Agents waste 40% of call time hunting across disconnected systems for model-specific troubleshooting steps and warranty rules.
Appliance support teams cut average handling time 22% with Bruviti, per Bruviti deployment data, by replacing manual knowledge hunts with retrieval that surfaces the right fix instantly. Builders connect the case-summary layer to existing knowledge bases so agents stop searching across systems and get one grounded answer per case.
Agents toggle between CRM, PDF manuals, SharePoint, and legacy warranty databases. Each system requires different search syntax and credentials. Critical troubleshooting steps get lost in the navigation.
Keyword search returns outdated articles, duplicate entries, and irrelevant content. Agents can't filter by model year, refrigerant type, or warranty status. Accuracy drops as product lines expand.
Agents must manually correlate error codes from IoT telemetry with service bulletins and part availability. No automated context injection. Every lookup interrupts the customer conversation.
The Bruviti platform provides RESTful endpoints that federate queries across your existing knowledge repositories without requiring data migration. Python and TypeScript SDKs let you build custom retrieval logic that surfaces the right content based on equipment model, symptom keywords, and customer entitlement status. The platform ingests structured data from your CRM, parses unstructured PDFs from service manuals, and indexes historical case resolutions to build a semantic search layer.
Your development team controls the integration points and customization logic. The platform handles the heavy lifting of natural language understanding, context ranking, and real-time updates when new bulletins or parts catalogs are published. API responses include confidence scores and source citations so your ticketing system can display them inline without requiring agents to click through to external documents.
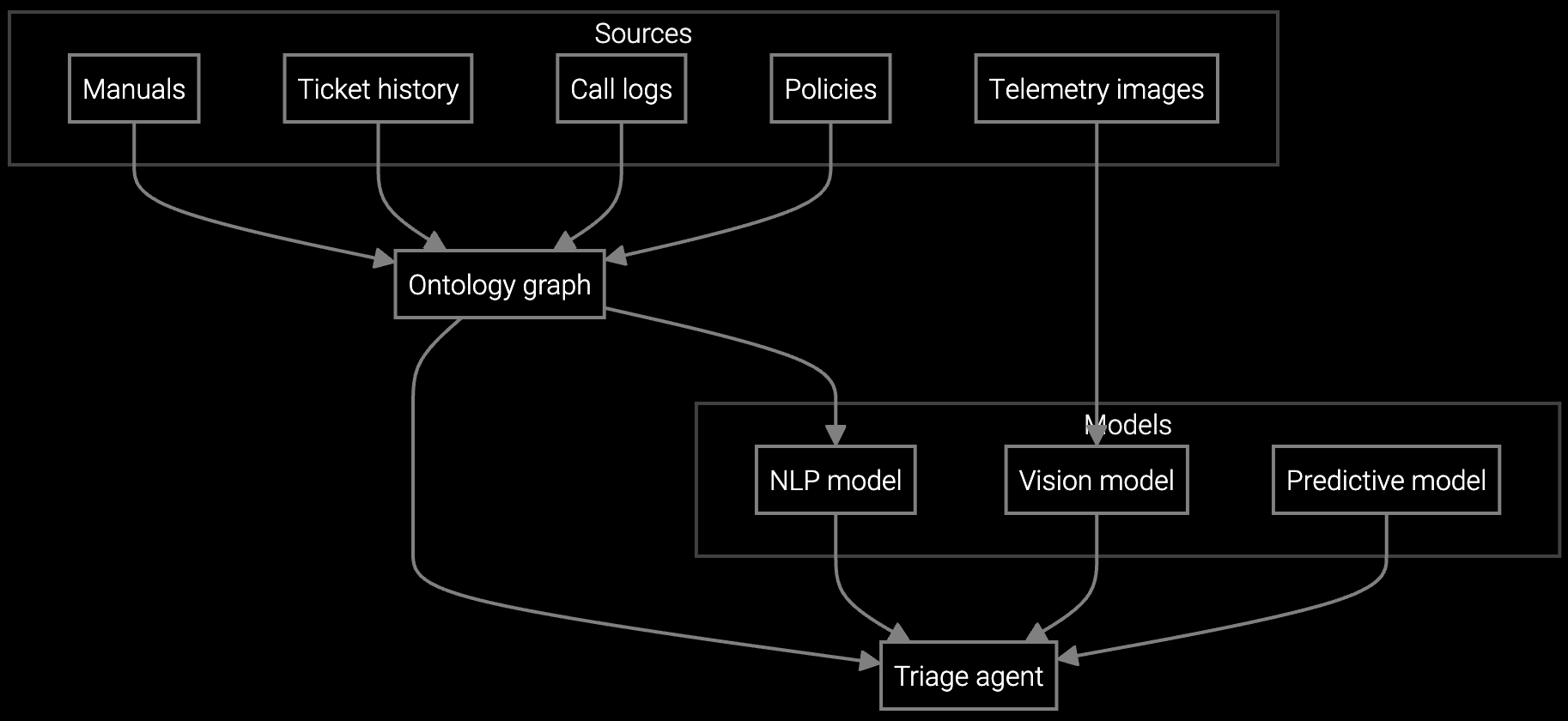
Automatically classifies refrigerator compressor failures by correlating customer-reported symptoms with IoT temperature logs and routes to the correct warranty tier.
