When legacy machinery fails unexpectedly and the right bearing or seal isn't in stock, production lines halt and your customers pay in downtime.
Bruviti deployment data shows AI demand forecasting cuts stockouts by 40% or more for industrial equipment parts. The model holds A-class SKUs to under 8% MAPE, so planners stop over-ordering safety stock to cover bad forecasts. Fewer stockouts and tighter forecast error mean cash stops sitting in dead inventory.
Equipment failures don't follow schedules. A bearing that typically lasts 5 years might fail in 18 months due to contamination or operational stress. Historical consumption data becomes unreliable when usage patterns shift or new equipment enters the installed base.
Parts spread across regional warehouses, third-party distributors, and local service centers. Your ERP shows zero availability while the needed seal sits 200 miles away in an uncategorized bin. No API connects the systems, so inventory visibility requires manual phone calls.
Industrial equipment runs for decades. Stock too much and you tie up capital in parts that may never sell. Stock too little and a CNC machine from 1998 sits idle waiting for a discontinued motor controller. No formula balances this for long-tail inventory.
The stockout problem isn't a data problem—it's a signal problem. Your SAP or Oracle system holds historical consumption records, but those records don't predict the hydraulic pump failure triggered by temperature swings or the unexpected wear pattern from a production shift change. Bruviti's platform gives you Python SDKs and REST APIs to build ML models that ingest equipment telemetry, service case patterns, and failure mode data alongside your ERP inventory levels.
