Hyperscale deployment demands asset tracking that integrates with existing BMC infrastructure without vendor lock-in.
Bruviti deployment data puts a bought equipment AI platform in production in 5-7 weeks, against the multi-quarter build a homegrown asset tracker demands. For data center OEM engineering teams, buying means inheriting connected fault detection and lifecycle workflows on day one instead of maintaining ingestion plumbing yourself.
Data centers manage thousands to millions of servers across diverse hardware generations. Manual asset registries quickly fall behind actual deployed configurations, breaking automated provisioning workflows and capacity planning models.
Baseboard management controllers generate rich telemetry, but extracting lifecycle insights requires parsing vendor-specific IPMI implementations and maintaining connectors as firmware updates introduce schema changes.
Enterprise customers mandate on-premises data control and audit trails for compliance. Black-box SaaS platforms that move asset data off-site create deal blockers, especially in regulated verticals.
The build vs. buy decision hinges on control versus speed. Building custom asset tracking gives full control over data models and integration logic, but requires maintaining ML pipelines, handling training data quality, and keeping pace with evolving hardware telemetry standards. Teams spend months building connectors that commercial vendors already support.
API-first platforms offer a middle path. Bruviti's asset tracking provides pre-built BMC/IPMI connectors and configuration drift detection models while exposing Python and TypeScript SDKs for custom lifecycle rules. Your team owns the business logic—determining which firmware versions trigger alerts, defining asset groupings for capacity planning, or building custom dashboards—without training foundation models from scratch. Data stays in your VPC or on-premises clusters, satisfying sovereignty requirements while avoiding lock-in.

Parse BMC sensor streams to flag thermal anomalies, power fluctuations, and drive health degradation before servers fail in production racks.
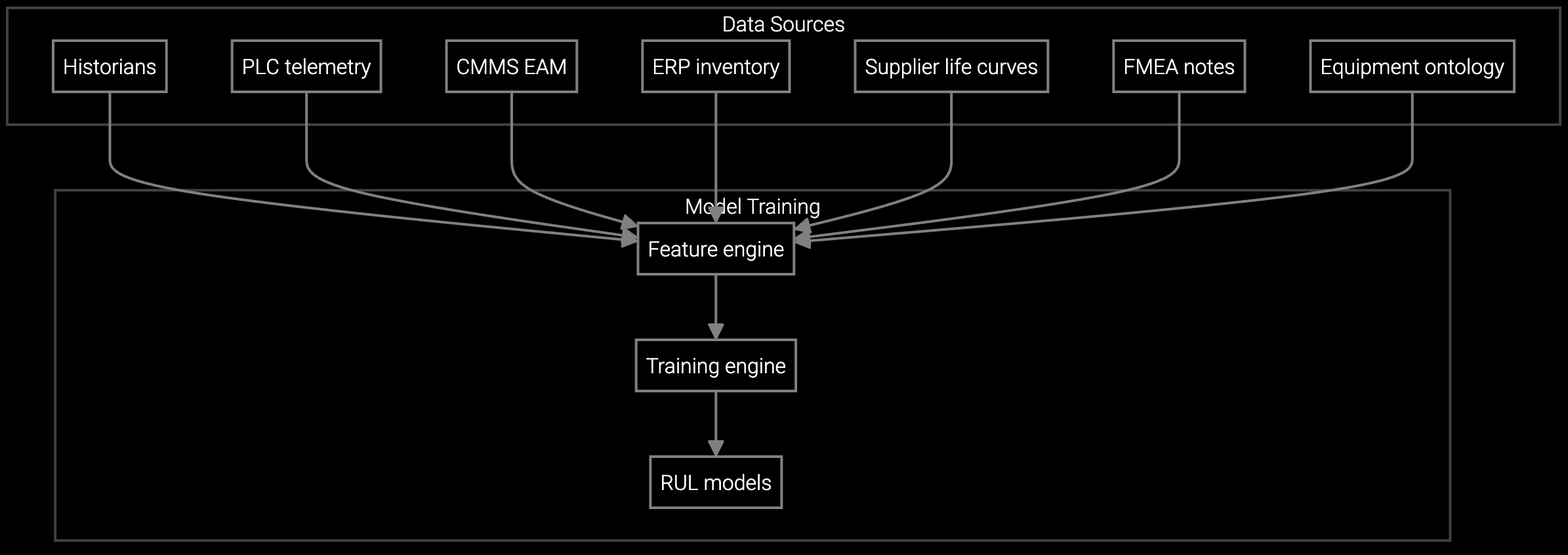
Estimate server component lifespan using usage telemetry and historical failure patterns, enabling planned maintenance windows during off-peak hours.

Schedule maintenance based on actual equipment condition rather than fixed intervals, reducing unnecessary downtime while preventing unexpected failures.
Data center OEMs face unique asset tracking challenges driven by scale and hardware diversity. A single hyperscale customer may deploy 50,000 servers across multiple generations, each with different BMC firmware versions, RAID configurations, and power profiles. Traditional CMDB systems struggle to maintain accuracy when configuration changes happen hourly through automated provisioning pipelines.
The strategic question centers on integration velocity versus customization depth. Pre-built platforms accelerate deployment but may not support custom capacity planning algorithms or vendor-specific telemetry formats. Building in-house delivers perfect fit but requires dedicated ML teams to maintain prediction accuracy as hardware evolves. API-first architectures enable rapid deployment with escape hatches for custom logic where differentiation matters.
Building from scratch requires ML engineers for model training, data engineers for telemetry pipeline maintenance, and full-stack developers for API layer implementation. Plan for 3-5 FTEs minimum to handle initial development plus ongoing maintenance as hardware generations evolve. API-first platforms reduce this to 1-2 engineers focusing on business logic rather than infrastructure.
Pre-built connectors abstract vendor differences by normalizing IPMI, Redfish, and proprietary protocols into consistent data schemas. When new hardware introduces unsupported telemetry formats, SDKs allow custom parsers without modifying core platform code. This maintains upgrade paths while supporting differentiated hardware features.
Hybrid deployments run compute in customer VPCs or on-premises Kubernetes clusters while optionally syncing anonymized metadata for model improvements. This satisfies compliance requirements for regulated customers while enabling continuous learning. Pure on-premises deployments eliminate external data movement entirely but require local model retraining infrastructure.
REST APIs enable integration with Grafana, Splunk, or custom dashboards within 1-2 weeks for standard telemetry feeds. Custom workflows like triggering automated RMAs based on predicted failures require 4-6 weeks for business logic development and testing. SDK-based approaches let teams iterate without vendor dependency.
Traditional SaaS tools provide fixed workflows and require data to leave customer infrastructure. API-first platforms expose extensible interfaces allowing custom lifecycle rules, on-premises deployment, and integration with existing tools. This enables differentiation while avoiding the full cost of building ML infrastructure from scratch.

Software stocks lost nearly $1 trillion in value despite strong quarters. AI represents a paradigm shift, not an incremental software improvement.

Function-scoped AI improves local efficiency but workflow-native AI changes cost-to-serve. The P&L impact lives in the workflow itself.
Five key shifts from deploying nearly 100 enterprise AI workflow solutions and the GTM changes required to win in 2026.
See how Bruviti's SDK enables custom lifecycle logic without foundation model overhead.
Schedule Technical Demo