Fab downtime costs $1M+ per hour, yet agents struggle to retrieve process knowledge fast enough to prevent escalations.
Bruviti deployment data shows AI auto-summarizes 85% of support cases in under 7 seconds, giving fab service agents instant case context. Builders wire the case-summary agent into the contact center so every ticket opens pre-read, cutting the manual review that slows complex semiconductor equipment support.
Agents query six different systems to answer wafer handling questions. Process documentation lives in SharePoint, failure codes in SAP, recipe parameters in MES, and equipment history in Oracle. No single API surfaces all context.
Every incoming case about chamber performance, contamination, or yield degradation requires manual triage. Agents spend time determining severity and routing instead of resolving issues, delaying response to critical fab equipment.
Different agents give different troubleshooting steps for identical EUV tool symptoms. Without centralized access to process engineer expertise, responses vary by agent tenure and experience level, eroding customer trust.
Bruviti provides REST APIs and Python SDKs that integrate AI-powered knowledge retrieval directly into your existing CRM and ticketing workflows. The platform ingests process telemetry, equipment logs, case history, and technical documentation, then exposes semantic search and auto-classification endpoints. Agents query the API via sidebar widgets or chatbots without switching systems.
The architecture decouples AI inference from your data layer. You control where training data resides, how models are versioned, and which answers surface in production. Custom routing logic lives in your Python code, not a black box SaaS dashboard. This anti-vendor-lock design lets you swap foundation models, retrain on new equipment types, or migrate to self-hosted inference without rewriting integrations.
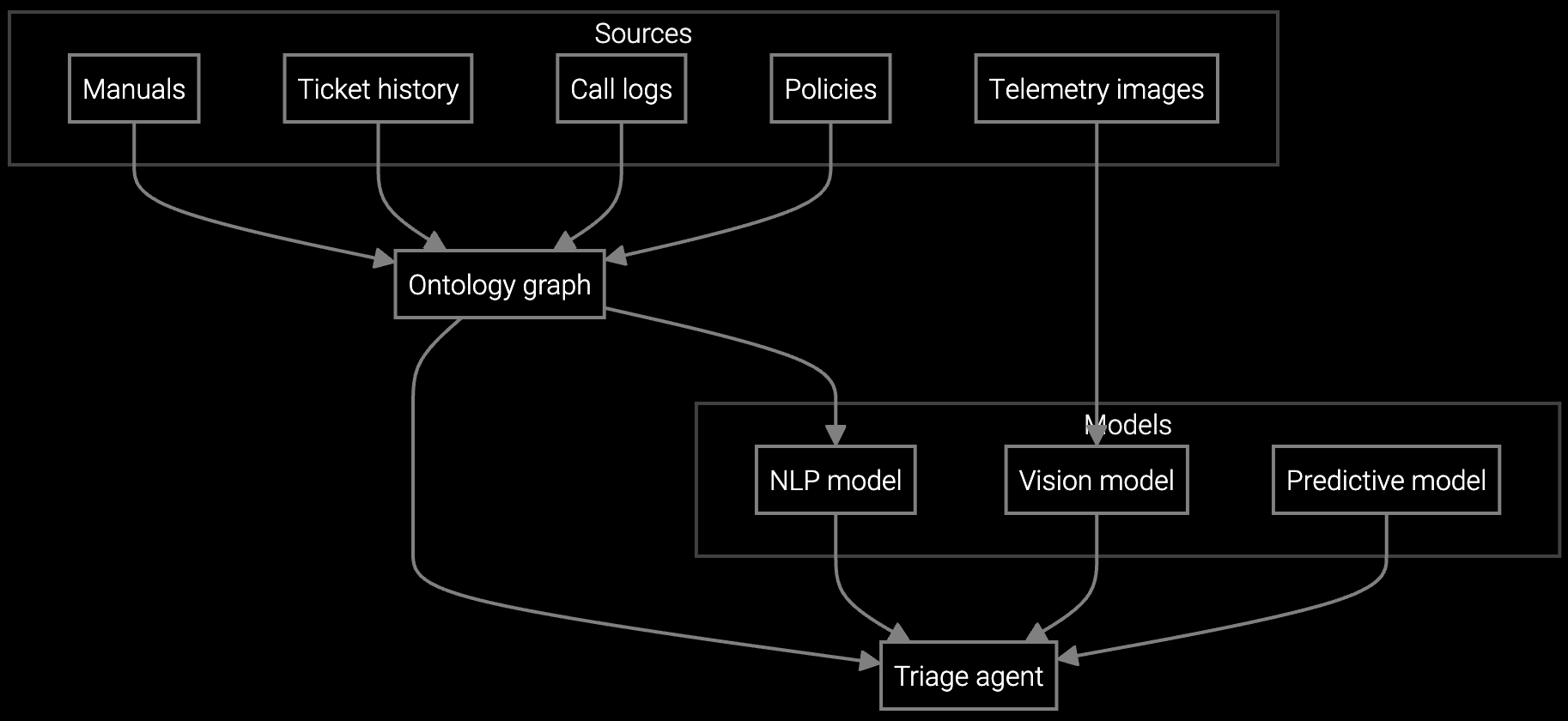
Autonomous API classifies incoming fab cases by analyzing symptom text, correlating equipment telemetry, and matching failure signatures to route lithography vs etch issues instantly.
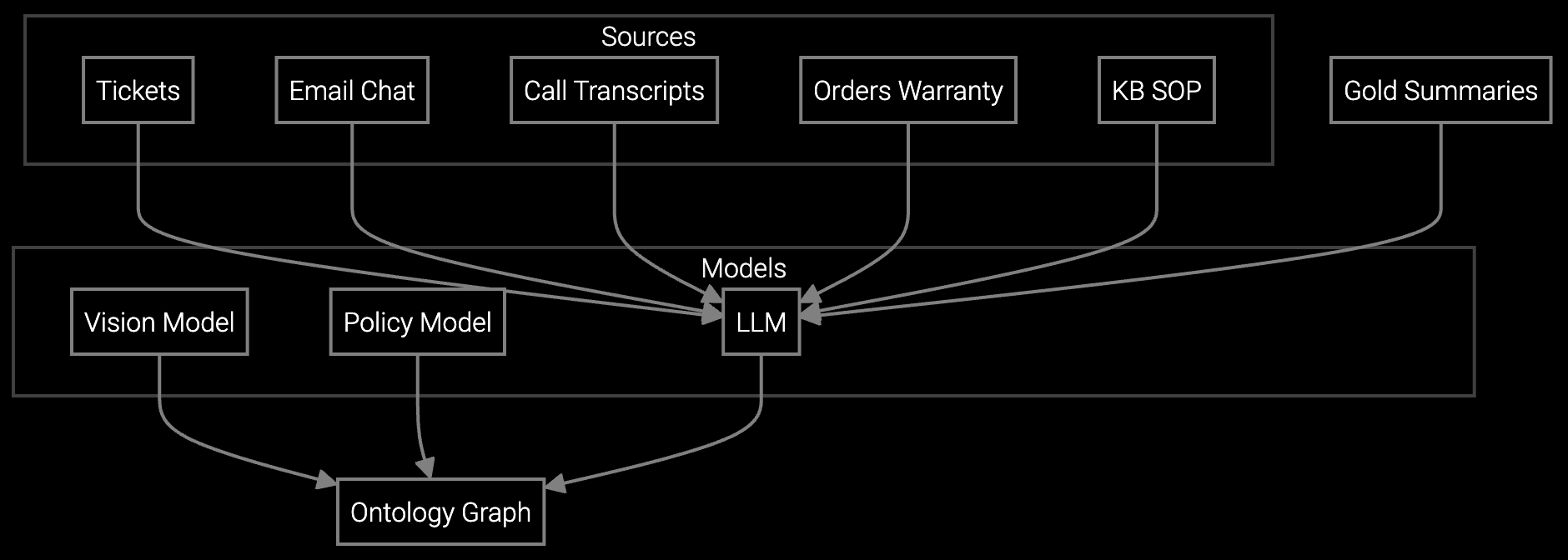
SDK generates structured case summaries from email threads, chat logs, and call transcripts so agents inherit full context without reading 30-message chains about wafer defects.
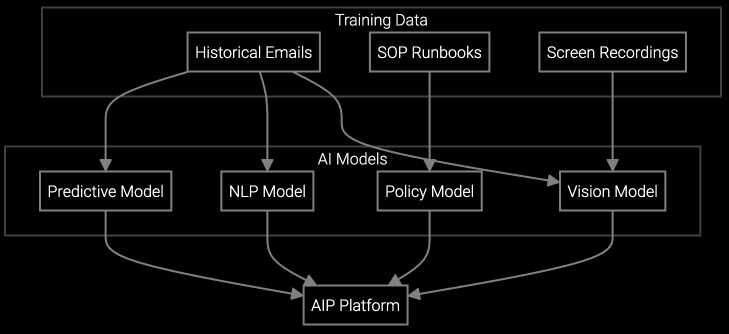
API reads incoming support emails, extracts equipment serial numbers and error codes, retrieves relevant troubleshooting steps, and drafts technical responses using historical case patterns.
