Legacy CRM systems and fragmented knowledge bases block fast case resolution—agents need unified AI-driven tools now.
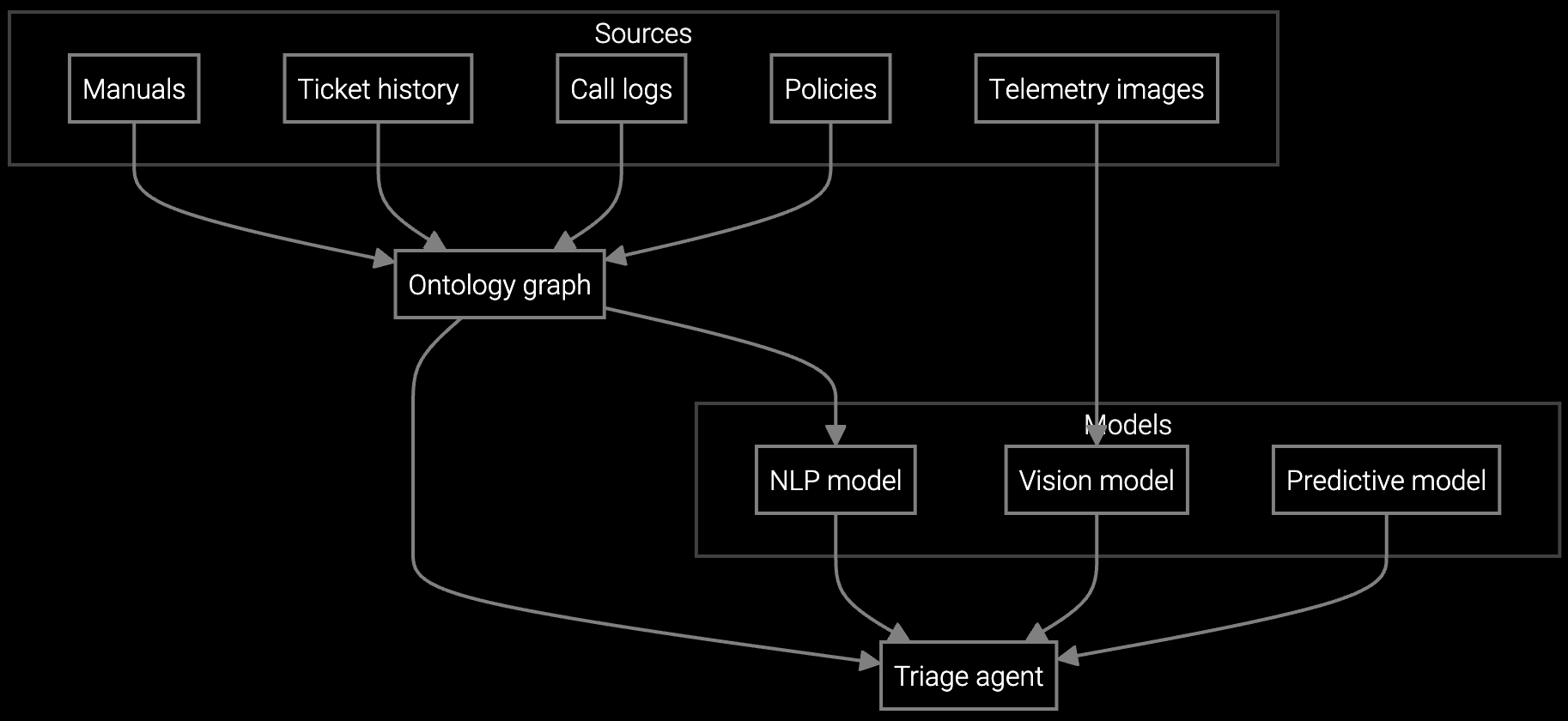
Bruviti deployment data shows AI auto-summarizes 85% of industrial equipment service cases in under 7 seconds, dropping average handling time 22%. Builders wire the agent-assist layer into existing CRM and knowledge bases, so technicians open a case with the full diagnostic context already written, not a blank screen.
Proprietary platforms force developers into rigid workflows with limited API access. Customizing case routing logic or training models on historical data requires expensive consulting engagements or vendor-specific languages.
Service documentation scattered across SharePoint, Confluence, PDF manuals, and Salesforce articles. No unified API to query all sources, forcing agents to manually search multiple systems per case.
Vendor-provided AI for case classification offers no visibility into training data or decision logic. When models fail on edge cases specific to industrial equipment, developers cannot retrain or fine-tune behavior.
Bruviti's API-first platform gives technical teams full control over customer service AI implementation. Python and TypeScript SDKs let developers integrate case routing, knowledge retrieval, and auto-classification into existing CRM workflows without migrating data or replacing systems. Train custom models on historical case data using your own Python notebooks, then deploy via REST endpoints that connect to Salesforce, ServiceNow, or custom ticketing stacks.
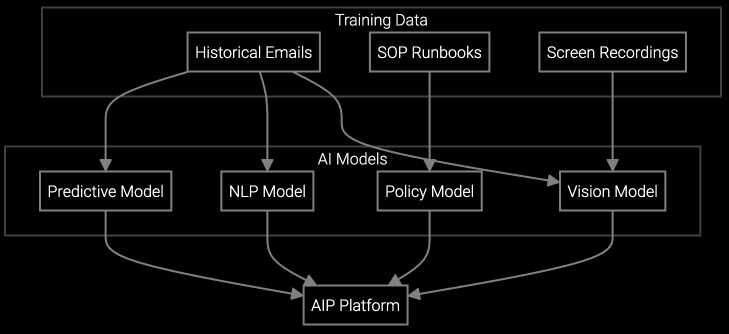
The platform exposes granular control over model behavior through configuration files and training pipelines. Developers can fine-tune classification thresholds, add domain-specific terminology for industrial equipment, and retrain models when performance drifts. Real-time telemetry APIs ingest sensor data from SCADA and PLC systems, correlating equipment health signals with case history to surface predictive insights agents can act on immediately.
Autonomous case classification for CNC machines and compressors—analyzes symptoms, correlates telemetry from PLCs, and routes to specialized teams with diagnostic context.
Instantly generates case summaries from emails, chat logs, and call transcripts for industrial equipment service history—agents understand context without reading through years of documentation.
AI reads and classifies inbound service emails for pumps, turbines, and automation systems—drafts responses using historical case data and technical manuals, then routes to appropriate engineering teams.
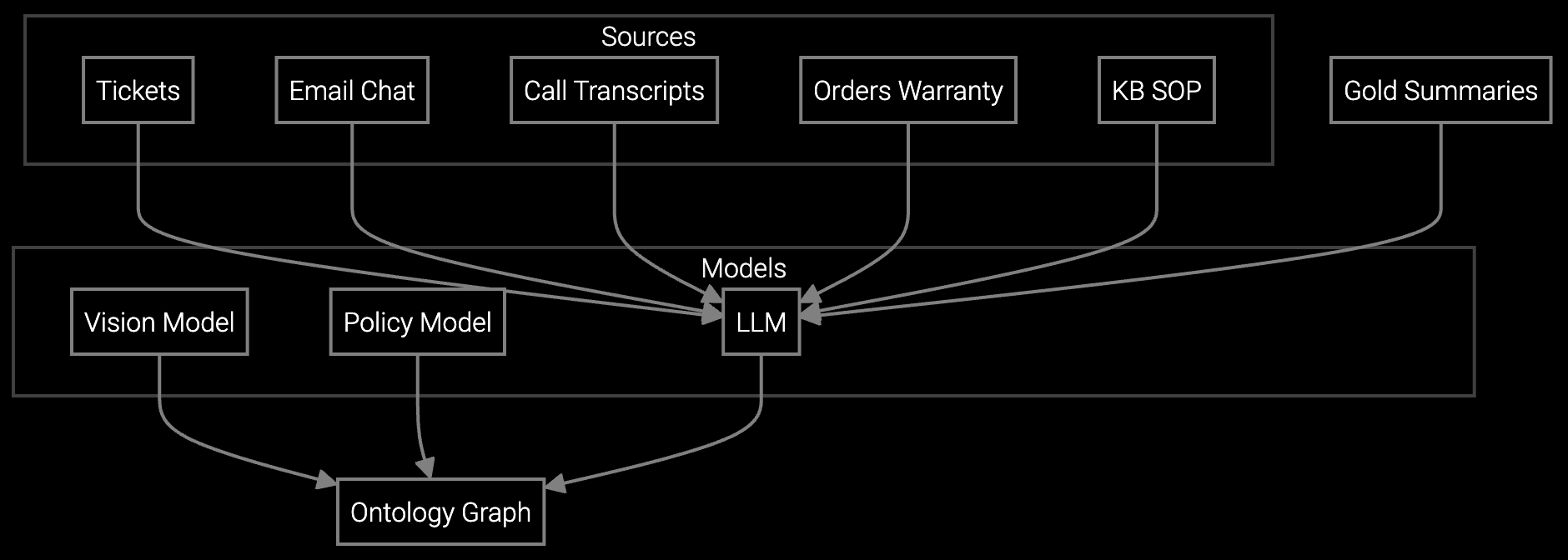