You train models on your own data and deploy them in your infrastructure. The platform provides pre-trained transformers for industrial equipment text (service notes, failure codes, part descriptions) and time-series forecasting modules for sensor streams. Connect them to your inventory system via API, tune thresholds in code, and push predictions back to your warehouse management system. No black-box recommendations you can't inspect or override.
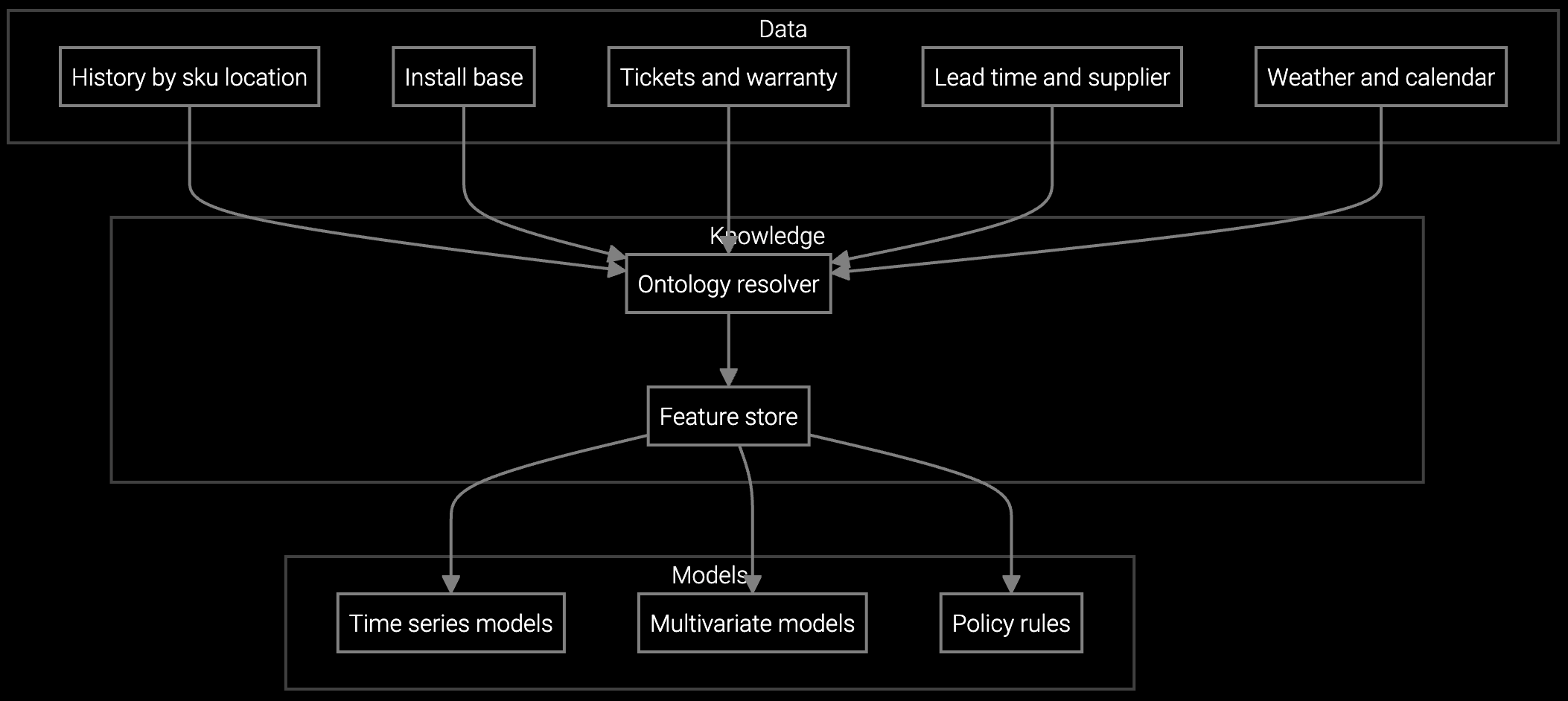
Train regression models on installed base age, run hours, and seasonal production cycles to predict parts consumption by SKU and location.
Build demand forecasts by warehouse using equipment failure probability curves and service appointment schedules to optimize stock levels.
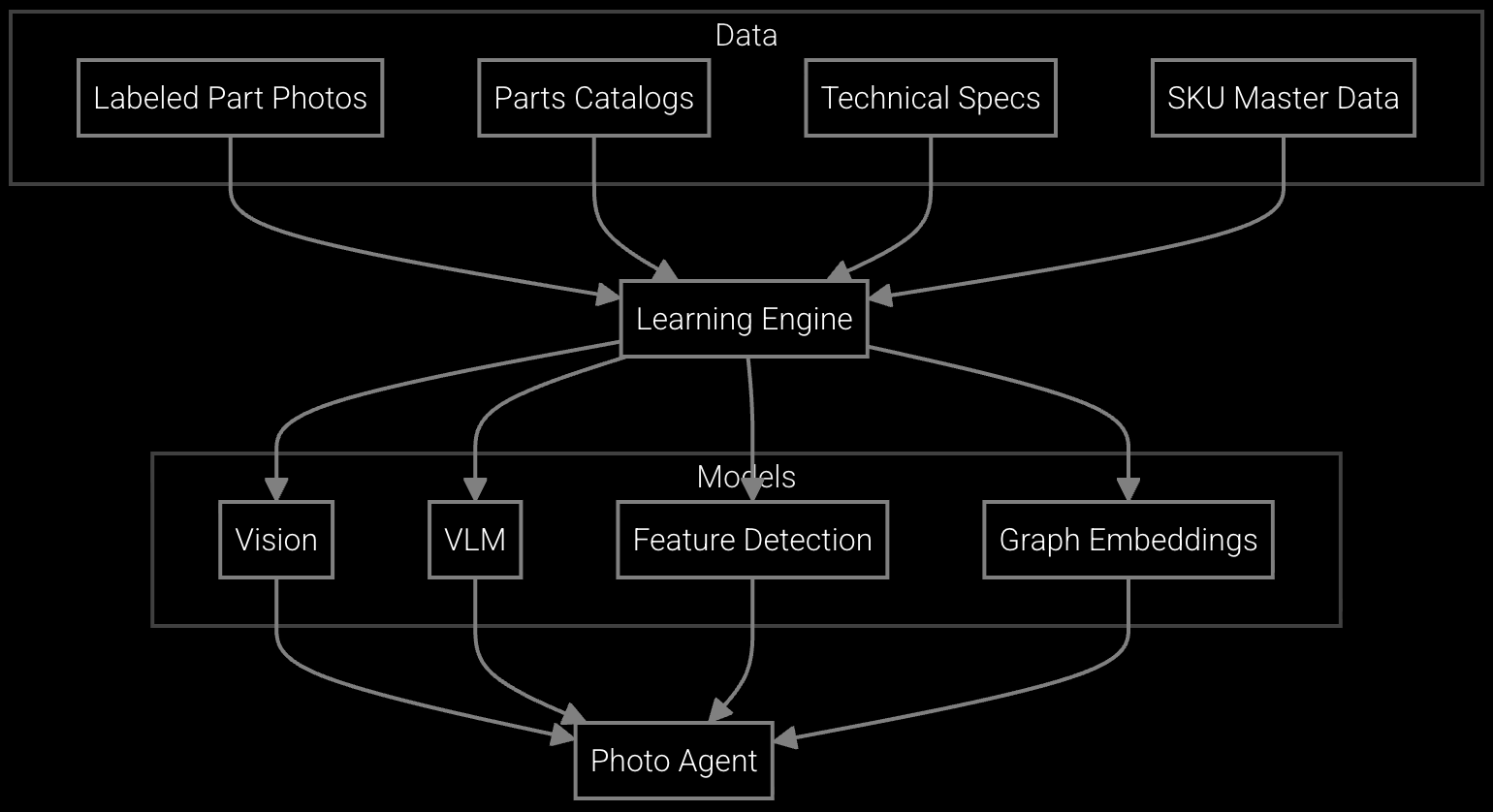
Deploy vision models that extract part numbers from component photos and match them to inventory records, reducing lookup time for obsolete parts.
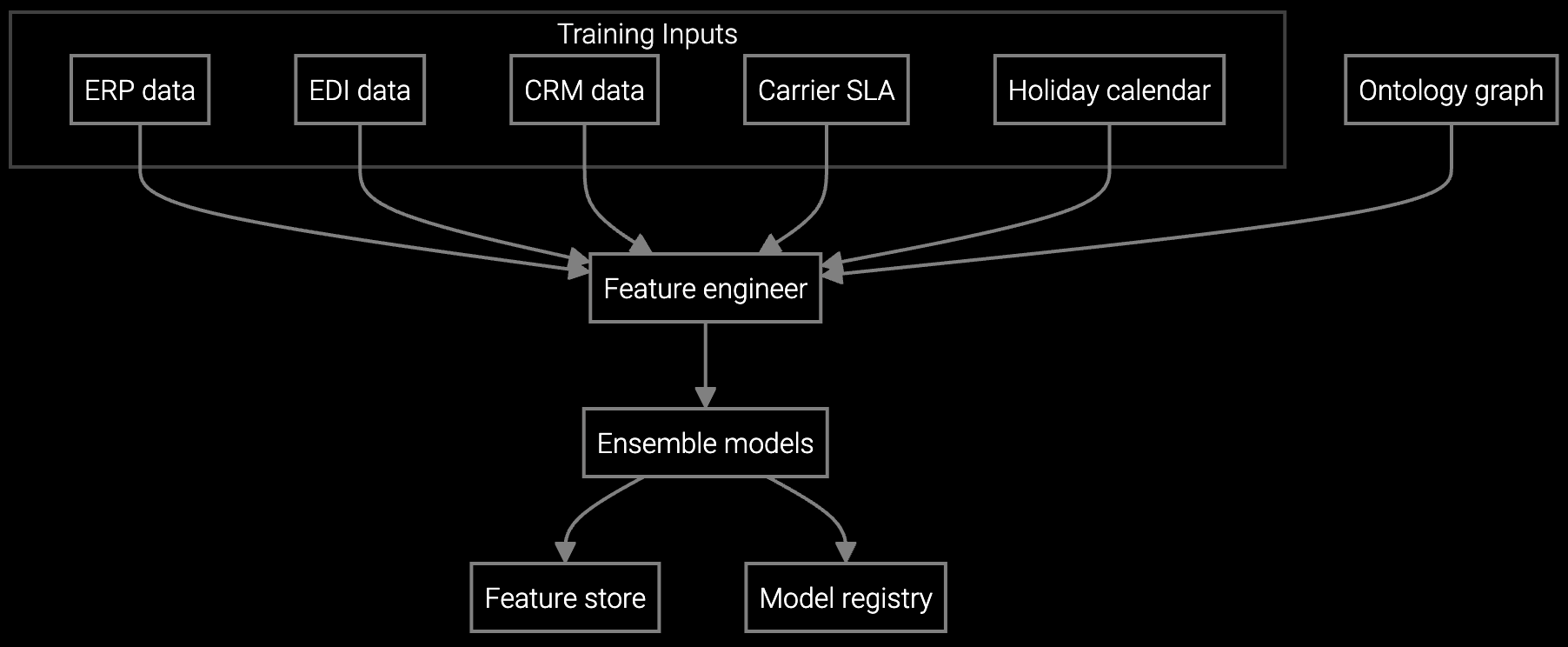
Industrial manufacturers run parts operations across decades-old ERP systems, regional warehouse management platforms, and third-party distributor networks. Your integration challenge isn't data volume—it's data fragmentation. Pumps manufactured in 1992 use different part numbering schemes than current models. Service notes reference obsolete codes. SCADA telemetry from different equipment generations arrives in incompatible formats.
