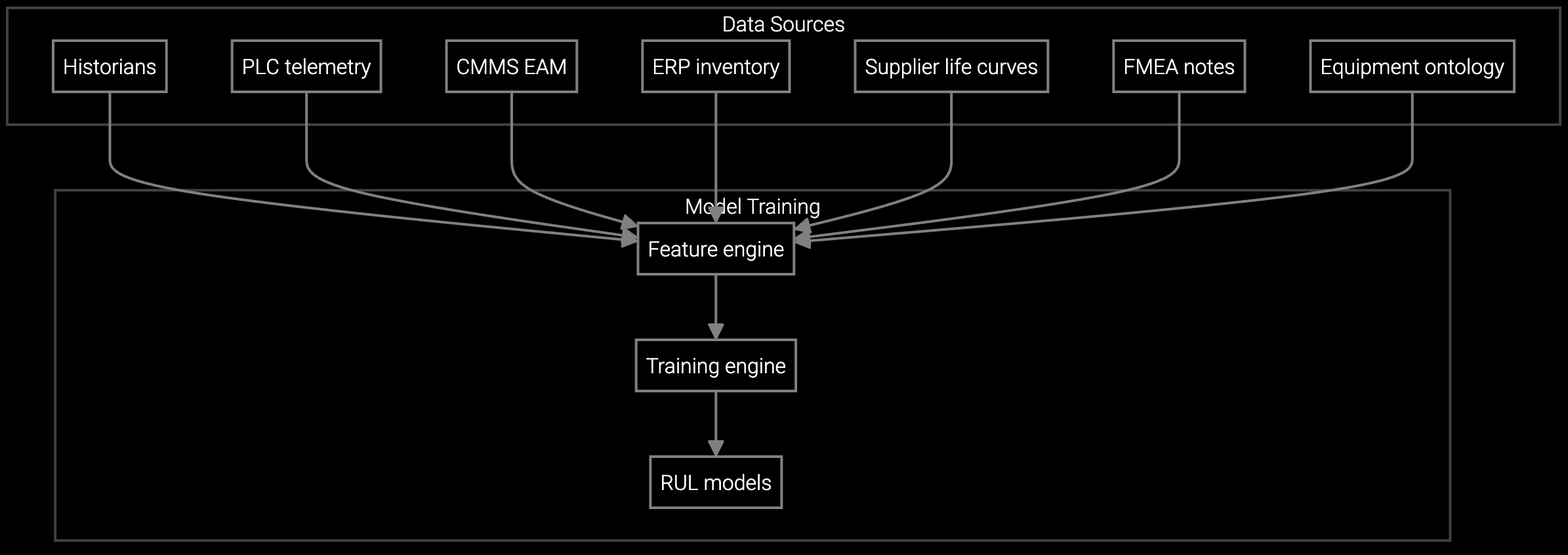
Router and switch OEMs can't predict failures without telemetry intelligence, but building in-house requires 18 months most don't have.
Buying a proven installed base platform gets network OEM engineering teams live in 5 to 7 weeks, per Bruviti deployment data, versus a multi-quarter in-house build. The platform already ingests serial, config, and telemetry data, so teams spend effort on differentiation, not on reinventing asset reconciliation plumbing.
Building an in-house telemetry analytics stack requires data engineering, model training, and API development. Most network OEMs underestimate the timeline and resource commitment required to reach production quality.
Traditional service platforms trap OEMs in proprietary ecosystems with no API access, limited customization, and escalating costs. Switching platforms later requires rebuilding integrations from scratch.
Off-the-shelf platforms can't parse SNMP traps, syslog formats, or firmware-specific telemetry unique to your routers and switches. Generic anomaly detection misses network-specific failure signatures.
Bruviti's platform resolves the build-versus-buy trade-off by providing pre-trained models for network equipment telemetry alongside Python and TypeScript SDKs for custom logic. You start with working anomaly detection, predictive RMA, and configuration drift models on day one, then extend them with your own rules, thresholds, or data sources as needed.
The architecture is headless and API-first. Ingest SNMP traps, syslog streams, and firmware telemetry via REST or streaming APIs. Query predictions, asset state, and lifecycle data from your existing service portals, NOC dashboards, or custom applications. No forced UI, no black-box decisions, no vendor lock-in. You control the integration points and own the data pipeline.

Monitor SNMP traps and syslog streams from deployed routers and switches, flagging deviations from baseline behavior before customer-impacting failures.

Schedule firmware updates and proactive replacements during planned maintenance windows based on equipment condition, not fixed time intervals.
Estimate when network devices will reach end-of-life based on traffic patterns, thermal stress, and error rates, enabling proactive refresh planning.
Network equipment OEMs face unique challenges: devices deployed in 24/7 mission-critical environments, firmware complexity across product generations, and telemetry volume measured in millions of SNMP traps and syslog messages per day. Generic installed base platforms can't parse your proprietary MIBs or correlate error patterns specific to your ASIC architectures.
Hybrid platforms address this by ingesting your telemetry formats natively while providing pre-trained models that understand network-specific failure modes: optical transceiver degradation, routing table exhaustion, memory leaks in specific firmware builds. You extend these models with custom rules for your product line without rebuilding the entire stack.
Integration typically takes 2-4 weeks. The platform supports standard SNMP trap formats and syslog protocols out of the box. Custom MIB parsing or proprietary telemetry formats require additional configuration, which the Python SDK exposes as parseable event streams. Most network OEMs start ingesting data within the first week and begin model training in week two.
Yes. The platform provides base models for network equipment anomaly detection, then exposes APIs for adding custom rules, thresholds, and correlation logic. You can write Python functions that trigger on specific error code sequences, thermal patterns, or traffic anomalies unique to your product line. These custom extensions run alongside the base models without forking the codebase.
All telemetry data, predictions, and asset metadata are accessible via REST APIs. You can export historical event logs, model outputs, and configuration state at any time. The platform does not encrypt or obfuscate your data in proprietary formats. Most OEMs run parallel integrations during evaluation periods to validate portability before committing to production scale.
Building in-house requires hiring data engineers, ML engineers, and DevOps to build telemetry pipelines, train models, and maintain infrastructure. Most network OEMs report 12-18 month timelines and $2-4M in year-one costs before reaching production quality. Hybrid platforms compress this to 8-12 weeks and allow your engineers to focus on product-specific logic rather than infrastructure.
The platform is API-first and headless, designed to augment existing service systems rather than replace them. Predictive RMA alerts, anomaly scores, and asset lifecycle data flow into your ServiceNow, Salesforce, or custom portals via webhooks or REST queries. You control the integration points and preserve existing workflows.

Software stocks lost nearly $1 trillion in value despite strong quarters. AI represents a paradigm shift, not an incremental software improvement.

Function-scoped AI improves local efficiency but workflow-native AI changes cost-to-serve. The P&L impact lives in the workflow itself.
Five key shifts from deploying nearly 100 enterprise AI workflow solutions and the GTM changes required to win in 2026.
See pre-trained models running on your SNMP traps and syslog streams in a 2-week proof of concept.
Schedule Technical Review