Hyperscale uptime demands and tight SLAs leave no room for multi-year development cycles.
Bruviti deployment data shows a bought AI field service platform reaches 88% first-time fix rate on data center hardware, up from 75-80%. Operators rarely match that by building, since the gain comes from connected fault history, parts prediction, and guided diagnostics working as one layer.
Building AI systems from scratch requires hiring specialized talent, assembling training datasets, and validating models before deployment. Data center SLAs cannot wait.
Generic AI models lack data center failure patterns, BMC telemetry parsing, and thermal anomaly detection logic. You must rebuild what vendors already trained.
Models degrade as hardware generations change. Your team must continuously retrain on new PDU firmware, updated IPMI schemas, and emerging cooling system designs.
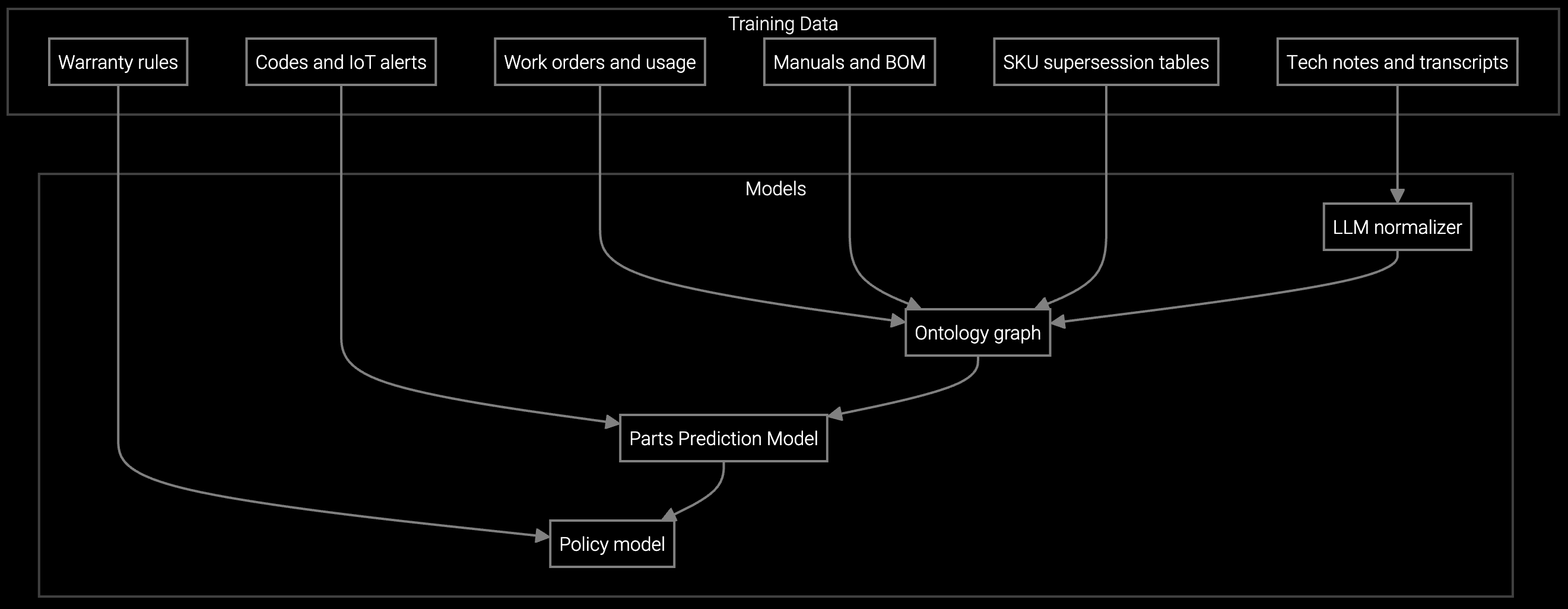
The best strategy combines vendor-trained models with your customization layer. Bruviti's platform arrives with pre-trained knowledge of data center failure patterns, thermal telemetry, and RAID degradation signals. You skip the 18-month training phase and start with models that already understand hyperscale environments.
API-first architecture lets you inject your proprietary dispatch rules, parts inventory logic, and SLA prioritization without vendor lock-in. Technicians use your existing FSM tools while AI runs behind the scenes. When a new server generation launches, Bruviti retrains the models and pushes updates via API. You focus on operations, not model maintenance.