Build connectors using Bruviti's Python SDK to normalize this heterogeneity. Extract failure mode text from service case notes, map it to equipment model hierarchies, and join it with sensor time-series streams. Train your forecasting models on the unified dataset, then deploy predictions back through REST APIs that your Oracle or SAP system can consume. You own the data pipeline, the model weights, and the deployment infrastructure.
The platform includes NLP models pre-trained on industrial equipment documentation to extract part relationships from scanned manuals, legacy service bulletins, and historical case notes. You can fine-tune these models on your specific equipment families. For parts with sparse failure data, the system uses transfer learning from similar equipment types to generate initial forecasts, which improve as more data accumulates.
All integrations use standard REST APIs and Python connectors that you control. If you migrate from SAP to Oracle or swap warehouse systems, you rewrite the connector layer without retraining models. The ML pipeline operates independently of your transactional systems. You can version and test new connectors in parallel before cutover, avoiding disruption to existing forecasts.
Yes. Every forecast includes confidence intervals and contributing factors (e.g., failure rate trends, seasonal patterns, equipment age cohorts). You access this through API responses or a dashboard. Override logic runs in your code—set minimum stock levels, blacklist certain recommendations, or inject manual adjustments for planned maintenance events. The platform doesn't enforce recommendations; it generates predictions you integrate into your inventory rules.
Substitute matching uses equipment compatibility graphs built from installation records, service case success rates, and part specification similarity. For obsolete parts, the system identifies functionally equivalent alternatives based on dimensional specs, material properties, and historical substitution patterns. Accuracy varies by equipment complexity—simple mechanical parts achieve 87% match accuracy, while specialized electronics require more validation but still surface candidates manual lookup would miss.
Initial deployment focuses on high-impact parts with sufficient failure history—typically 50-200 SKUs. You'll see forecast outputs within 2-3 weeks of connecting data sources. Measurable stockout reduction appears 60-90 days later as the inventory system responds to forecast-driven reorder triggers. Full portfolio coverage for long-tail parts takes 6-12 months as models accumulate enough data on rare failures and seasonal patterns stabilize.

SPM systems optimize supply response but miss demand signals outside their inputs. An AI operating layer makes the full picture visible and actionable.

Advanced techniques for accurate parts forecasting.

AI-driven spare parts optimization for field service.
See the SDKs, review the API documentation, and prototype demand forecasting models on your equipment data.
Schedule Technical Demo