Five-nines uptime demands make every truck roll count—quantify where AI cuts dispatch costs and accelerates technician effectiveness.
AI field service cuts repeat truck rolls 30% and adds 10 to 15 first-time-fix percentage points, per Bruviti deployment data. The dollar math is direct: each eliminated return visit removes a dispatch cost, and the parts-prediction layer also trims parts returns 25%, compounding the per-job savings across a network equipment install base.
Technicians arrive on-site without the correct replacement module or lack firmware context, requiring a second dispatch. Router and switch failures involve multiple subsystems—without telemetry-driven root cause analysis, first visits diagnose rather than resolve.
SLA penalties for network downtime force OEMs to expedite technician dispatch at 2-3x standard cost. Without AI pre-filtering, NOC teams escalate to field service before exhausting remote diagnostics, inflating truck roll volume unnecessarily.
Senior technicians who understand DWDM optical transport or carrier-grade routing protocols are retiring. Their diagnostic heuristics—how to isolate PoE failures from firmware bugs—exist only in memory, not in transferable systems that scale across the workforce.
Bruviti's platform ingests SNMP traps, syslog streams, and configuration snapshots from deployed routers, switches, and firewalls to build predictive dispatch models. Python-based SDKs let you train custom failure classifiers on your equipment's telemetry patterns—optical signal degradation in DWDM systems, thermal anomalies in high-density switches, or CVE-correlated crash signatures.
Headless APIs integrate with SAP Field Service Management and ServiceMax without vendor lock-in. Your data engineers maintain full control: retrain models on new firmware versions, inject custom business rules for warranty status or contract SLAs, and audit model decisions through transparent scoring APIs. The system pre-stages parts based on failure mode probabilities and routes only unresolvable issues to field dispatch, cutting truck rolls where remote resolution suffices.
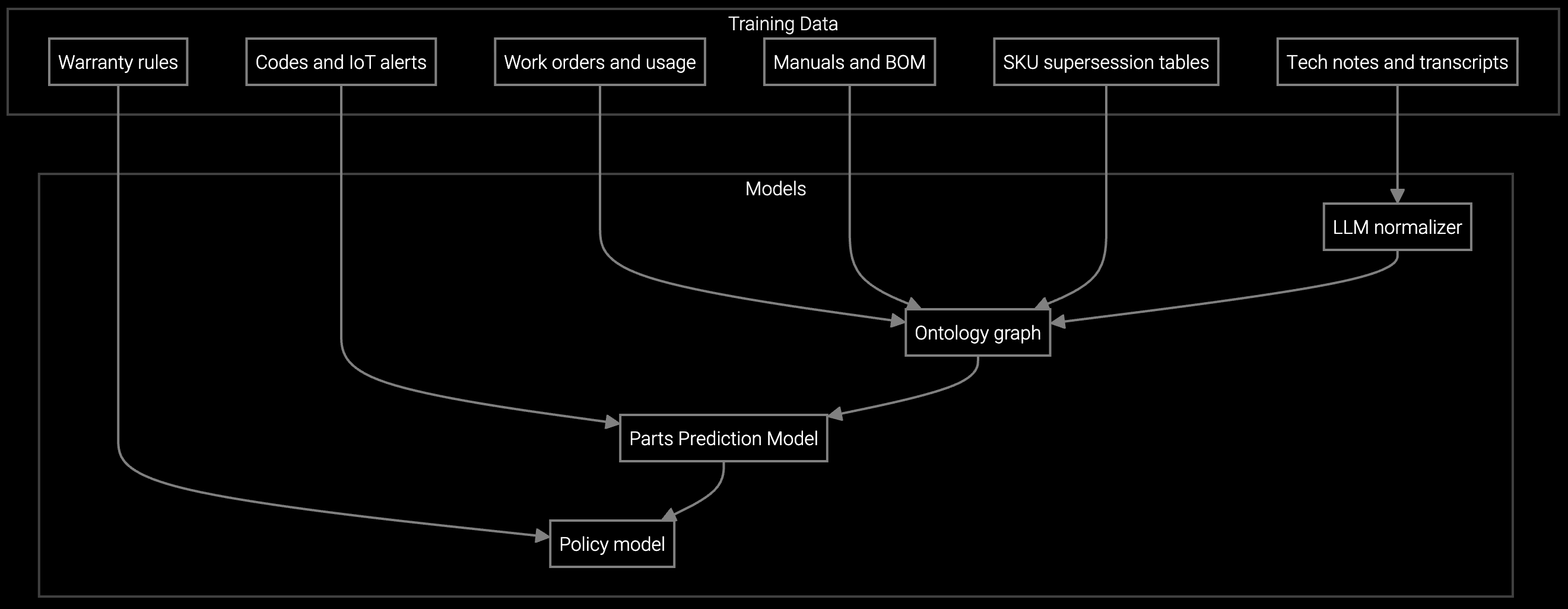
Pre-stage optics modules, power supplies, and line cards based on failure telemetry—technicians arrive with the exact SKU needed for DWDM or carrier-grade router repairs.
