deployment required on customer sites.
Initial value appears within 60-90 days as the platform identifies incomplete asset records and high-priority renewal opportunities. Full ROI—including configuration drift reduction and proactive failure prevention—typically materializes over 12-18 months as the AI learns failure patterns across your installed base. Data center OEMs with 20K+ deployed assets often justify investment within the first year through renewal rate lift alone.
Yes, if customers grant telemetry access through BMC interfaces or phone-home mechanisms already embedded in your equipment. Many data center operators willingly share this data when it improves proactive support quality. The platform can also infer asset status from service interactions and warranty claims when direct telemetry isn't available, though accuracy is lower.
Manual tracking typically breaks down above 5,000 deployed assets when configuration diversity and geographic distribution exceed spreadsheet capacity. AI economics improve with scale—10K assets justify platform investment through renewal lift alone, while 50K+ assets unlock additional value from predictive maintenance and capacity planning intelligence. Smaller OEMs may start with high-value accounts where contract sizes justify AI investment.

Software stocks lost nearly $1 trillion in value despite strong quarters. AI represents a paradigm shift, not an incremental software improvement.

Function-scoped AI improves local efficiency but workflow-native AI changes cost-to-serve. The P&L impact lives in the workflow itself.
Five key shifts from deploying nearly 100 enterprise AI workflow solutions and the GTM changes required to win in 2026.
See how data center OEMs are using AI to improve renewal rates and eliminate configuration blind spots.
Schedule ROI Assessment