Hyperscale environments demand four-nines availability—but fragmented tools and manual telemetry review slow resolution when seconds count.
Bruviti deployment data shows AI-driven remote diagnostics cut duplicate investigations 50% while reusing proven fixes 3x. The bottleneck is not headcount, it is engineers re-solving incidents others already closed. Connecting case history into one searchable layer means data center teams resolve known faults from prior fixes instead of starting every investigation cold.
Support engineers spend hours parsing BMC logs and IPMI sensor data across thousands of nodes. Each remote session requires switching between multiple vendor-specific tools, slowing diagnosis and extending mean time to resolution.
Different server generations, storage arrays, and cooling systems each require separate remote access platforms. Engineers lose time context-switching between tools instead of focusing on problem-solving, driving up support costs per incident.
When remote diagnosis stalls, support engineers escalate to senior specialists or request on-site visits—even for issues resolvable remotely with better diagnostic visibility. These escalations inflate support costs and delay customer resolution.
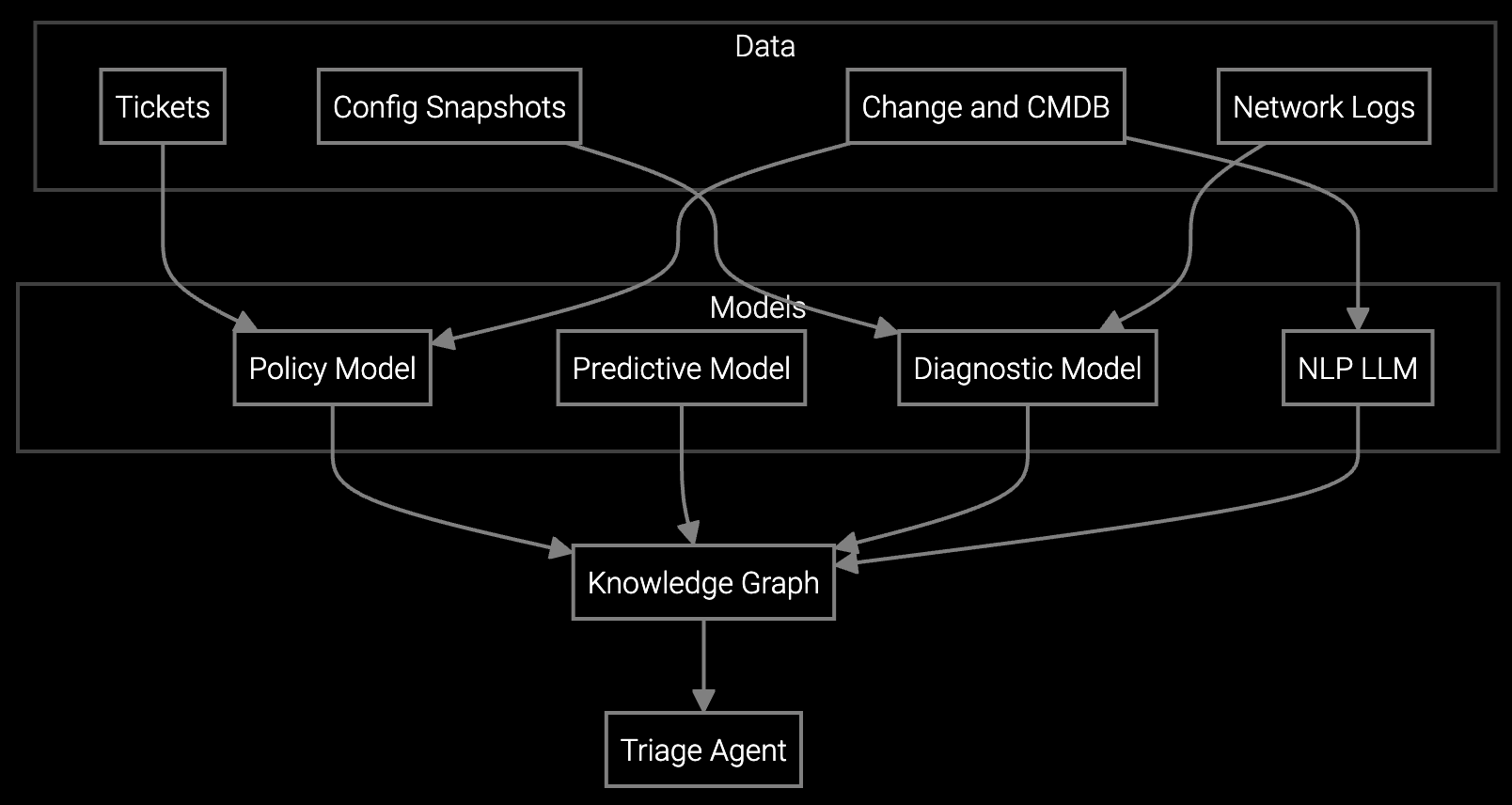
Bruviti's platform ingests telemetry from BMC, IPMI, and storage controllers across heterogeneous data center infrastructure, normalizing data into a single diagnostic view. The AI correlates thermal events, power anomalies, and memory errors in real time, surfacing root cause patterns that would take engineers hours to identify manually.