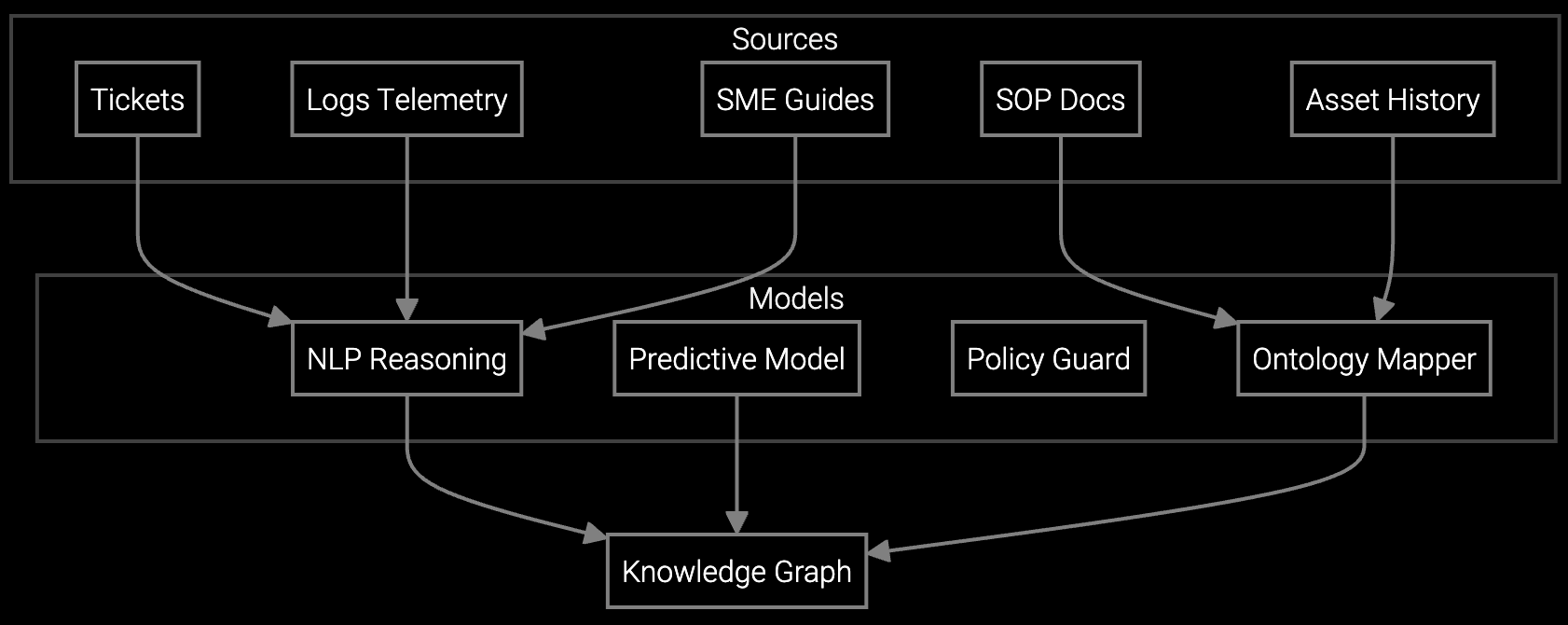
Correlate network error logs with historical firmware bugs and tribal knowledge from senior engineers to pinpoint whether switch crashes stem from PoE overload or ASIC thermal limits.