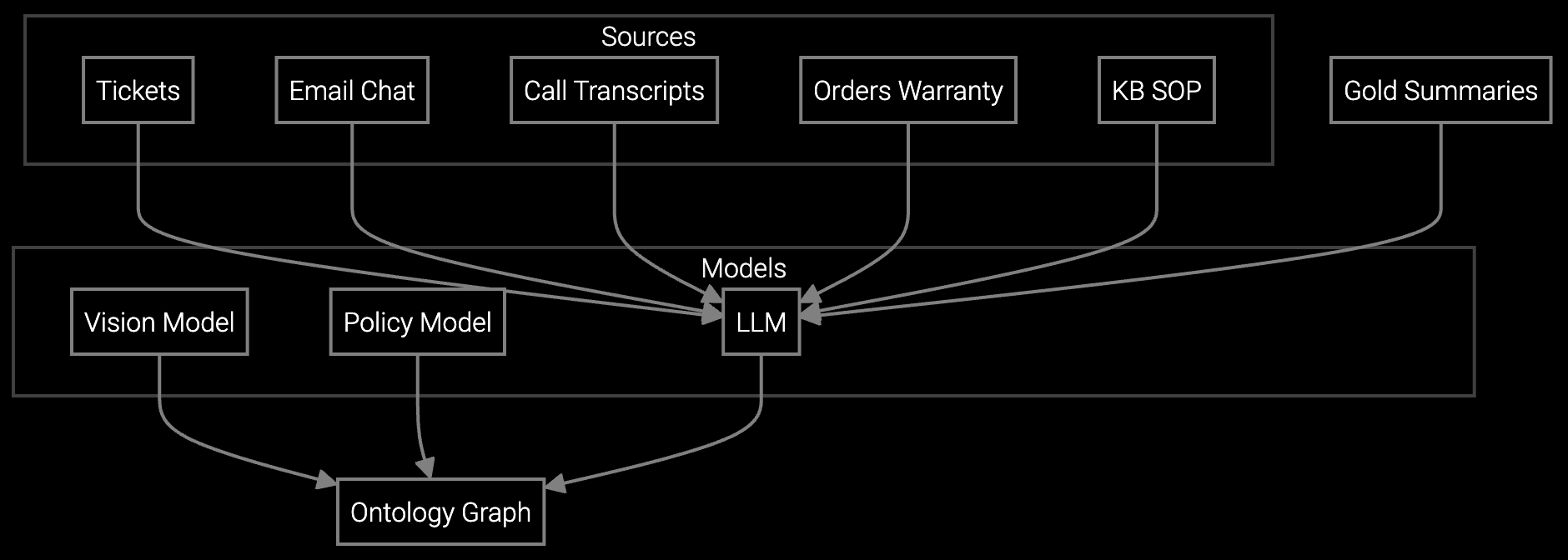
Generates structured summaries from multi-channel case histories so agents understand prior HVAC repair attempts without reading 15 chat transcripts.