For executives managing multi-site data center operations, this translates into measurable margin protection. Remote resolution rates climb as support engineers gain immediate diagnostic clarity, reducing expensive escalations and protecting SLA commitments. The platform learns from every resolved session, continuously improving its pattern recognition to handle the long tail of complex issues that typically stall remote support.
Data center OEMs face a diagnostic complexity unique to their scale. A single customer deployment may include tens of thousands of servers spanning multiple hardware generations, each producing BMC telemetry, IPMI sensor data, and storage controller logs. When a customer reports degraded performance or thermal anomalies, support engineers must correlate signals across compute, cooling, and power systems—often without direct visibility into the full infrastructure state.
Traditional remote support tools were designed for single-device troubleshooting, not fleet-level pattern detection. Engineers spend hours manually comparing log files, checking firmware versions, and ruling out configuration drift across hundreds of nodes. This manual approach cannot keep pace with hyperscale operations, where even a 0.1% hardware failure rate translates into dozens of incidents daily requiring rapid remote diagnosis.
Remote diagnostics stall when support engineers lack unified visibility across server BMC data, storage telemetry, and cooling system sensors. Tool fragmentation forces engineers to log into multiple vendor-specific platforms during a single troubleshooting session, slowing root cause identification. Manual correlation of thermal events, power anomalies, and memory errors across thousands of nodes consumes hours that hyperscale SLAs cannot afford.
AI platforms analyze patterns across historical telemetry data to surface root causes that manual log review would miss. When a support engineer opens a remote session, the AI has already correlated BMC logs, IPMI sensor readings, and firmware versions to identify probable failure modes. This diagnostic acceleration allows frontline engineers to resolve issues previously requiring senior specialist escalation, reducing support costs and improving resolution velocity.
Data center OEMs typically achieve 35-45% reduction in average remote session duration within the first year, directly improving support engineer productivity. Escalation rate reductions of 50%+ protect margins by avoiding expensive specialist labor. The compounding effect appears in improved SLA performance—fewer customer downtime penalties and stronger contract renewal rates when four-nines availability commitments are consistently met.
Yes. Modern AI platforms ingest telemetry via standard IPMI protocols and vendor-specific BMC APIs without requiring hardware changes. The platform normalizes data from heterogeneous server generations, storage controllers, and cooling systems into a unified diagnostic interface. This preserves existing infrastructure investments while eliminating the tool sprawl that currently slows remote troubleshooting.
Implementation typically begins with a pilot cohort of high-volume server platforms, delivering measurable improvement in remote resolution rates within 60-90 days. Support engineers adopt the system quickly because it reduces the manual correlation work they already perform. The AI learns from every resolved session, continuously expanding its diagnostic coverage to handle more complex failure modes without requiring additional engineer training.

Software stocks lost nearly $1 trillion in value despite strong quarters. AI represents a paradigm shift, not an incremental software improvement.

Function-scoped AI improves local efficiency but workflow-native AI changes cost-to-serve. The P&L impact lives in the workflow itself.
Five key shifts from deploying nearly 100 enterprise AI workflow solutions and the GTM changes required to win in 2026.
Discover how data center OEMs are reducing escalation rates and protecting margins with AI-driven diagnostics.
Schedule Executive Briefing