Hyperscale demands and rapid hardware refresh cycles make parts forecasting errors costly—the wrong architecture compounds the problem.
Bruviti deployment data shows the parts blueprint library reaches 85% auto-extraction accuracy, the build-vs-buy benchmark data center OEMs should weigh. Reaching that accuracy in-house means building document parsing, entity resolution, and a searchable catalog. Deployment data attributes the accuracy to a purpose-built extraction pipeline already proven across parts datasets.
Custom ML pipelines promise control but require sustained AI expertise, IPMI parser maintenance, and continuous model retraining as hardware generations evolve. Most data center OEMs underestimate ongoing costs.
Monolithic service platforms offer fast deployment but trap inventory data in proprietary schemas. You can't extend forecasting logic or integrate with existing SAP workflows without expensive professional services.
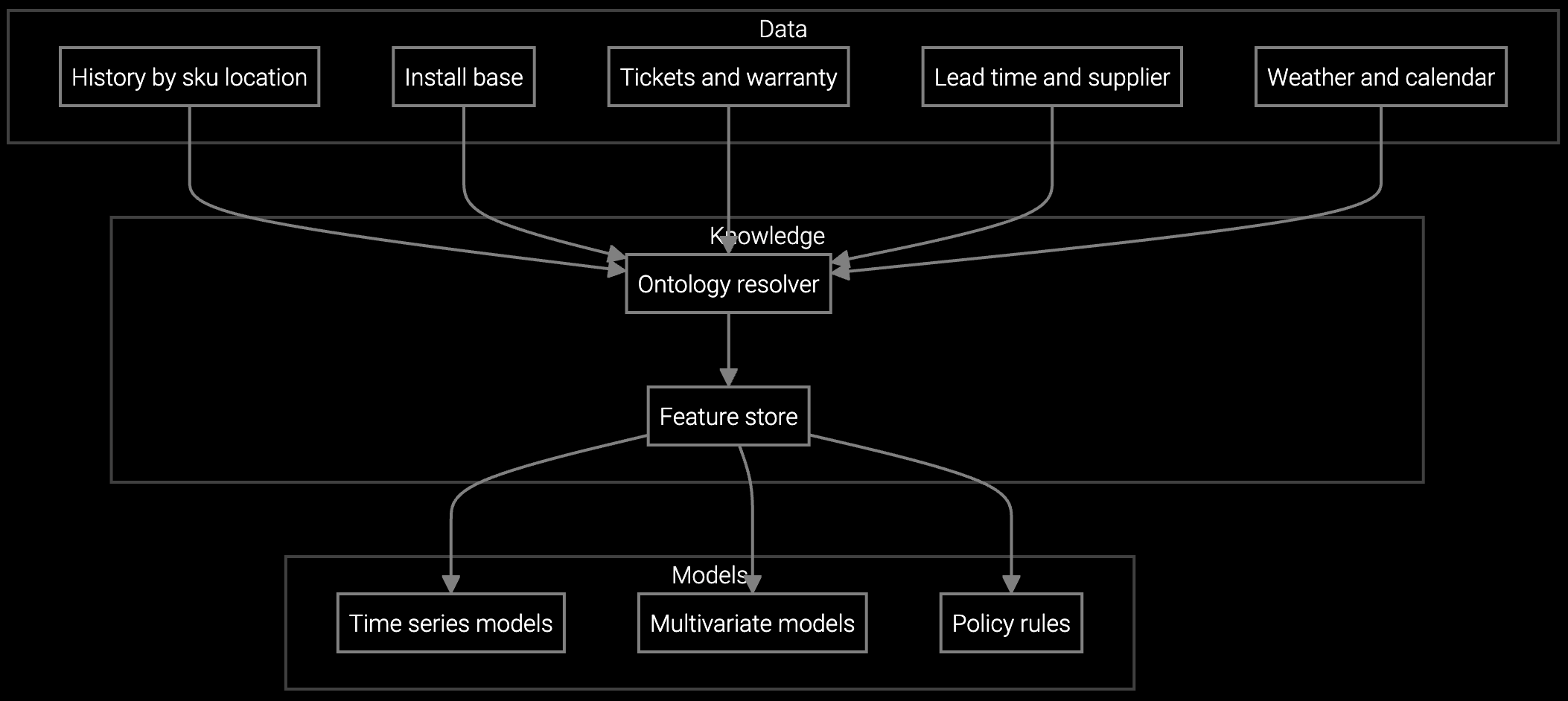
Data center OEMs operate diverse inventory systems across regions. Any parts intelligence strategy must ingest BMC telemetry, RMA history, and supplier lead times without rewriting ETL pipelines every quarter.
