Every repeat truck roll to fix server, storage, or cooling failures drains margin and violates SLAs at hyperscale.
Bruviti deployment data shows AI lifts first call resolution 16% and cuts average handle time 12.5% for data center field service. Operators turn that into fewer escalations and more jobs closed per technician per day, with the gains measured directly from live deployments.
Technicians arrive on-site without the right drive, memory module, or PDU part. Second dispatch doubles cost and extends downtime for hyperscale customers counting every minute of lost capacity.
Complex IPMI logs, BMC telemetry, and RAID controller errors overwhelm technicians. Time spent decoding thermal anomalies or power distribution faults extends MTTR and triggers SLA penalties.
Data center customers demand four-nines uptime. Every delayed repair risks contractual penalties that wipe out service margin. Hardware diversity across generations compounds troubleshooting complexity.
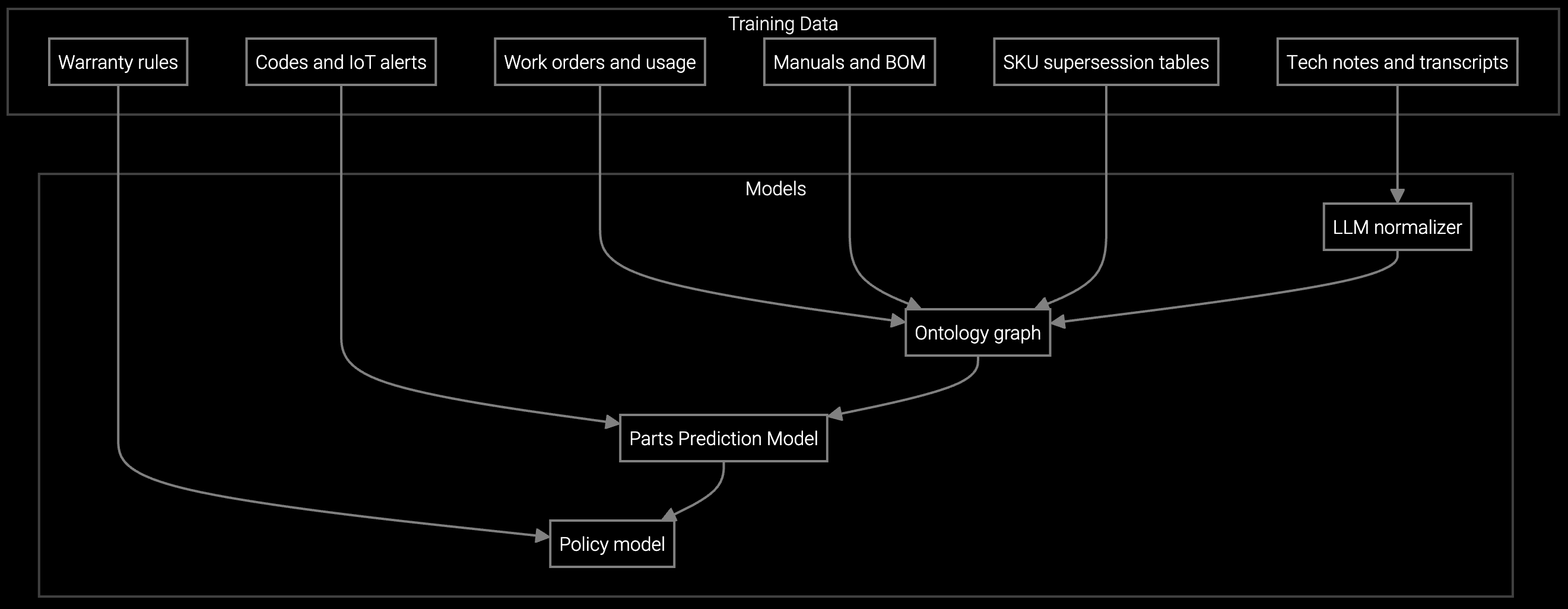
Bruviti analyzes BMC telemetry, IPMI event logs, and historical failure patterns across your data center equipment fleet to predict which parts fail and when. Before dispatch, the platform stages the exact drive model, memory module, or power supply the technician needs, eliminating return trips for missing components.
On-site, technicians access AI-driven root cause analysis that correlates thermal anomalies, power distribution errors, and RAID failures in seconds instead of scrolling through 500-page service manuals. The result: faster repairs, fewer repeat visits, and predictable service costs that protect margin even at hyperscale SLA requirements.
Predicts which server drives, memory modules, or PDU components technicians need before dispatch, cutting repeat visits for data center hardware by 44%.
