Service margins erode when technicians make repeat visits for preventable failures—hyperscale operators demand four-nines uptime.
Bruviti deployment data shows AI reduces call volume by 35% and average handling time by 22% for data center OEM service operations. Executives see ROI in deflected support cost and reclaimed technician capacity, with first-time fix gains compounding the savings across the install base.
Technicians arrive on-site without the right parts for server, storage, or PDU failures. A second truck roll doubles labor costs and triggers SLA penalties when customer uptime guarantees are missed.
Senior technicians who diagnose thermal anomalies, BMC failures, and RAID controller issues are retiring. Their pattern recognition—what drive failures look like before they show in SMART data—walks out with them.
Hyperscale customers negotiate strict uptime targets with financial penalties. When technicians can't restore a failed cooling unit or storage array fast enough, the OEM pays liquidated damages that compress already-thin service margins.
Bruviti ingests BMC telemetry, IPMI logs, and environmental sensor data from deployed equipment to predict component failures before dispatch. The platform correlates thermal drift patterns, power supply voltage fluctuations, and memory error rates with historical field service outcomes—identifying which parts technicians will need on-site.
When a server reports elevated CPU temperatures, the AI cross-references RAID controller behavior, fan RPM trends, and past repairs to determine if the root cause is a failing cooling module, clogged airflow, or a defective BMC. Technicians arrive with pre-staged parts matched to predicted failure modes, eliminating guesswork that triggers repeat visits. The platform captures expert diagnostic logic from retiring technicians, embedding their pattern recognition into automated triage workflows that protect first-time fix rates as workforce turnover accelerates.
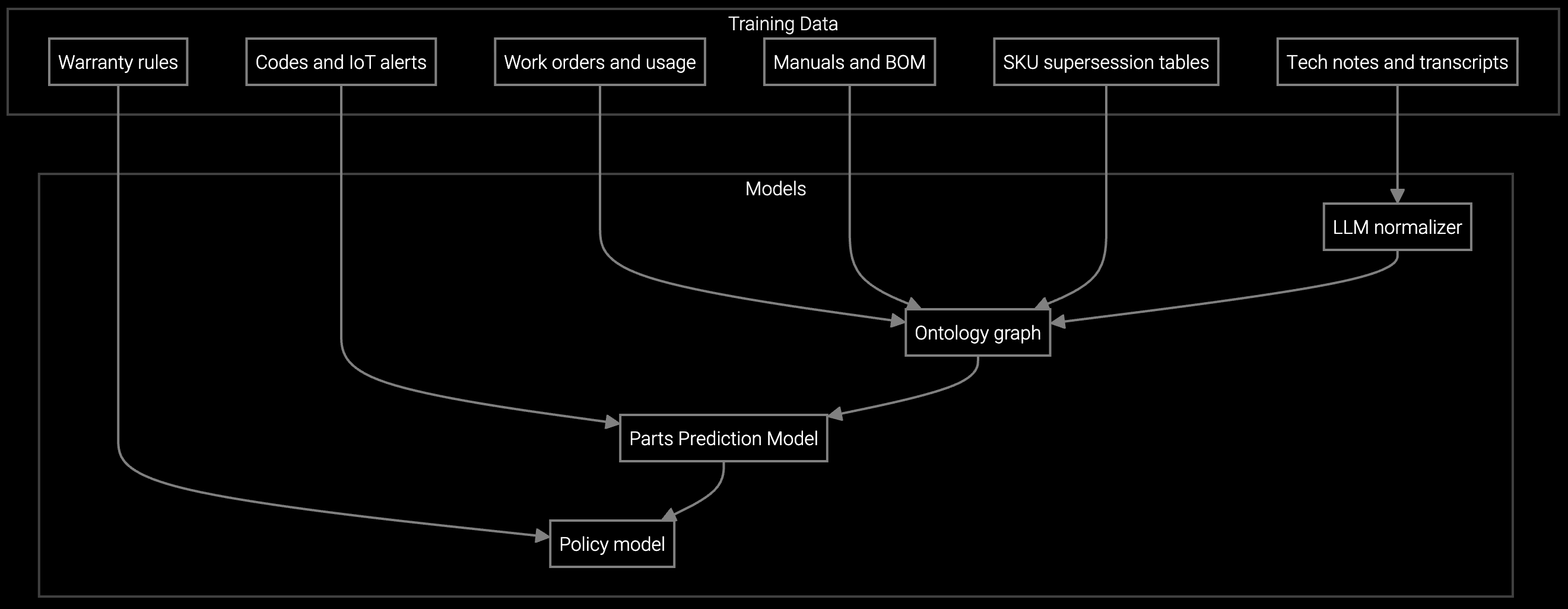
Predict which server components, storage drives, and cooling modules technicians will need before dispatch—using BMC telemetry and historical failure patterns to pre-stage parts and eliminate repeat visits.