The hybrid approach combines pre-built foundation models with open integration architecture. Bruviti provides Python SDKs for demand forecasting and substitute parts matching, eliminating the 18-month model training cycle. You own the deployment pipeline and can customize forecasting logic without waiting for vendor roadmaps.
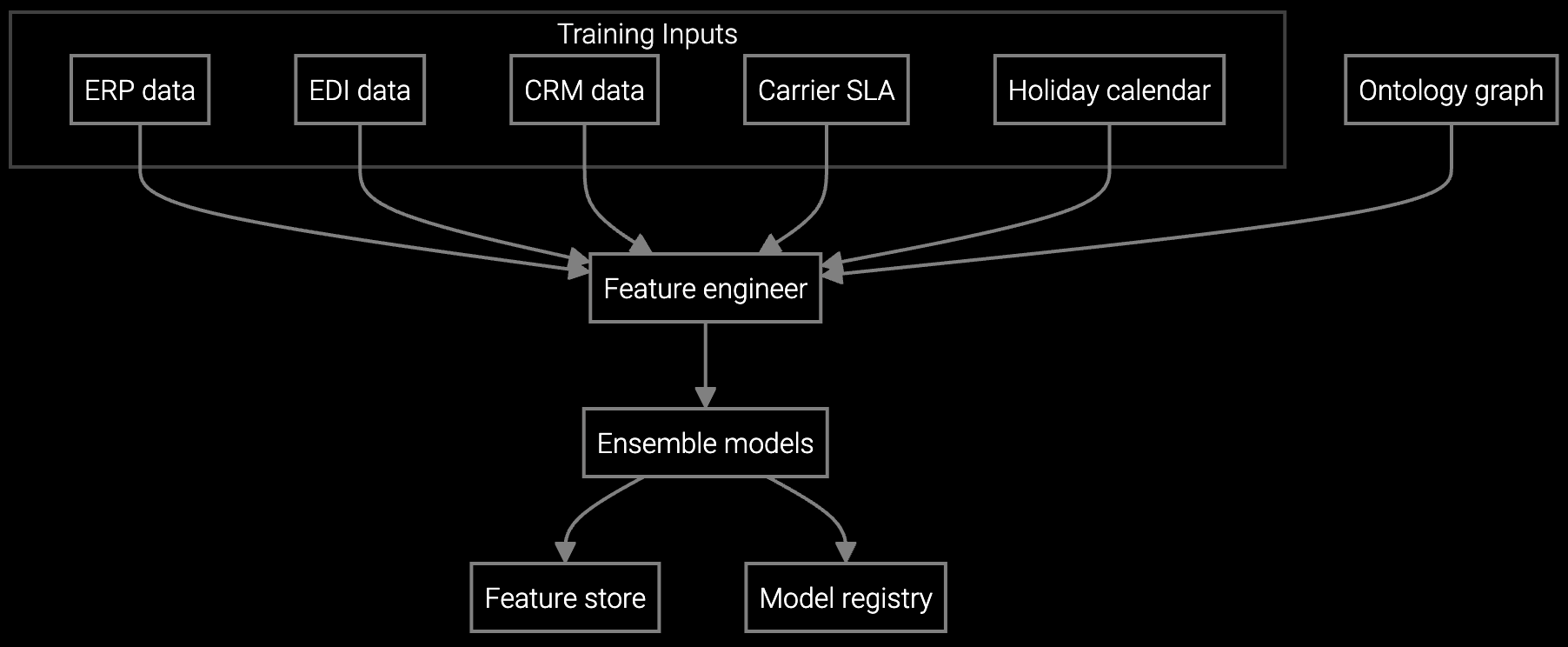
This architecture addresses the data center OEM's core constraint: hardware diversity at hyperscale. The platform ingests BMC telemetry, IPMI logs, and RMA patterns through standard REST APIs, learning failure signatures across server generations. Your team extends the models with proprietary data—cooling patterns, regional power costs, customer SLA tiers—using TypeScript connectors that integrate with existing Oracle or SAP inventory systems.
Forecasts SSD and PSU failures by server generation and data center region using BMC telemetry and historical RMA patterns.
Optimizes regional stocking levels for high-turnover components like DIMMs and NVMe drives based on installed base age and usage intensity.