Correlates IPMI logs, BMC telemetry, and historical thermal or power failures to identify root cause in minutes instead of hours.
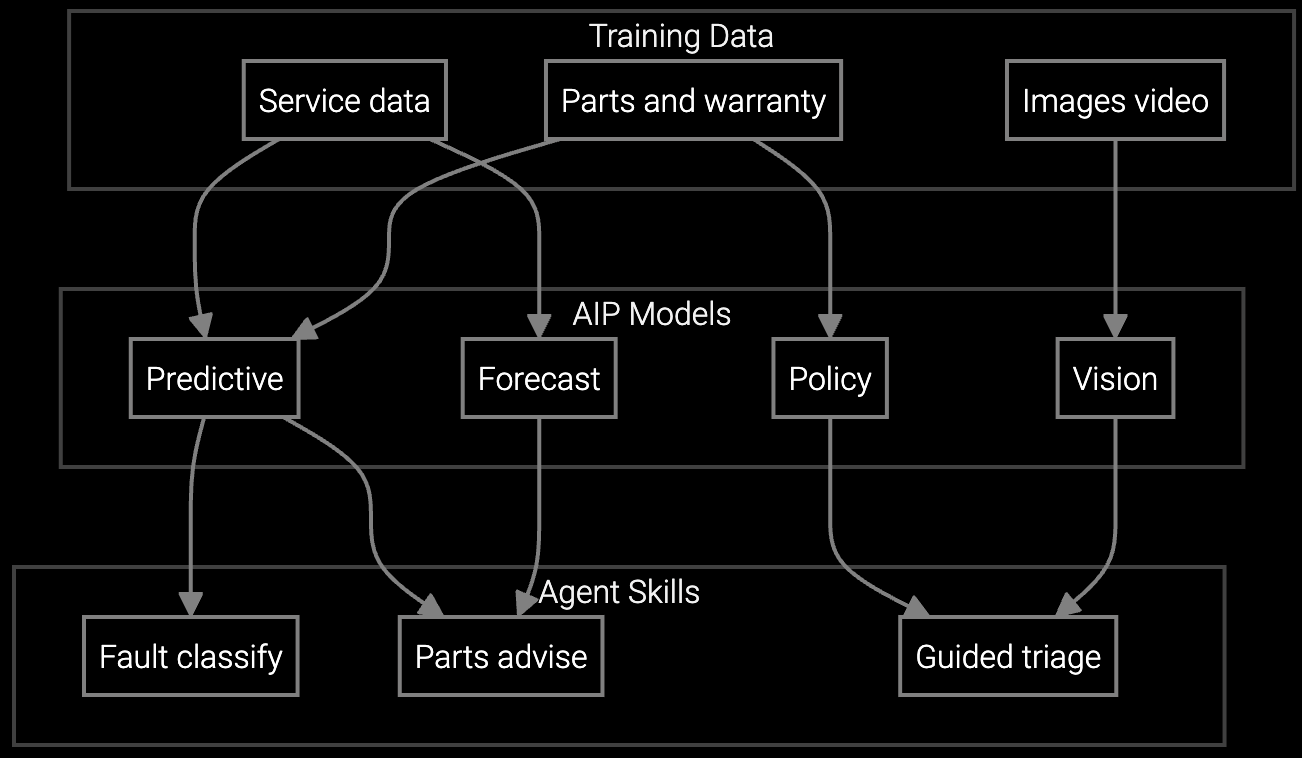
Mobile copilot surfaces repair procedures for RAID controllers, cooling systems, and storage arrays in real-time, eliminating manual searches through multi-vendor documentation.
Data center OEMs manage thousands of service events monthly across hyperscale deployments where 99.99% uptime is contractual. A single repeat truck roll to replace a failed power supply or diagnose a thermal anomaly costs $450-680 in labor, travel, and SLA exposure. At scale, eliminating 30% of repeat visits through predictive parts staging saves $1.8M-3.2M annually for mid-tier OEMs.