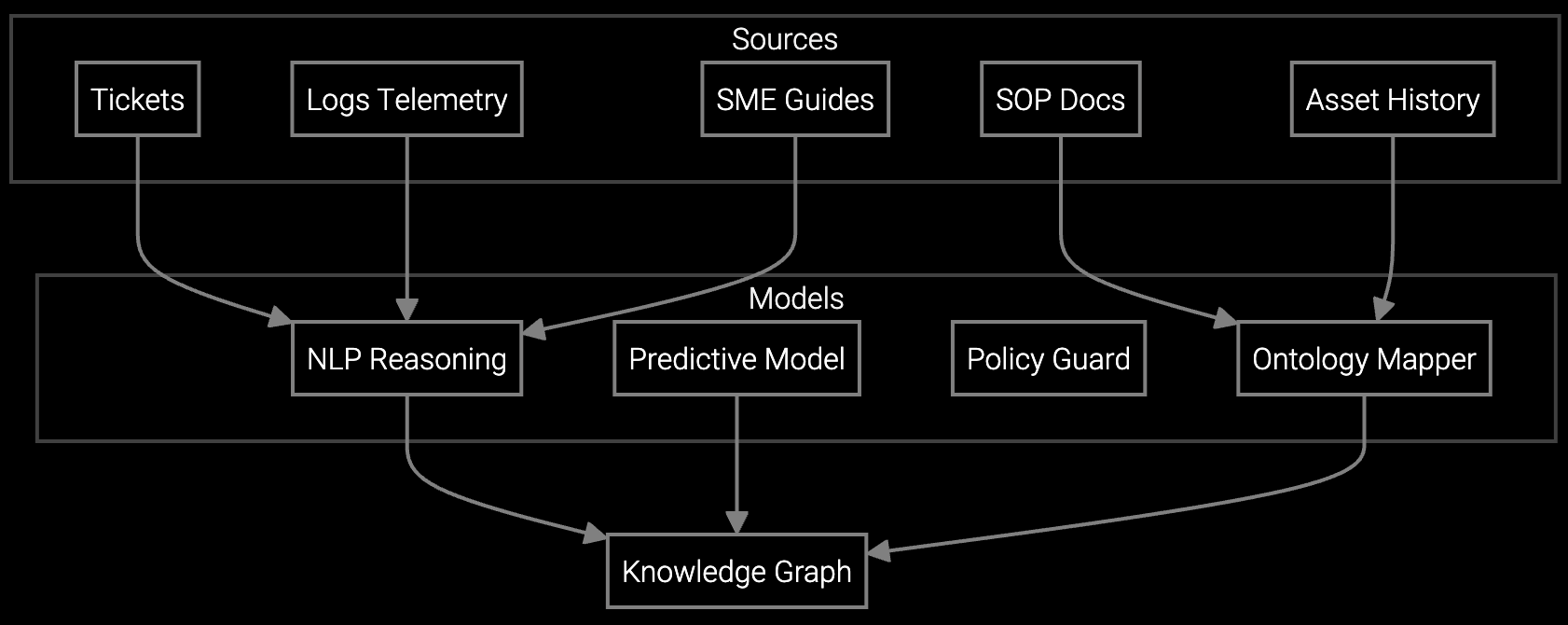
Correlate thermal anomalies, RAID controller errors, and power supply voltage drift with tribal knowledge from retiring technicians to pinpoint root causes faster than manual diagnostics.
