Fab downtime costs demand architectural decisions that balance speed-to-production with long-term extensibility and control.
Bruviti deployment data shows the right remote support architecture delivers 50 to 70% fewer false alarms with detection-to-alert under 2 seconds. The build-versus-buy call for tool builders comes down to whether an in-house stack can match a self-learning, API-integrated platform on alarm precision and streaming speed at fab scale.
Building custom diagnostics models from scratch requires 18-24 months of labeled failure data across recipe variations. Fab equipment can't wait that long for improved remote resolution rates.
Commercial platforms that require proprietary data schemas force costly transformations of SECS/GEM streams and create migration barriers when tool architectures change.
Pure build strategies fail when internal teams lack experience with semiconductor-specific failure modes. Generic ML engineers can't distinguish recipe drift from hardware degradation.
Bruviti's platform delivers a middle path: pre-trained foundation models that understand semiconductor failure patterns, exposed through Python SDKs and REST APIs for customization. Your engineering team writes the telemetry parsers and integration logic in standard languages while leveraging models trained on cross-customer failure data you can't replicate internally.
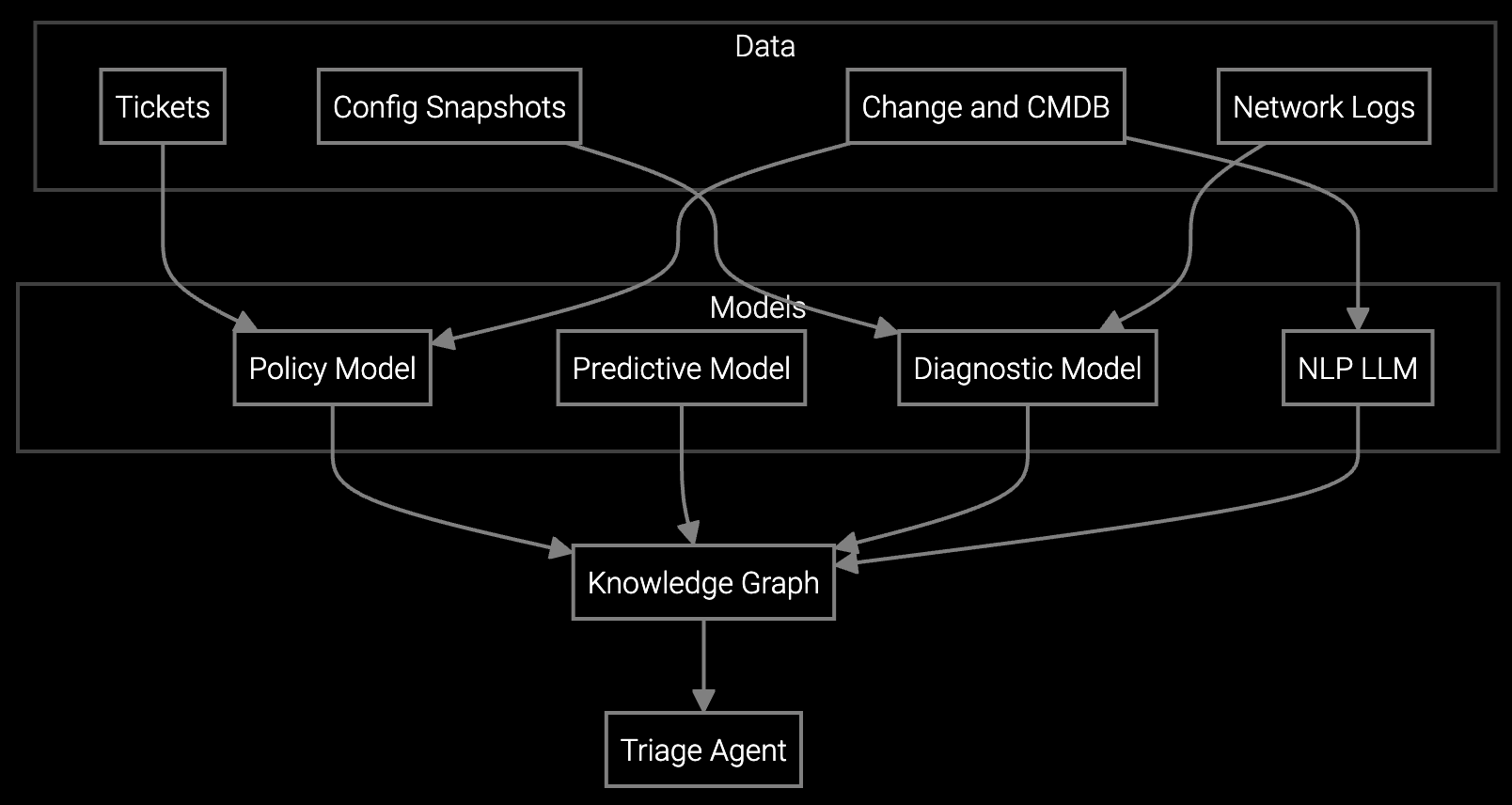
The architecture separates data ingestion from inference. You control SECS/GEM stream parsing, recipe normalization, and tool-specific transformations using your existing Python or TypeScript codebases. The platform handles pattern recognition, anomaly detection, and guided troubleshooting generation through versioned API endpoints. When models need retraining for new tool generations, you provide labeled examples through the same API without rebuilding infrastructure.
Semiconductor equipment generates telemetry streams with millisecond-level precision across temperature, pressure, gas flow, RF power, and wafer position sensors. A hybrid architecture lets you build custom parsers for proprietary SECS/GEM message formats while using pre-trained models to detect chamber degradation patterns that require months of labeled failure data to learn.
The platform's API-first design integrates with existing MES and FDC systems through REST endpoints. Your support engineers access guided troubleshooting workflows generated from real-time sensor analysis without waiting for ML team cycles. When new tool generations ship, you extend the base models through fine-tuning APIs rather than rebuilding the diagnostics engine.