Industrial manufacturers support machinery with 10-30 year service obligations, generating decades of case history, maintenance logs, and technical bulletins. Legacy CRM systems struggle to surface relevant documentation when agents handle cases for aging equipment—manuals are outdated, tribal knowledge is undocumented, and parts data is scattered across SAP, Oracle, and custom databases.
Bruviti's platform ingests structured and unstructured service data from these systems via API connectors, then trains models to correlate failure modes with equipment run hours, operating conditions, and maintenance history. Developers use Python SDKs to build custom classification logic that accounts for equipment vintage, installed base geography, and OEM-specific terminology. Real-time SCADA and PLC telemetry feeds into case context, giving agents predictive insights before customers report issues.
Bruviti provides native SDKs for Python 3.8+ and TypeScript/Node.js. Python SDKs include Jupyter notebook examples for training custom models on historical case data. REST APIs are language-agnostic and support integration with Java, Go, or any HTTP client.
Yes. Bruviti supports on-premises model training using Docker containers that run in your environment. You train models locally using your historical data, then deploy inference endpoints via API. Training data never leaves your infrastructure.
Use pre-built API connectors that authenticate via OAuth and sync case data bidirectionally. Python SDK includes examples for webhook listeners that trigger AI classification when new cases are created. Configuration files map Bruviti's data model to your CRM fields without custom code.
Bruviti's training pipelines export to ONNX format, and model weights are portable. Integration logic lives in your codebase using standard REST calls, not vendor-specific DSLs. You own the trained models and can redeploy them on any inference platform.
Bruviti's streaming API ingests time-series data from OPC-UA, Modbus, or custom protocols. Python SDKs include correlation functions that match equipment serial numbers in case records to telemetry streams, surfacing anomalies and predictive alerts in agent UI.

Understanding and optimizing the issue resolution curve.

Software stocks lost nearly $1 trillion in value despite strong quarters. AI represents a paradigm shift, not an incremental software improvement.

Function-scoped AI improves local efficiency but workflow-native AI changes cost-to-serve. The P&L impact lives in the workflow itself.
Talk to our integration team about Python SDK access and API sandbox environments.
Request Developer Access