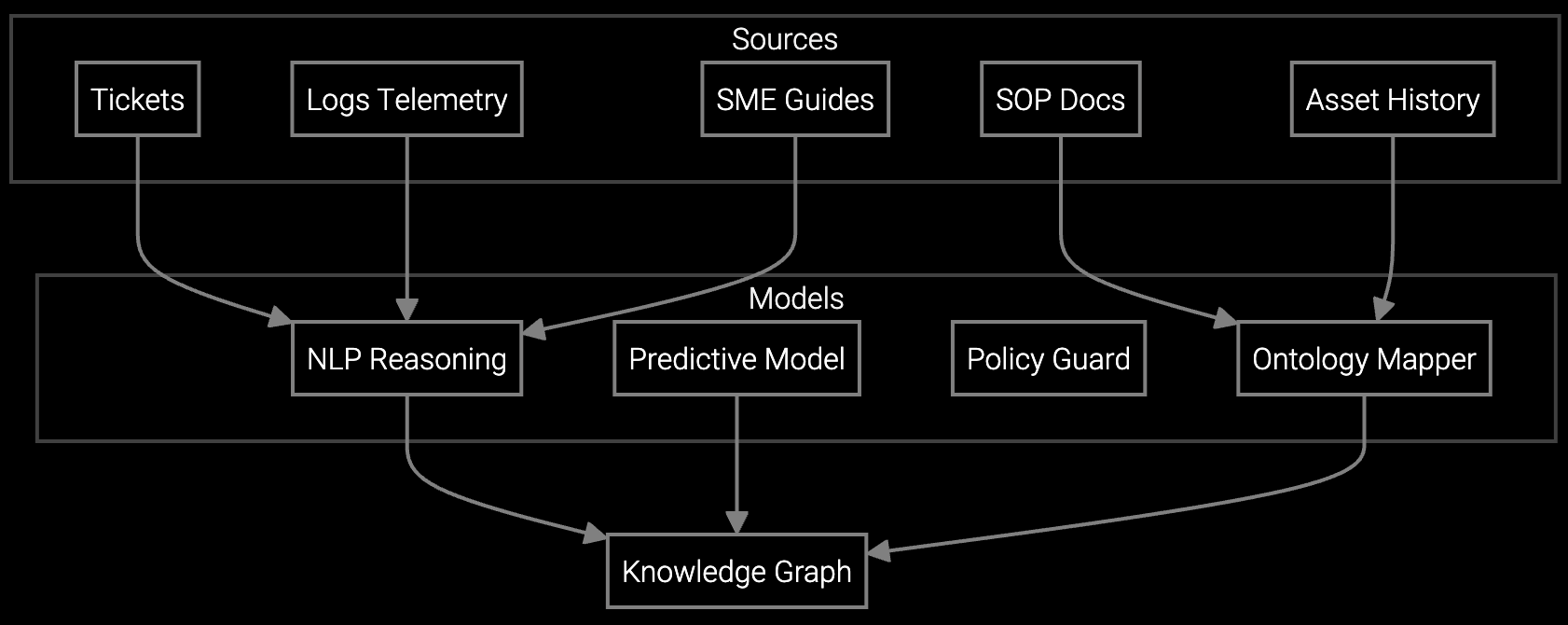
The platform analyzes BMC telemetry, IPMI event logs, and configuration drift across multi-generation hardware to predict failure modes technicians will encounter. This reduces diagnostic time on-site by 41% and accelerates MTTR compliance, protecting margin from penalty clauses tied to four-nines availability commitments.
Truck roll cost includes technician labor, travel time, vehicle expenses, and opportunity cost of unavailable capacity. For data center equipment, the average fully loaded cost is $450-680 per visit. AI platforms reduce repeat visits by predicting part failures and staging components before dispatch, eliminating 30-45% of second trips. Multiply eliminated visits by per-visit cost to calculate direct savings.
Mid-sized data center OEMs managing 2,000+ monthly service events typically see payback within 6-9 months. ROI accelerates with higher service volumes, stricter SLA penalties, and greater hardware diversity. The platform requires minimal integration effort with existing FSM and telemetry systems, reducing time to value compared to custom-built solutions.
The platform analyzes IPMI logs, BMC telemetry, and historical failure patterns to predict which server drives, memory modules, PDUs, or cooling components will fail. Technicians receive parts recommendations before dispatch, ensuring the right inventory is staged in the truck. This eliminates return trips for missing parts, the leading cause of low first-time fix rates in data center field service.
Track first-time fix rate, repeat truck roll percentage, average on-site diagnostic time, and SLA compliance. For financial ROI, measure truck roll cost per service event, SLA penalty exposure, and technician utilization. Data center OEMs typically see 32-47% improvement in first-time fix and 41% reduction in diagnostic time within the first quarter of deployment.
Yes. The platform ingests telemetry from multiple BMC vendors, IPMI standards, and proprietary RAID controller logs. It normalizes event codes and failure patterns across hardware generations, making it effective in heterogeneous data center fleets where technicians face high cognitive load from varying diagnostic protocols.

How AI bridges the knowledge gap as experienced technicians retire.

Generative AI solutions for preserving institutional knowledge.

AI-powered parts prediction for higher FTFR.
See how predictive parts staging and faster diagnostics reduce truck roll costs and SLA penalties in your data center fleet.
Talk to an Expert