API-first platforms expose model inference through standard REST endpoints and accept telemetry in common formats like JSON or Parquet. You maintain ownership of data transformation logic in your codebase. If you migrate platforms, your parsers and integration code remain functional because they don't depend on proprietary SDKs or data schemas.
SDKs let you inject custom feature engineering, recipe normalization, and tool-specific thresholds into the inference pipeline. For example, you can write Python functions that translate proprietary chamber setpoint formats into normalized features the base model understands. The platform handles model serving, versioning, and scaling while you control the domain logic.
With pre-trained foundation models, initial deployment typically takes 6-8 weeks: 2 weeks for telemetry integration, 3 weeks for workflow configuration and testing, 1-2 weeks for support engineer training. Pure build approaches require 18+ months because you need to collect failure data, label examples, train models, and validate accuracy before production use.
Yes. The platform provides fine-tuning APIs where you submit labeled examples of new failure patterns specific to your equipment. The base model's transfer learning capabilities mean you need 50-100 labeled failures rather than thousands. Model versioning lets you test new versions in parallel with production models before cutover.
General-purpose LLMs lack semiconductor domain knowledge and require extensive fine-tuning with labeled failure data you likely don't have. Bruviti's models are pre-trained on cross-customer equipment telemetry and failure modes, providing accurate diagnostics out of the box. You extend rather than build from scratch, reducing time-to-value from years to weeks.

Software stocks lost nearly $1 trillion in value despite strong quarters. AI represents a paradigm shift, not an incremental software improvement.

Function-scoped AI improves local efficiency but workflow-native AI changes cost-to-serve. The P&L impact lives in the workflow itself.
Five key shifts from deploying nearly 100 enterprise AI workflow solutions and the GTM changes required to win in 2026.
See the API documentation, integration patterns, and customization capabilities in a technical walkthrough.
Schedule Technical Review