Hyperscale operations demand instant resolution at massive scale—vendor rigidity and custom fragility both fail.
Bruviti deployment data shows remote support AI trained on ten years of service decisions delivers over 90% accuracy. For operators weighing build vs buy, that depth of history is the decider: a bought platform already carries the fault patterns your team would spend years collecting. Domain-trained beats generic on every fault you actually see.
Building in-house seems like control until you face integration delays, model retraining cycles, and maintenance burden. Your support engineers need answers today, not after a six-month ML sprint.
Off-the-shelf tools promise fast deployment but trap you in closed ecosystems. When you need to connect BMC telemetry or parse custom logs, you're stuck waiting for vendor roadmaps.
What works for 1,000 servers collapses at 100,000. Remote sessions multiply, log volumes explode, and your support engineers drown in fragmented tools that don't share context across sessions.
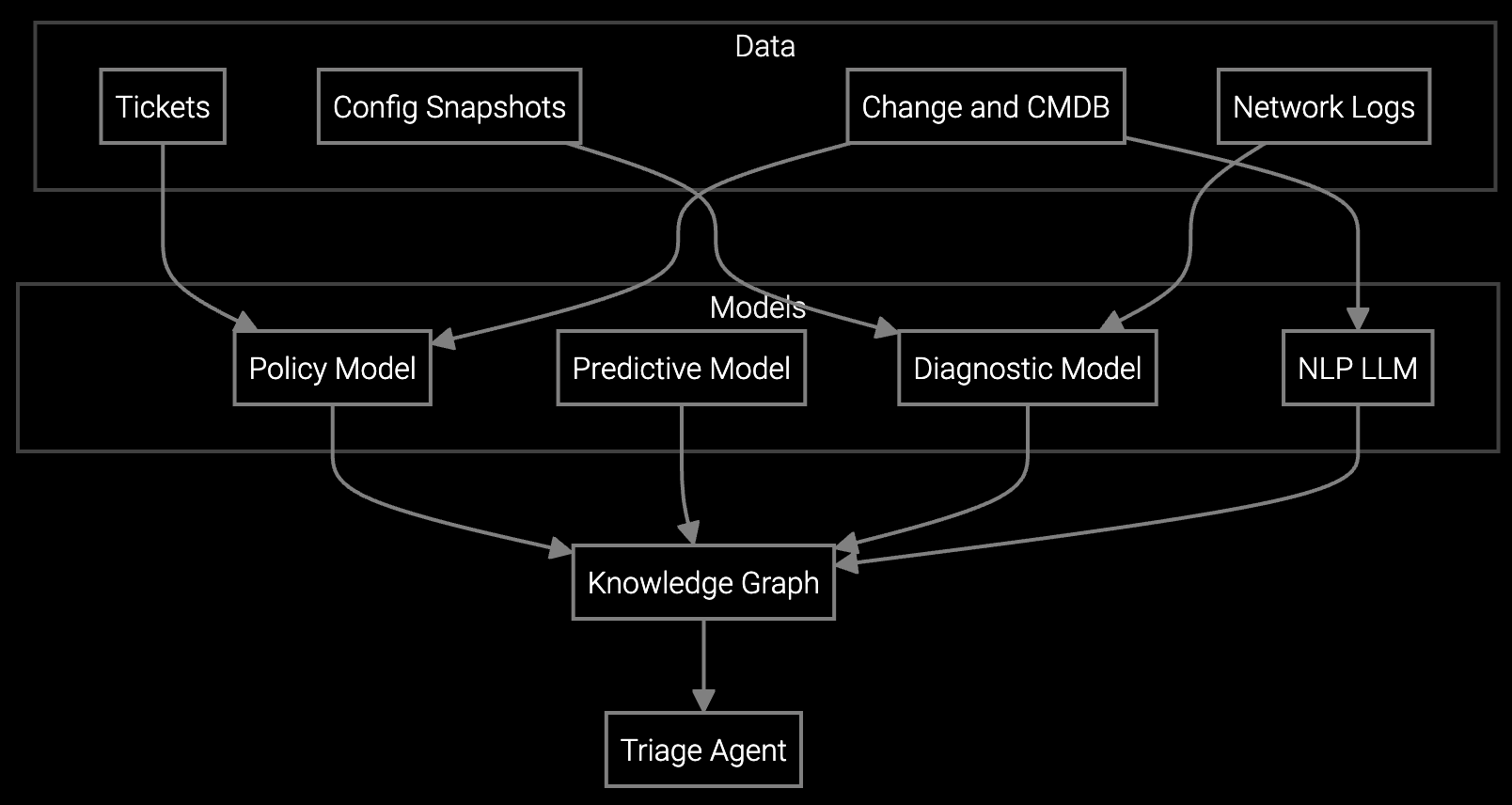
Bruviti combines fast deployment with deep customization. Support engineers get AI-powered root cause analysis on day one—parsing BMC telemetry, IPMI logs, and RAID events automatically. No manual log digging. No swivel-chair searches across five tools.
Simultaneously, your team extends the platform via APIs. Ingest custom telemetry streams, integrate with existing remote access tools, and build workflows specific to your hardware portfolio. The core intelligence scales across millions of servers while you control the integration points that differentiate your service delivery.
Start with your highest-volume failure modes—drive replacements, thermal alerts, or memory errors. These generate predictable log patterns and immediate ROI when automated. Use Bruviti's pre-built models to resolve these remotely within the first 60 days.
Next, extend to complex multi-system incidents. Integrate BMC telemetry, cooling system data, and power distribution logs into a unified diagnostic view. Your support engineers stop piecing together context from six tools—they get correlated root cause analysis automatically. This phase proves the platform scales beyond simple troubleshooting into orchestration-level intelligence.
Bruviti deploys in 4-6 weeks with immediate value—support engineers using AI diagnostics on real incidents. Custom builds typically take 9-12 months before production readiness, plus ongoing maintenance overhead. The platform approach delivers quick wins while preserving customization options through APIs.
API-first architecture means you control data ingestion. Connect custom BMC feeds, parse proprietary log formats, or integrate niche monitoring tools without waiting for vendor support. Pre-built connectors handle standard protocols (IPMI, SNMP), while SDKs let you extend for unique equipment.
The system is designed for hyperscale operations—processing telemetry streams from millions of devices without performance degradation. Distributed architecture ensures remote diagnostics remain fast even as your infrastructure grows. Support engineers see the same sub-second response times whether analyzing one rack or an entire data center region.
Yes. Most customers start with a single facility or specific hardware category to prove ROI before expanding. The platform supports multi-tenant configurations, so regional teams can operate independently while sharing core models. Gradual rollout minimizes disruption and allows iterative optimization.
Open APIs and standard data formats prevent lock-in. Your telemetry integrations, custom workflows, and diagnostic logic remain portable. Unlike closed vendor systems, you own the integration layer—switching costs stay low because you control the connection points between your infrastructure and AI capabilities.

Software stocks lost nearly $1 trillion in value despite strong quarters. AI represents a paradigm shift, not an incremental software improvement.

Function-scoped AI improves local efficiency but workflow-native AI changes cost-to-serve. The P&L impact lives in the workflow itself.
Five key shifts from deploying nearly 100 enterprise AI workflow solutions and the GTM changes required to win in 2026.
See how the platform approach delivers speed and flexibility for data center operations.
Talk to an Expert