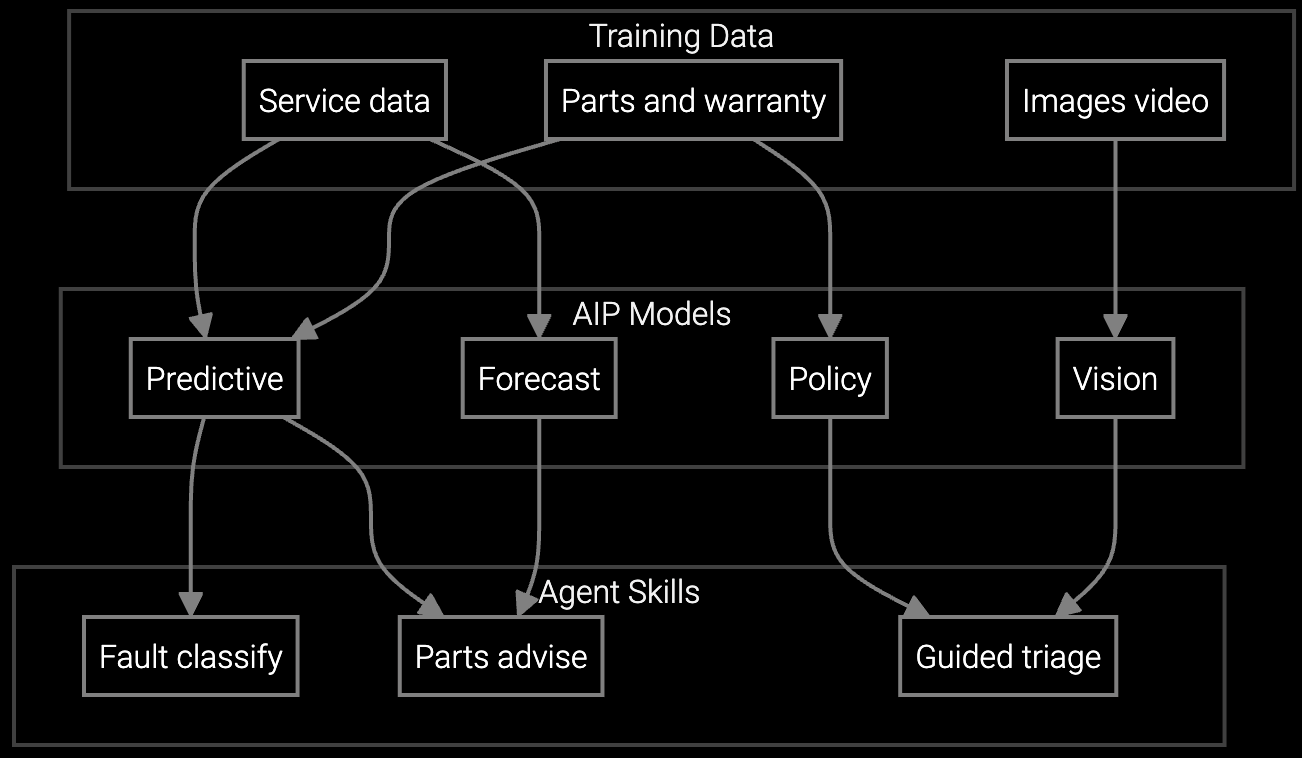
Deliver real-time guidance on mobile devices when technicians encounter unexpected BMC failures or cooling anomalies—combining live sensor data with repair procedures to maintain first-time fix rates.
Hyperscale operators run millions of servers across geographically distributed facilities, demanding 99.99% uptime guarantees. When a PDU fails or a storage array degrades, the penalty clock starts immediately. OEMs absorb repeat visit costs when technicians misdiagnose thermal issues as fan failures when the root cause is a clogged cold aisle or failing BMC.
The highest-cost failures—power distribution units, UPS systems, and high-density compute nodes—require precise parts prediction. A technician dispatched without the correct RAID controller firmware version or replacement backplane wastes a $950 truck roll and triggers contractual penalties that can exceed $50,000 per incident for Tier IV facilities. As senior technicians retire, newer hires lack the pattern recognition to distinguish normal thermal variance from early-warning signs of catastrophic cooling failures.
Most OEMs observe 8-12% truck roll reduction within the first 90 days as the platform learns failure patterns from BMC telemetry and parts consumption history. First-time fix rates typically improve 6-10 percentage points in the initial quarter, with full ROI—including SLA penalty avoidance—materializing within 6-9 months as the AI refines predictive accuracy across diverse hardware configurations.
Track truck roll reduction percentage, first-time fix rate improvement, and SLA penalty avoidance as primary ROI indicators. Secondary metrics include technician utilization gains, mean time to repair reduction, and parts carrying cost optimization. CFOs should monitor the ratio of repeat visit costs to total service revenue—a 15-20% improvement in this ratio typically signals strong margin protection.
The platform analyzes BMC telemetry, IPMI logs, and thermal sensor data to predict which components will fail before dispatch. For server issues, it correlates memory error rates, CPU temperature trends, and RAID controller behavior to determine if the technician needs replacement DIMMs, cooling modules, or storage drives. This pre-staging eliminates the guesswork that causes 30-40% of repeat visits in reactive service models.
Yes, Bruviti integrates with major field service management platforms and ERP systems through APIs. The platform ingests work order data, parts inventory levels, and technician schedules to optimize dispatch decisions and ensure predicted parts are available before assignment. Integration typically takes 4-6 weeks for standard FSM systems and includes real-time synchronization of service outcomes to refine predictive models.
Without AI, first-time fix rates typically decline 12-18 percentage points as experienced technicians retire, eroding service margins through increased repeat visits and SLA penalties. The platform captures diagnostic logic from retiring experts by analyzing their historical repair decisions, parts selections, and root cause determinations—then embeds that pattern recognition into automated triage workflows. This preserves institutional knowledge and stabilizes ROI even as workforce composition changes.

How AI bridges the knowledge gap as experienced technicians retire.

Generative AI solutions for preserving institutional knowledge.

AI-powered parts prediction for higher FTFR.
See how Bruviti's AI platform can reduce truck rolls and protect service margins for your data center equipment portfolio.
Schedule ROI Analysis