Router firmware updates and 5G rollouts spike demand unpredictably—custom models or vendor platforms both carry risk.
Bought AI parts forecasting delivers ≤8% MAPE on A-class SKUs and ≤12% on B/C SKUs, per Bruviti deployment data, accuracy a build team rarely reaches before model and data work compound. The strategic call: buy the forecasting core that already hits these error rates, build only the integrations unique to your network equipment stack.
Building custom demand forecasting from scratch gives full control over models and features. But network OEMs spend 18-24 months training foundation models on telemetry before reaching production accuracy.
Vendor platforms deliver fast deployment but proprietary APIs create switching costs. When customization needs arise, closed systems require expensive professional services and multi-quarter roadmap commitments.
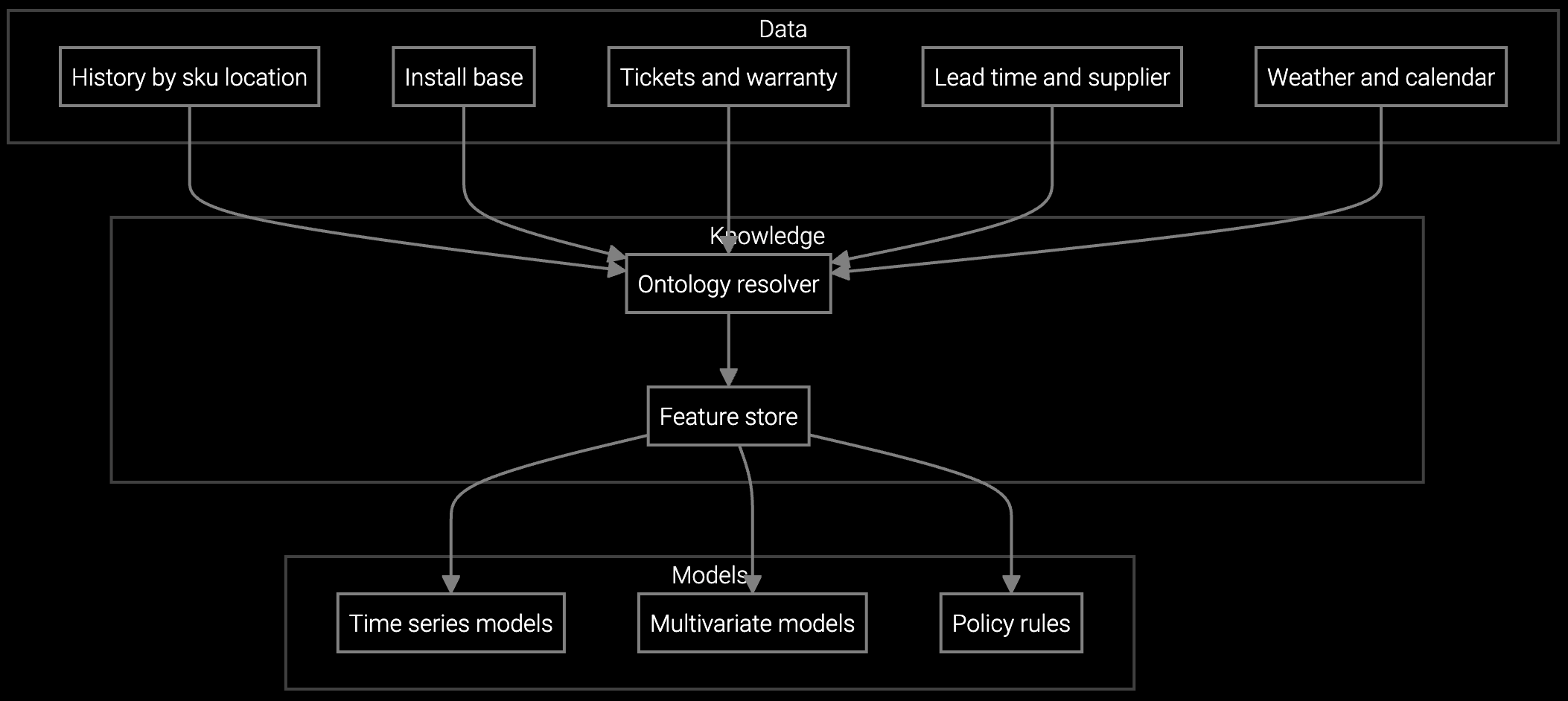
RMA data lives in one system, warranty claims in another, install base telemetry in a third. Both build and buy approaches struggle when parts demand signals are fragmented across legacy SAP, Oracle, and custom databases.