Pre-stage PDU modules, memory DIMMs, and drive replacements before dispatch to avoid repeat trips in hyperscale environments.
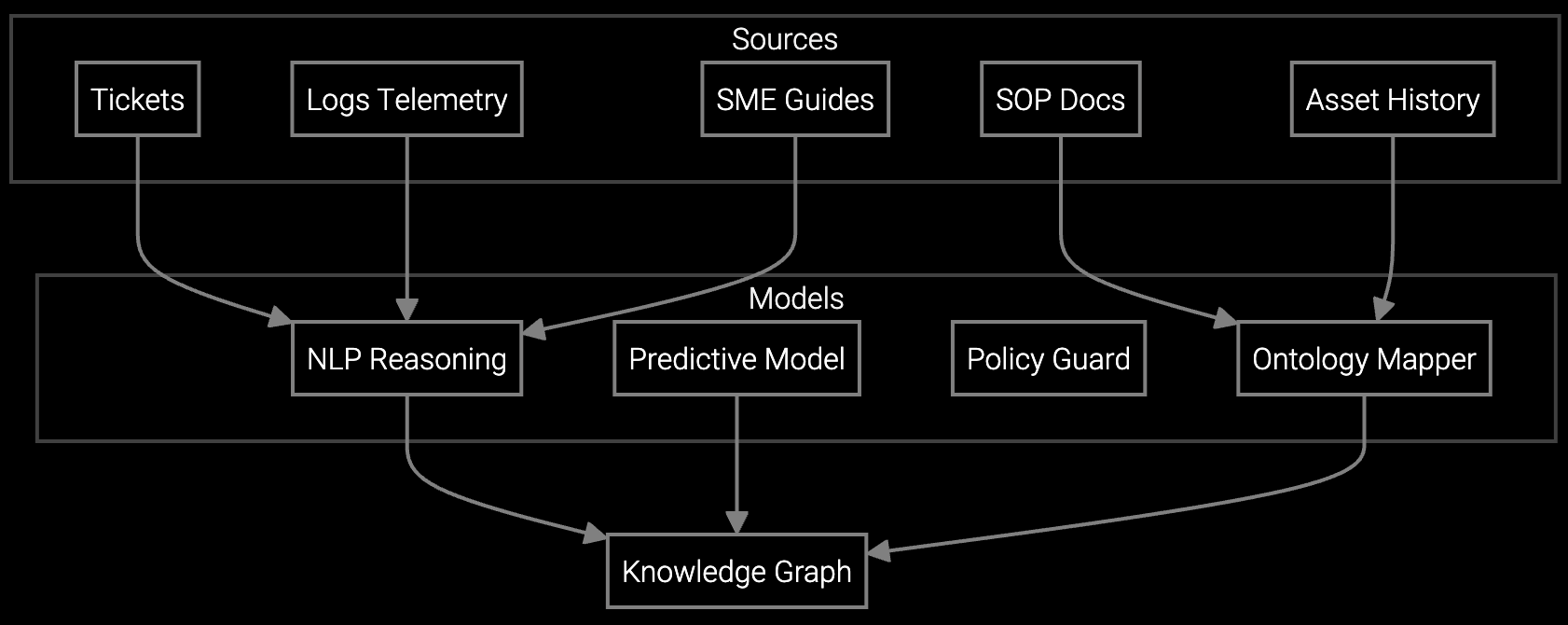
Correlate BMC logs with historical thermal events and power anomalies to pinpoint root cause faster than manual triage.