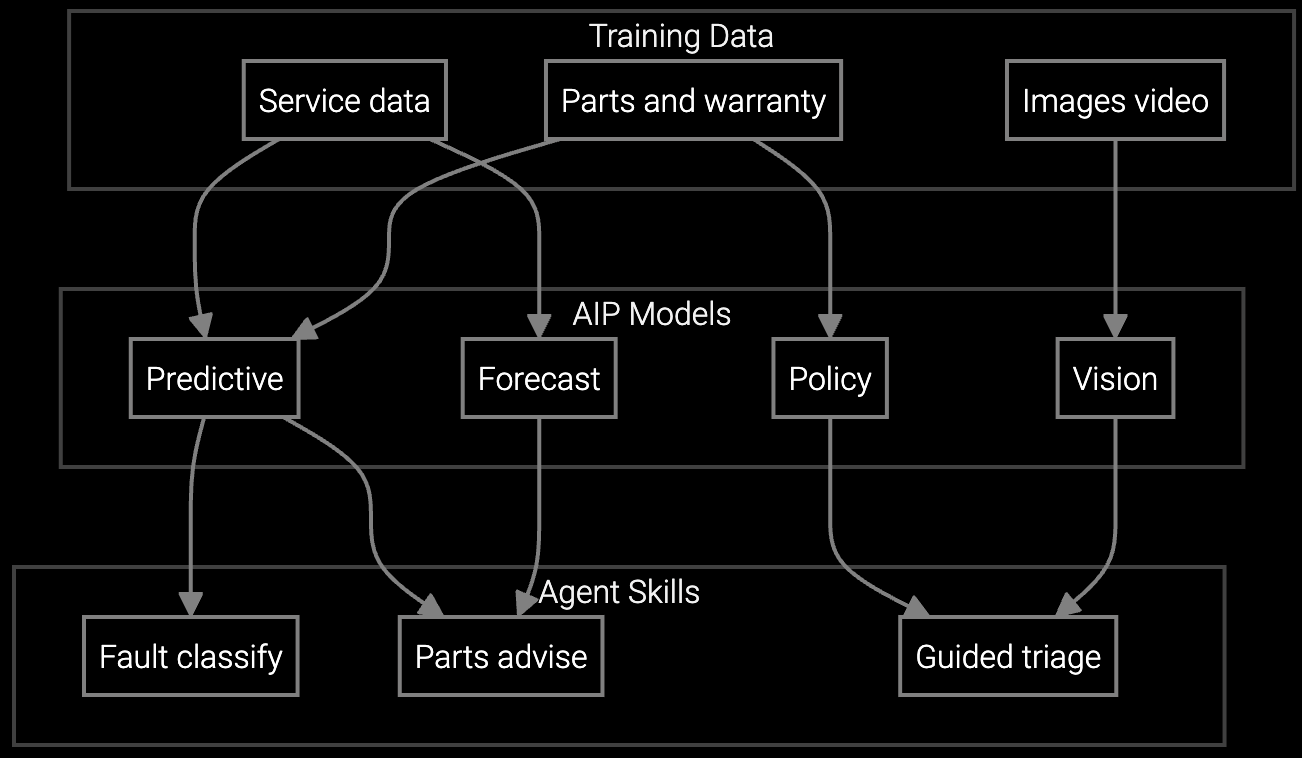
Mobile API delivers real-time repair procedures and diagnostic scripts for firewall misconfigurations or optical transport alarms—junior technicians execute expert-level troubleshooting on-site.
Network downtime breaches 99.999% SLAs in minutes, not hours. A core router failure at a carrier-grade installation costs the end customer $12K-18K per hour in lost connectivity. Your OEM contract absorbs SLA penalties if MTTR exceeds thresholds—typically 4 hours for critical infrastructure.
AI-driven root cause analysis cuts MTTR by identifying firmware version conflicts, SNMP trap patterns indicating hardware degradation, or configuration drift from NOC change windows. Predictive parts staging ensures technicians carry the correct optics module or power supply on first dispatch, avoiding the 6-8 hour delay of return trips in remote cell tower or data center locations.
Multiply avoided dispatches by blended truck roll cost (labor, travel, overhead). Network OEMs average $220-280 per standard dispatch, $400-550 for emergency. If AI reduces monthly dispatches from 850 to 530, savings = 320 × $250 = $80K monthly. First-time fix improvements compound this by eliminating repeat visits.
SNMP trap histories and syslog error patterns yield the strongest predictive signal for router and switch failures. Optical signal strength degradation in DWDM systems and thermal sensor trends in high-density switches provide early warning of hardware faults. Configuration change logs correlate with firmware-triggered crashes.
Yes. Python SDKs let your data engineers retrain failure classifiers when you launch new router platforms or firewall firmware versions. The headless API architecture means you own the model weights and training pipeline—no vendor dependency for updates. Most OEMs retrain quarterly as firmware evolves.
Network OEMs with 800+ monthly truck rolls typically see payback in 7-11 months. ROI accelerates if you're absorbing SLA penalties—avoiding two $15K penalty events per quarter self-funds the system. Implementation takes 8-12 weeks for API integration and initial model training on historical telemetry data.
Headcount typically stays flat while dispatch volume handled per technician rises 35-40%. OEMs redeploy saved capacity toward expanding service contracts or supporting new product lines rather than reducing workforce. Senior technicians shift from routine dispatches to complex multi-vendor integration issues AI cannot yet resolve.

How AI bridges the knowledge gap as experienced technicians retire.

Generative AI solutions for preserving institutional knowledge.

AI-powered parts prediction for higher FTFR.
Get a custom TCO breakdown based on your truck roll volume, equipment mix, and SLA structure.
Request ROI Model