Support agents spend hours hunting through fragmented documentation while customers wait—every minute costs resolution quality and CSAT.
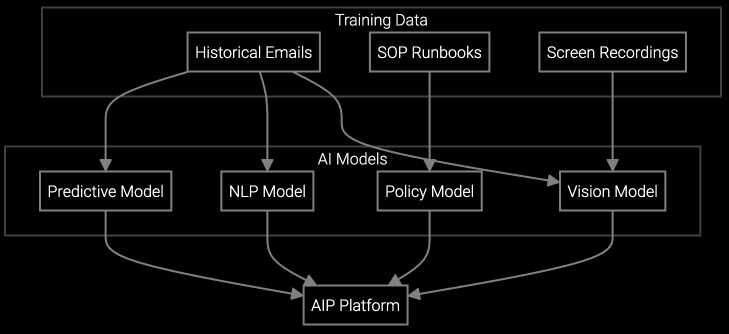
Bruviti deployment data shows AI auto-summarizes 85% of cases and improves first contact resolution 11% in industrial equipment support. Builders solve the knowledge-retrieval bottleneck by indexing manuals, prior tickets, and fault histories into one retrieval layer, so agents stop hunting across systems for the answer mid-call.
Agents search across PDFs, SharePoint folders, legacy wikis, and undocumented tribal knowledge scattered across departments. Each system has different search syntax and outdated indexes.
Different agents find different answers for identical issues depending on which source they search first. Customers receive conflicting guidance on repair procedures and part recommendations.
Agents spend most of their time searching rather than solving. Every minute spent navigating documentation delays first contact resolution and drives up cost per contact.
Bruviti's platform provides Python and TypeScript SDKs that let you index heterogeneous knowledge sources—service manuals, CAD drawings, telemetry streams, historical case notes—into a unified vector store. Your agents query via natural language API calls and retrieve semantically relevant chunks ranked by similarity and recency.
The architecture is headless. You control where the embeddings live, which models process the queries, and how results integrate into your existing CRM or ticketing system. No lock-in to a proprietary UI or closed knowledge base. You train the retrieval model on your domain-specific corpus, tune ranking weights based on case outcomes, and version-control the entire stack.
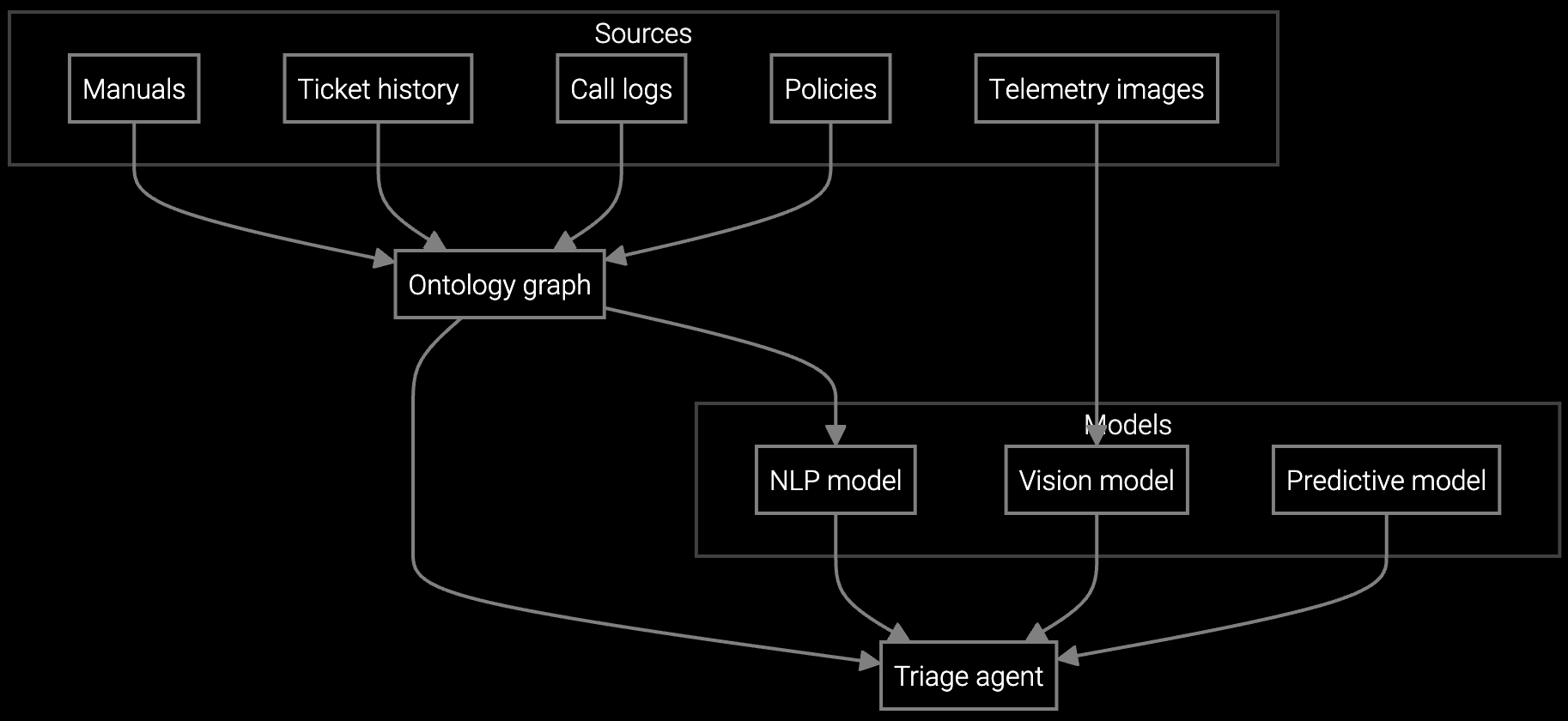
Autonomous case classification correlates equipment telemetry with historical failure modes and routes issues with diagnostic context to reduce agent search time.
Instantly surfaces case history and prior repair attempts from email threads and call transcripts so agents skip manual research.
AI reads customer emails describing CNC vibration issues or turbine alarms, retrieves relevant troubleshooting procedures, and drafts responses using your knowledge base.