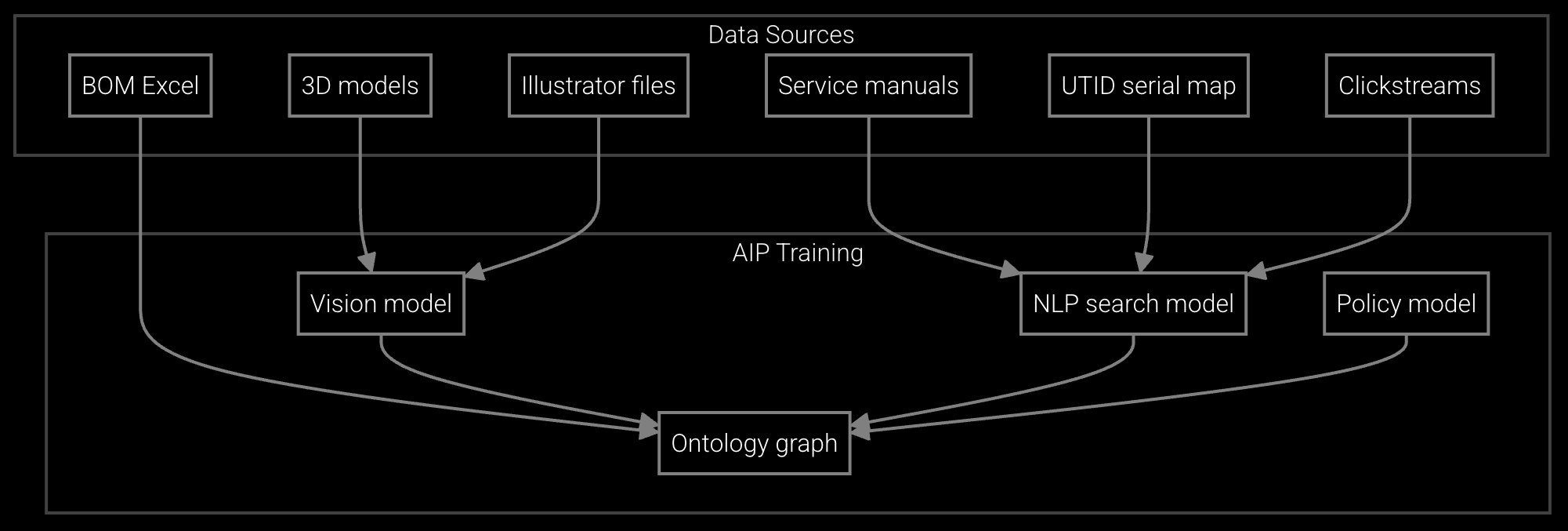
Generates substitute parts matrices from engineering BOMs and service records, enabling depot teams to identify compatible alternatives when first-choice parts are unavailable.
Data center OEMs manage parts inventories across dozens of regions for equipment spanning five hardware generations. A single hyperscale customer might operate 200,000 servers with six different CPU architectures and four storage configurations. Traditional ERP demand planning can't capture the nuances—RAID controller failures spike in hot climates, SSD wear accelerates under specific workload patterns, PSU failures correlate with grid instability.
The API-first strategy lets your inventory team start with high-impact, high-certainty predictions: SSD and DIMM failures for your top three server SKUs. Python SDKs connect to your existing IPMI data lake. Models learn failure signatures from two years of BMC logs. Your team validates forecast accuracy against actual RMA volumes, then extends the models to cooling systems and PDUs using the same integration pattern.
Yes. Bruviti provides Python SDKs with full retraining capabilities. You control the training pipeline, feature engineering, and model versioning. The platform learns from your IPMI logs, RMA history, and environmental data without sending proprietary patterns to external services.
The platform exposes all forecasting logic through REST APIs with OpenAPI specifications. Your demand planning workflows call these endpoints but don't depend on proprietary schemas. If you later move forecasting in-house, you migrate the API calls to your own models without rewriting upstream inventory systems.
The platform ingests standard IPMI event logs, SNMP traps, and structured RMA records via REST endpoints. Most data center OEMs complete integration in 4-6 weeks using TypeScript connectors that map existing data lake schemas to the API format. No ETL rewrite needed.
Absolutely. The SDK allows you to inject custom features into the forecasting pipeline. Add PUE data, regional power costs, or customer service tier as model inputs. Train on these features using your historical data to improve forecast accuracy for your specific deployment patterns.
Building requires sustained AI team capacity, IPMI parser maintenance, and 18-24 months to production. Hybrid approach delivers working models in 3 months while preserving customization rights. You avoid the build's opportunity cost without accepting a closed platform's constraints.

SPM systems optimize supply response but miss demand signals outside their inputs. An AI operating layer makes the full picture visible and actionable.

Advanced techniques for accurate parts forecasting.

AI-driven spare parts optimization for field service.
Review API documentation, test Python SDKs against your IPMI data, and map integration points with your engineering team.
Schedule Technical Review