API-first platforms like Bruviti split the difference. Pre-trained models handle baseline demand forecasting across router, switch, and optical transport portfolios—delivering production accuracy in weeks instead of years. Python and TypeScript SDKs expose the full model layer, letting engineering teams extend forecasting logic for firmware-specific failure modes or geographic demand patterns without waiting on vendor roadmaps.
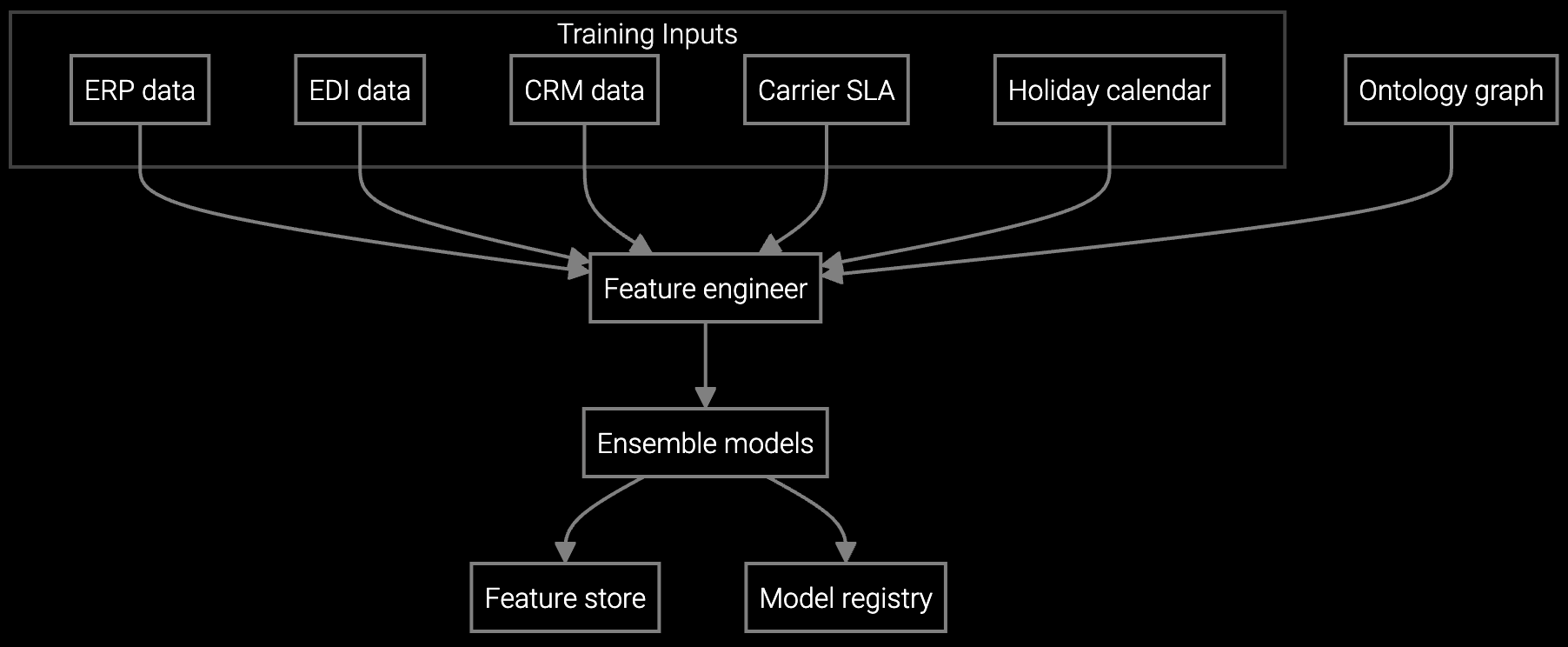
The architecture separates data integration from model training. Standard connectors pull from SAP inventory, Oracle service, and SNMP telemetry streams—no custom ETL required. But when you need to incorporate proprietary failure signatures from your NOC logs, you own the integration code and the resulting model weights. The platform provides the foundation; your team builds the differentiation on top.
Projects router and switch component consumption based on installed base age, firmware versions, and network expansion cycles.
Optimizes stocking levels across regional depots using ML models trained on RMA patterns and service ticket history.