Industrial equipment runs for 20+ years. Service manuals written in the 1990s exist as scanned PDFs with no OCR. Troubleshooting guides reference discontinued sensors. Software updates change controller behavior but documentation lags by years.
Agents supporting legacy CNC machines or pumps installed decades ago must reconcile conflicting documentation versions, undocumented field modifications, and tribal knowledge from engineers who have since retired. AI-powered retrieval indexes all versions, flags conflicts, and surfaces the most relevant context based on equipment serial number and installed software revision.
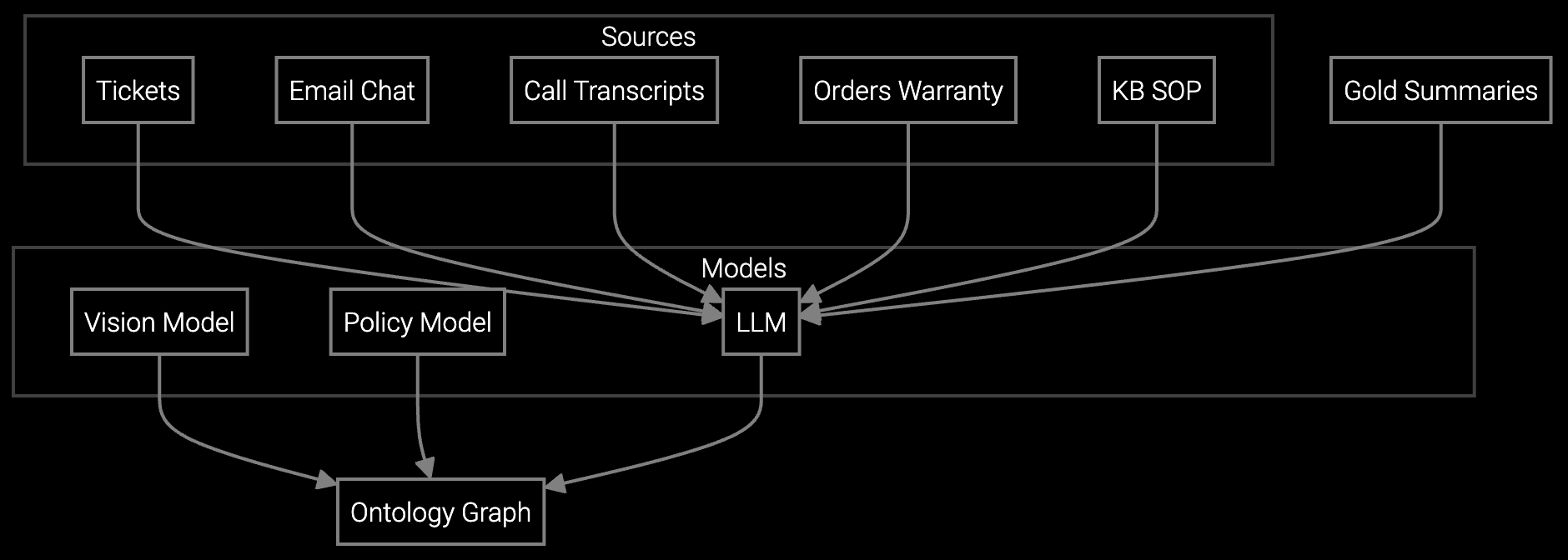
The platform uses optical character recognition (OCR) for scanned documents and layout parsing models that extract text from multi-column technical manuals. You can preprocess with custom scripts via the Python SDK to normalize formatting before indexing.
Yes. Bruviti provides open retraining pipelines that let you fine-tune embedding models on your historical cases. You control the training data, hyperparameters, and evaluation metrics. No data leaves your infrastructure unless you choose to use cloud-hosted embeddings.
The retrieval API ranks results by relevance and recency, but also flags known conflicts. You define precedence rules in the configuration—for example, prioritize field service bulletins over original manuals, or weight recent case outcomes higher than outdated guides.
The platform is API-first. You call the retrieval endpoint from your CRM's custom scripting layer or build a lightweight middleware service that queries the knowledge API and injects results into agent screens. No UI replacement required—agents continue using familiar tools.
Track average handle time (AHT), first contact resolution (FCR), and escalation rate before and after deployment. Tag cases where agents used AI retrieval and compare resolution speed and CSAT scores against manual search baselines. Expect measurable AHT reduction within 60-90 days.

Understanding and optimizing the issue resolution curve.

Software stocks lost nearly $1 trillion in value despite strong quarters. AI represents a paradigm shift, not an incremental software improvement.

Function-scoped AI improves local efficiency but workflow-native AI changes cost-to-serve. The P&L impact lives in the workflow itself.
See how Bruviti's API-first architecture solves knowledge bottlenecks without vendor lock-in.
Talk to an Engineer