Hyperscale operations demand four nines uptime—every minute of server downtime costs $9,000, making remote resolution speed a margin imperative.
Bruviti deployment data shows AI remote support cuts repeat truck rolls 38% and lifts first-time-fix 10 to 15 percentage points. For data center infrastructure, every avoided dispatch is direct margin: fewer onsite visits, faster restoration, lower service cost per asset. The savings compound across a large installed base of distributed equipment.
Support engineers spend 2-4 hours per complex server incident parsing IPMI logs, correlating thermal events with memory failures, and identifying root cause across thousands of telemetry data points. This manual effort delays resolution and increases total incident cost.
When support engineers lack confidence in remote diagnostics, they escalate to senior specialists or schedule hardware replacements that may not be needed. Each unnecessary escalation adds labor cost and extends customer downtime, impacting SLA compliance.
Different server generations, storage arrays, and cooling systems each have unique failure signatures. Knowledge stays trapped with individual engineers, forcing repeated learning cycles and inconsistent resolution quality across the support organization.
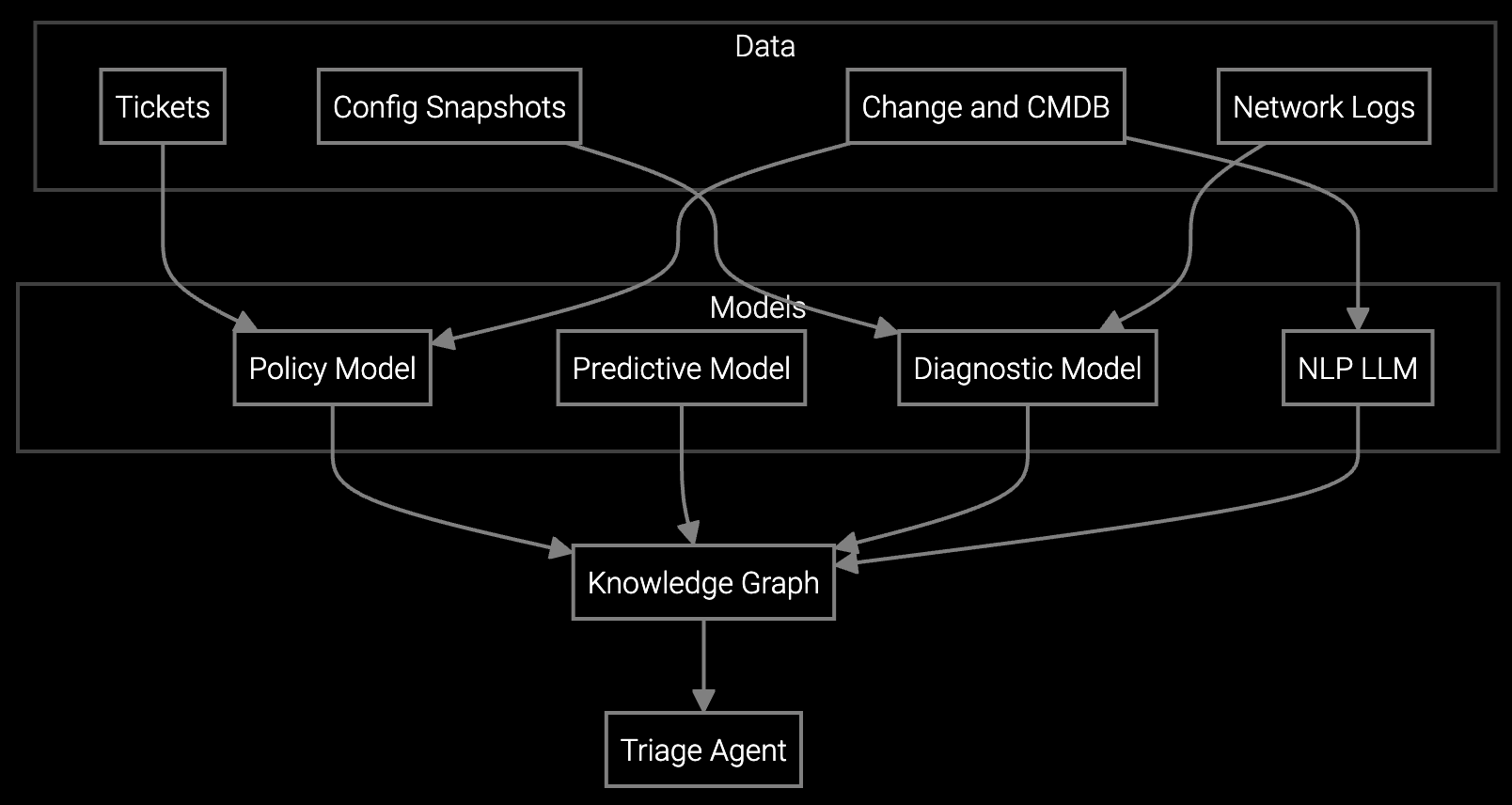
Bruviti's platform ingests telemetry from BMCs, IPMI interfaces, and data center monitoring systems to automate root cause analysis. The AI correlates thermal anomalies with component failures, identifies failure signatures across server generations, and provides support engineers with guided troubleshooting workflows that compress resolution time.
For data center OEMs, this eliminates the manual log analysis bottleneck that drives incident cost. The platform learns from every resolved case, capturing knowledge that would otherwise remain siloed with senior engineers. Each remote session generates structured documentation that improves future resolution speed across the entire support organization.
Hyperscale data center operators manage tens of thousands of servers across multiple generations and vendors. A single thermal hotspot can cascade into rack-level failures costing $140,000 per hour in lost compute capacity. Remote support teams must diagnose failures across heterogeneous infrastructure while maintaining 99.99% availability SLAs.
Traditional remote diagnostics rely on manual correlation of IPMI logs, BMC alerts, and environmental sensors. When engineers lack confidence in remote diagnosis, they default to hardware replacement, driving unnecessary RMA costs and extending customer downtime. This conservative approach protects uptime but erodes service margin through preventable part replacements.