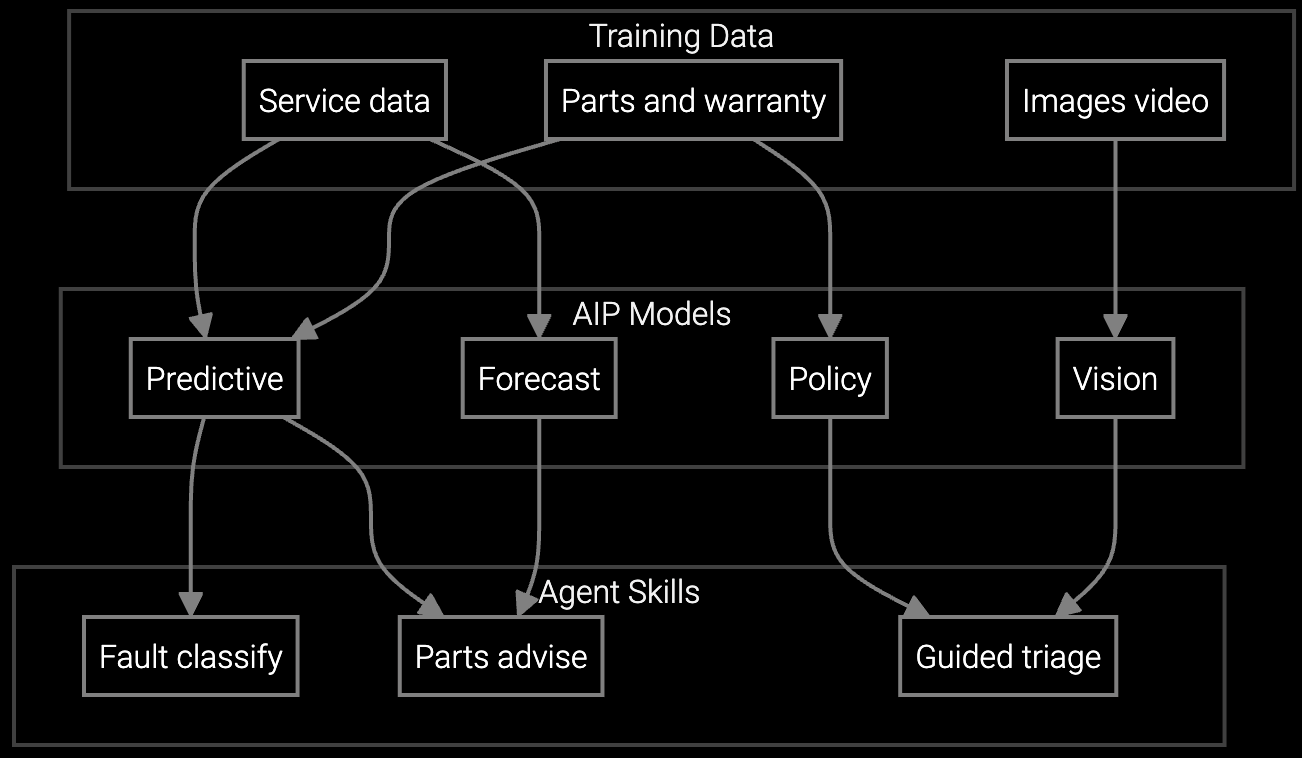
Mobile copilot provides real-time RAID rebuild procedures, firmware rollback steps, and diagnostic commands while on the data center floor.
Hyperscale operators manage millions of servers across distributed facilities with strict SLA requirements. Building AI systems from scratch means assembling training datasets for every failure mode: thermal runaway in hot aisles, RAID controller degradation, BMC firmware bugs, and power supply variance. Pre-trained models already know these patterns.
Data center technicians work in high-pressure environments where every minute of downtime costs thousands in SLA penalties. They cannot wait 18 months for homegrown AI to reach production. Vendor platforms deliver immediate value while leaving room for custom dispatch rules, parts optimization logic, and facility-specific workflows via API.
Most data center OEMs deploy pre-trained AI platforms in 60-90 days, including API integration with FSM systems and technician training. This compares to 18-24 months for building in-house models from scratch.
API-first platforms allow customization of dispatch rules, parts logic, and SLA prioritization without modifying the core AI models. You retain control over workflows while the vendor maintains model accuracy as hardware generations evolve.
Pre-trained models learn general failure physics applicable across server generations, cooling systems, and power infrastructure. Fine-tuning for specific equipment takes weeks, not years, because the foundational patterns already exist in the model.
Vendor-managed platforms handle model retraining as new hardware launches, firmware updates arrive, and failure patterns shift. Your team focuses on technician operations and workflow optimization rather than data science maintenance.
Choose platforms with open APIs and standard data formats. You should be able to export historical predictions, switch FSM integrations, and migrate workflows without losing operational continuity if you change vendors.

How AI bridges the knowledge gap as experienced technicians retire.

Generative AI solutions for preserving institutional knowledge.

AI-powered parts prediction for higher FTFR.
See how Bruviti's pre-trained models eliminate build delays while preserving your workflow control.
Talk to an Expert