Fab equipment downtime costs $1M per hour, yet most asset tracking platforms can't ingest telemetry at that scale without lock-in.
Bruviti deployment data shows a bought, embedded installed base platform goes live in 5 to 7 weeks versus a multi-quarter in-house build. For OEM engineering teams, the strategic question is integration speed against sensitive data, and the embedded approach keeps equipment data on site while shipping fast.
Building in-house asset tracking for lithography tools requires ML expertise, training pipelines, and continuous model maintenance. Many teams underestimate ongoing operational costs after initial development.
Closed platforms trap configuration data behind proprietary APIs. When fab requirements change or vendors sunset products, migration becomes a costly emergency project with no clean exit path.
Process telemetry from EUV systems contains competitive intelligence. Builders need guarantees about where models train, how data flows, and whether proprietary recipes remain isolated from shared infrastructure.
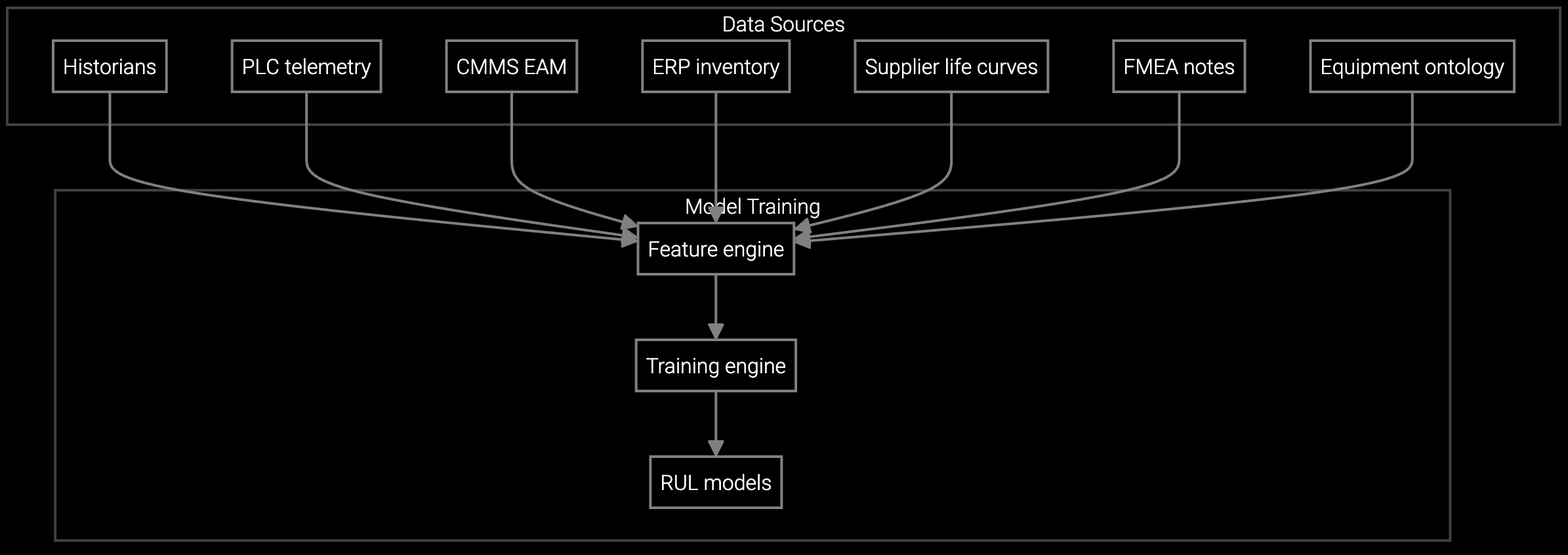
Bruviti's headless architecture separates foundational models from integration logic. Your team writes Python or TypeScript to ingest chamber sensor streams, while pre-trained models handle anomaly detection and remaining useful life prediction without reinventing pattern recognition.
The platform exposes REST APIs for configuration queries, GraphQL for asset hierarchies, and streaming endpoints for real-time telemetry. Custom business rules run in your environment. Training data never leaves your infrastructure unless you explicitly push embeddings to shared model improvement pipelines. You control the data flow.
Predict chamber component failures based on recipe usage patterns, scheduling maintenance during planned PM windows instead of emergency downtime events.

Monitor EUV tool telemetry streams for deviations from baseline performance, alerting process engineers before yield impacts occur.

Virtual equipment models track real-time metrology data, enabling proactive recalibration before wafer-level defects propagate across production lots.
Semiconductor fabs operate thousands of tools across lithography, etch, deposition, and metrology process areas. Each tool type generates distinct telemetry signatures. Lithography systems emit recipe parameter logs, EUV source stability metrics, and reticle alignment data. Etch chambers produce RF power traces, gas flow measurements, and endpoint detection signals.
The platform ingests heterogeneous sensor streams through standardized SECS/GEM interfaces and custom OPC-UA connectors. Asset hierarchies model tool-to-module-to-chamber relationships, preserving configuration lineage when components swap during preventive maintenance. This structure enables lifecycle queries like "which wafers processed through Chamber 3A between PM cycles 47-52" for defect source tracing.
Open REST and GraphQL endpoints give you direct programmatic access to configuration data and asset hierarchies. If you migrate platforms, standard API calls export your entire installed base without vendor-specific transformation logic. Closed systems trap data behind proprietary schemas requiring expensive ETL projects.
Yes. The platform supports federated learning where models train locally on your infrastructure. Only aggregated model weights or embeddings transfer to central servers for ensemble improvement. Raw sensor data and recipe parameters never leave your network unless you explicitly configure cloud sync.
Proof-of-concept on a single tool type takes 4-6 weeks. Expanding to full fab coverage typically requires 8-12 weeks, including MES integration and process engineer training. This assumes existing SECS/GEM infrastructure for telemetry collection. Custom sensor integrations add 3-4 weeks per tool family.
The asset registry tracks component-level lineage with timestamp logs. When Chamber 3A receives a new showerhead during PM, the system versions the configuration and links subsequent telemetry to the updated bill of materials. This preserves traceability for defect investigations correlating wafer quality to specific hardware generations.
Your Python and TypeScript code calls standard APIs, not proprietary SDKs. Business rules for anomaly thresholds, maintenance triggers, and escalation workflows run in your environment as containerized microservices. Migrating platforms only requires swapping the backend data source endpoint, not rewriting integration logic.

Software stocks lost nearly $1 trillion in value despite strong quarters. AI represents a paradigm shift, not an incremental software improvement.

Function-scoped AI improves local efficiency but workflow-native AI changes cost-to-serve. The P&L impact lives in the workflow itself.
Five key shifts from deploying nearly 100 enterprise AI workflow solutions and the GTM changes required to win in 2026.
See how API-first infrastructure preserves flexibility while accelerating time to predictive maintenance.
Request Technical Demo