The platform reduces three primary cost centers: labor cost per incident (by shortening session duration through automated analysis), escalation costs (by improving first-session resolution confidence), and indirect costs from knowledge silos (by standardizing resolution quality across junior and senior engineers). Typical deployments see 35-45% total cost reduction per incident within 90 days.
Remote resolution rate is calculated as incidents resolved without escalation divided by total incidents handled. Baseline for data center OEMs typically ranges from 55-65%. Post-deployment, organizations track this weekly, targeting 80%+ within six months. The metric directly correlates with support cost per incident and customer satisfaction scores.
You need three baseline metrics: average session duration per incident type, current remote resolution rate, and fully-loaded cost per support engineer hour. Most data center OEMs also track escalation rate and average time to resolution. These inputs enable accurate TCO modeling and establish measurable targets for platform impact assessment.
Initial session duration improvements appear within 30 days as engineers adopt guided workflows. Remote resolution rate improvements require 60-90 days as the AI learns from resolved incidents and builds confidence in diagnostic recommendations. Full ROI realization—including reduced escalations and standardized quality—typically occurs within six months of deployment.
Yes. The platform ingests standard IPMI and BMC protocols, which are consistent across vendors and generations. For proprietary telemetry formats, API connectors enable integration with vendor-specific monitoring tools. The AI learns failure patterns specific to each hardware configuration, improving diagnostic accuracy even across heterogeneous infrastructure.

Software stocks lost nearly $1 trillion in value despite strong quarters. AI represents a paradigm shift, not an incremental software improvement.

Function-scoped AI improves local efficiency but workflow-native AI changes cost-to-serve. The P&L impact lives in the workflow itself.
Five key shifts from deploying nearly 100 enterprise AI workflow solutions and the GTM changes required to win in 2026.
Work with our team to model specific ROI based on your current incident volume, escalation rate, and support cost structure.
Schedule ROI Analysis