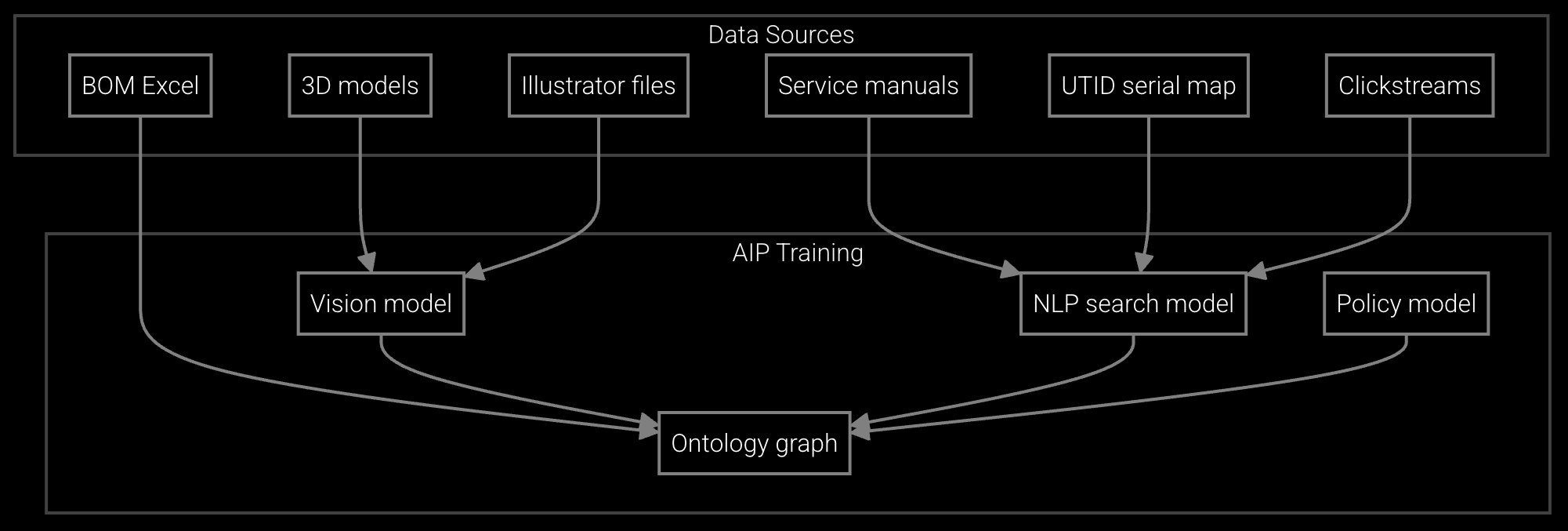
Automatically generates and maintains parts catalogs from engineering BOMs, handling EOL transitions and substitute mappings.
Network equipment lifecycles create unique forecasting challenges. Enterprise routers stay deployed for 7-10 years, but firmware vulnerabilities force sudden refresh cycles when CVEs hit. Carrier-grade DWDM systems run for 15+ years with power supply and optics failures following predictable curves—until a hyperscaler announces a new region build and demand spikes 300% overnight.
Traditional ERP forecasting can't handle these dual time horizons. You need models that learn slow-burn component aging from MTBF data while detecting rapid demand shifts from network buildout announcements and firmware EOL schedules. That requires integrating warranty databases, NOC telemetry, and external market signals—data that rarely lives in a single system.
Standard connectors for SAP ECC, S/4HANA, and Oracle E-Business Suite typically deploy in 2-4 weeks. The platform includes pre-built adapters for common inventory and service schemas. Custom extensions via Python SDK add 1-2 weeks depending on data complexity.
Yes. The Python SDK exposes the full training pipeline. You can fine-tune base models on proprietary NOC logs, custom telemetry, or internal failure classification schemes. Model weights stay in your environment—no data leaves your VPC or data center without your explicit approval.
All integrations use Apache 2.0 licensed SDKs with open APIs. You own the integration code and can export trained models in standard formats (ONNX, TensorFlow SavedModel). There are no proprietary lock-in mechanisms—if you build the capability internally, you can migrate without rewriting integrations.
The platform combines time-series models for baseline demand with event detection for anomalies. You can ingest external signals (firmware EOL announcements, hyperscaler expansion news) via API to trigger demand adjustments. The SDK lets you define custom event weights based on historical impact to your specific product lines.
No dedicated ML team required for standard use cases. Base models auto-retrain on new data. For custom extensions—like incorporating proprietary telemetry features—a data engineer familiar with Python can build and deploy using the SDK. Typical extension projects take 2-4 weeks with existing engineering resources.

SPM systems optimize supply response but miss demand signals outside their inputs. An AI operating layer makes the full picture visible and actionable.

Advanced techniques for accurate parts forecasting.

AI-driven spare parts optimization for field service.
See how API-first forecasting integrates with your existing data infrastructure without vendor lock-in.
Schedule Technical Review