Semiconductor customer service teams handle cases spanning lithography, etch, deposition, metrology, and wafer handling equipment. Each tool type generates unique telemetry streams—chamber pressure curves, plasma parameters, temperature profiles, and robot arm positioning logs. Agents must correlate these signals with process recipes, PM schedules, and consumable usage to diagnose whether a yield drop stems from recipe drift, contamination, or mechanical failure.
The Bruviti platform ingests sensor data from FOUPs, real-time SPC alerts from MES, and failure mode annotations from Oracle service records. The Python SDK parses this telemetry into standardized schemas, then exposes vector search endpoints that match current symptoms to historical resolution patterns. Agents query the API using natural language—"EUV reticle alignment drift after PM cycle"—and receive ranked troubleshooting steps grounded in actual case outcomes, not generic manuals.
Python and TypeScript SDKs are available with full documentation. The REST API accepts standard JSON payloads, so any language with HTTP client libraries can integrate. Most semiconductor service teams use Python for data pipeline integration with MES and Oracle systems.
You control data residency. The platform supports on-premise deployment where all training data, embeddings, and model weights remain in your data center. API calls never send raw telemetry to external servers—only anonymized query vectors leave your network if using cloud inference endpoints.
Yes. The Python SDK includes fine-tuning scripts that accept your labeled case data and equipment logs. You can retrain retrieval models on new tool types, adjust classification thresholds, or swap foundation models entirely without breaking existing integrations. All training happens in your environment using standard PyTorch workflows.
API response time averages 450ms for semantic search across 10M+ historical cases and 500GB of technical documentation. This includes vector embedding, retrieval, and answer generation. Cached queries return in under 100ms. The system handles 1,000 concurrent agent queries without degradation.
The platform provides pre-built Lightning Web Components that embed the AI copilot sidebar directly in Salesforce case views. The LWC calls the Bruviti API via Named Credentials, passing case context and returning answers inline. No custom Apex code required. Setup takes 2-3 hours including authentication configuration.

Understanding and optimizing the issue resolution curve.

Part 1: The transformation of IT support with AI.

Part 2: Implementing AI in IT support.
Talk to our solutions architects about API access, SDK documentation, and sandbox environments for your dev team.
Schedule Technical Review