When server lifecycles span 5-7 years across distributed sites, incomplete asset records drain resources daily.
Bruviti deployment data cut MTTR from 7 days to 2 days with connected installed-base tracking. For data center operators, every day of downtime removed is recovered capacity and avoided SLA penalty, making the tracking investment pay back through faster restores rather than added staff.
Missing serial numbers and configuration details force manual lookups across multiple systems. Each verification takes 15-20 minutes, delaying parts orders and service dispatches while equipment sits idle.
Servers get firmware updates, memory upgrades, and drive replacements that never make it into asset records. When incidents occur, you troubleshoot blind, ordering wrong parts or escalating unnecessarily.
Without lifecycle visibility, hard drives fail at 3 years, power supplies at 5 years, and you only know when telemetry alarms fire. Emergency replacements cost 3x more than planned swaps and trigger SLA penalties.
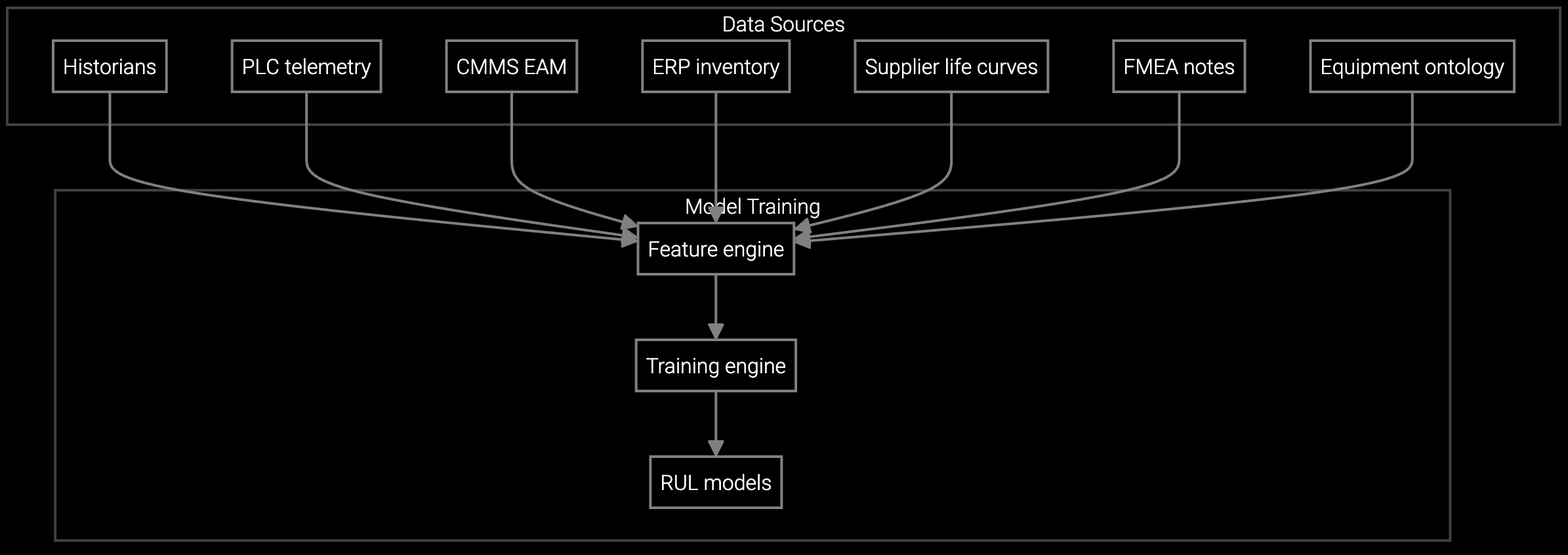
Bruviti's platform continuously ingests BMC telemetry, firmware logs, and parts replacement records to maintain a real-time asset registry. When you pull up a server, you see serial number, current configuration, warranty status, maintenance history, and predicted failure timeline in one screen. No hunting through three systems or calling the vendor for missing details.
The platform flags configuration drift automatically. When a memory module gets swapped or firmware updates, the asset record updates within minutes. This eliminates the 34% of service calls that resolve to "the config didn't match the documentation." You order the right part the first time, every time, cutting duplicate orders by 22% and getting equipment back online faster.

Virtual models of every server track real-time BMC data, predicting power supply failures and thermal issues before they trigger alarms.
Predicts when hard drives, DIMMs, and cooling fans will fail based on usage patterns, enabling planned maintenance during low-traffic windows.

Schedules component replacements based on actual equipment condition across thousands of servers, maximizing uptime and minimizing emergency interventions.
Data center OEMs manage installed bases of 10,000+ servers per customer site, each with unique configurations for compute, storage, and networking roles. A single hyperscale deployment might include 15 server SKUs across three generations, each with different memory, storage, and firmware combinations.
Tracking this complexity manually fails at scale. Asset records lag by weeks, configuration audits take days, and lifecycle planning relies on vendor-provided MTBF estimates rather than actual usage data. The platform ingests IPMI telemetry, RAID controller logs, and BMC sensor data to build accurate lifecycle models for every deployed unit, enabling proactive planning that matches real-world conditions.
Duplicate order reduction shows within 30 days as configuration records sync with real deployments. Downtime cost savings take 90 days to manifest as predictive maintenance cycles shift from reactive to proactive. Most OEMs see measurable ROI within the first quarter.
BMC telemetry provides real-time health metrics. IPMI logs track power events and thermal anomalies. RAID controller logs reveal drive health trends. Parts replacement records from service systems capture actual component swaps. Combining these streams creates a complete equipment history that predicts failures before they occur.
The platform detects configuration changes within minutes of firmware updates, memory swaps, or drive replacements. Asset records stay current automatically, eliminating the lag between physical changes and documentation updates. When service calls come in, you troubleshoot against accurate configs, ordering correct parts the first time.
Track duplicate order rate before and after implementation. Measure unplanned downtime hours monthly. Calculate emergency dispatch costs versus planned maintenance costs. Compare warranty utilization rates as proactive replacements catch failures before warranty expiration. These metrics quantify both cost avoidance and margin protection.
Yes. The platform normalizes telemetry from different BMC implementations, RAID controllers, and firmware versions into a unified asset model. Older servers with limited telemetry rely on parts replacement logs and manual audits, while newer units provide richer real-time data. All equipment gets tracked regardless of generation.

Software stocks lost nearly $1 trillion in value despite strong quarters. AI represents a paradigm shift, not an incremental software improvement.

Function-scoped AI improves local efficiency but workflow-native AI changes cost-to-serve. The P&L impact lives in the workflow itself.
Five key shifts from deploying nearly 100 enterprise AI workflow solutions and the GTM changes required to win in 2026.
Calculate your cost savings potential based on your deployed equipment volume and current service metrics.
Talk to an Expert