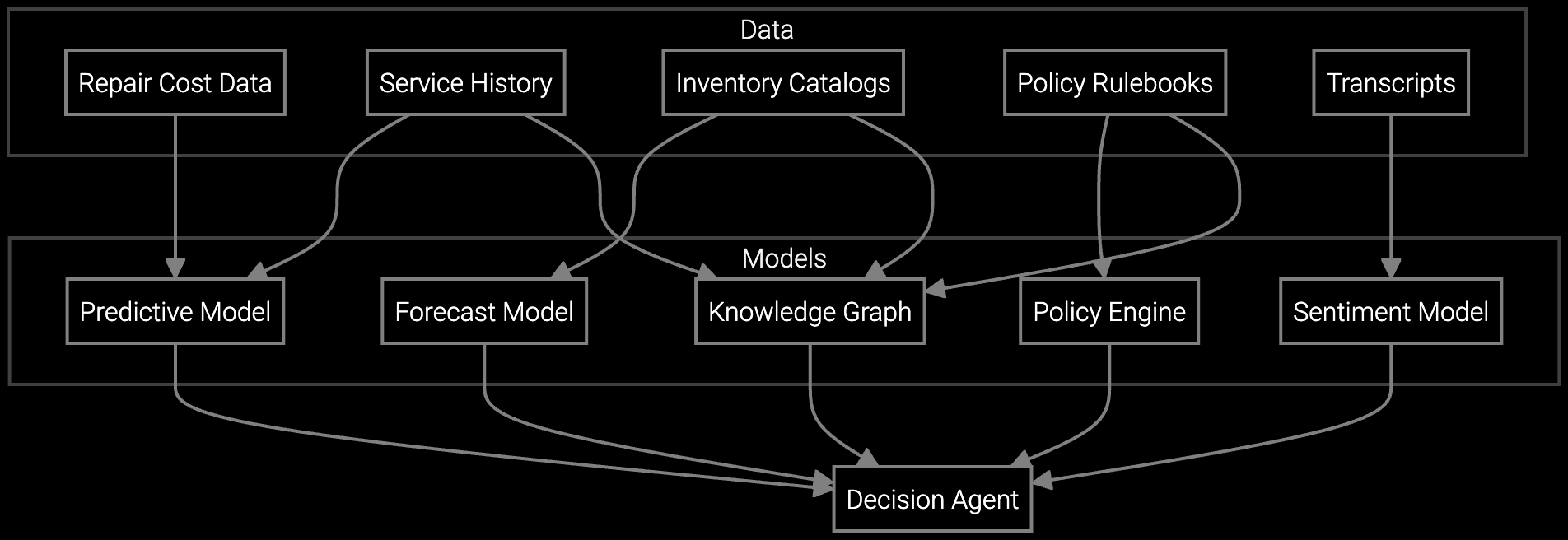
Analyzes dishwasher part costs, equipment age, and failure probability to recommend whether to authorize a repair or offer a replacement unit under warranty.
Appliance manufacturers support decades of product models with varying refrigerants, compressor types, control board revisions, and regional voltage standards. Agents need instant access to model-specific wiring diagrams, EPA-compliant refrigerant handling procedures, and warranty coverage rules that differ by purchase date and retailer. IoT-connected appliances generate diagnostic error codes, but legacy products require symptom-based troubleshooting trees.
Peak demand during HVAC season means agents handle 3x normal case volume with the same knowledge infrastructure. Self-service deflection depends on surfacing the correct troubleshooting steps before customers call. NFF rates spike when agents authorize parts replacements based on incomplete diagnostic information from disconnected knowledge sources.
The platform polls your document repositories on a configurable schedule or accepts webhook notifications when new PDFs are published. Updated content is re-indexed within minutes and immediately available via the search API. You control versioning logic so agents can still reference historical bulletins for older equipment.
Yes. The Python SDK exposes filter parameters that let you build category-specific retrieval flows. For example, HVAC queries can prioritize refrigerant compatibility checks while dishwasher queries prioritize control board diagnostics. Your team writes the routing logic and the platform executes the filtered searches.
The platform uses field mapping configuration files that your team maintains. When CRM schemas evolve, you update the mappings and redeploy without platform vendor involvement. The SDK includes validation tools to test mappings before production deployment.
The API accepts role-based access tokens that you generate from your identity provider. Your team defines which content repositories are accessible to which agent tiers. The platform enforces access control at query time based on the token claims.
Yes. The platform supports containerized deployment on your Kubernetes infrastructure. You retain full data sovereignty and control network access policies. Cloud-hosted options are available for teams that prefer managed infrastructure.

Transforming appliance support with AI-powered resolution.

Understanding and optimizing the issue resolution curve.

Software stocks lost nearly $1 trillion in value despite strong quarters. AI represents a paradigm shift, not an incremental software improvement.
Get sandbox credentials and API documentation to evaluate retrieval accuracy against your actual case data.
Request Developer Access