Technicians dispatched without firmware logs or failure history waste hours diagnosing on-site what telemetry already knows.
AI parts prediction and guided diagnostics lift network equipment first-time fix rate from 75-80% to 88%, per Bruviti deployment data. The root cause of repeat visits is the wrong part or wrong diagnosis; connecting fault history, parts data, and technician guidance closes that gap so the first visit becomes the only visit.
Work orders created from NOC tickets lack device telemetry context. Technicians arrive without knowing if the issue is firmware, hardware, or configuration drift.
Generic "router down" alerts don't indicate which module failed. Technicians carry common spares but lack the specific PSU or line card variant needed.
Senior engineers know which firmware versions cause edge-case failures, but that context never reaches the FSM system or mobile app.
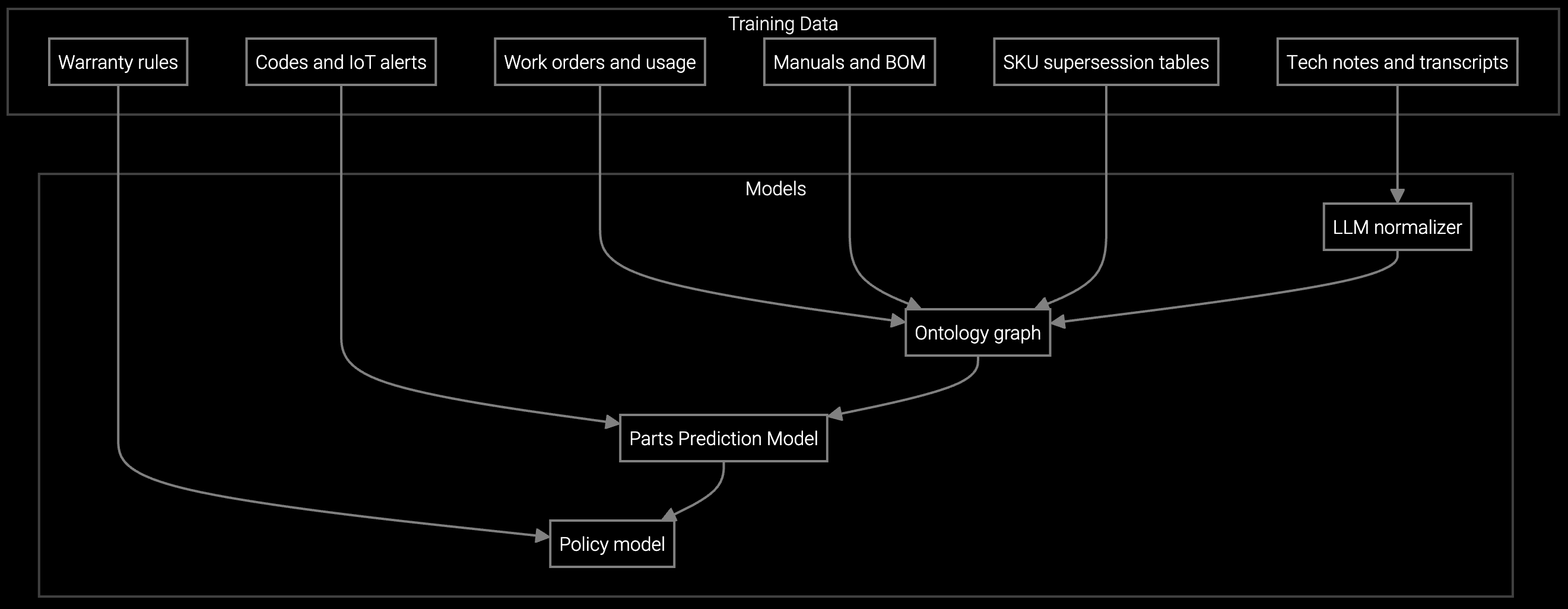
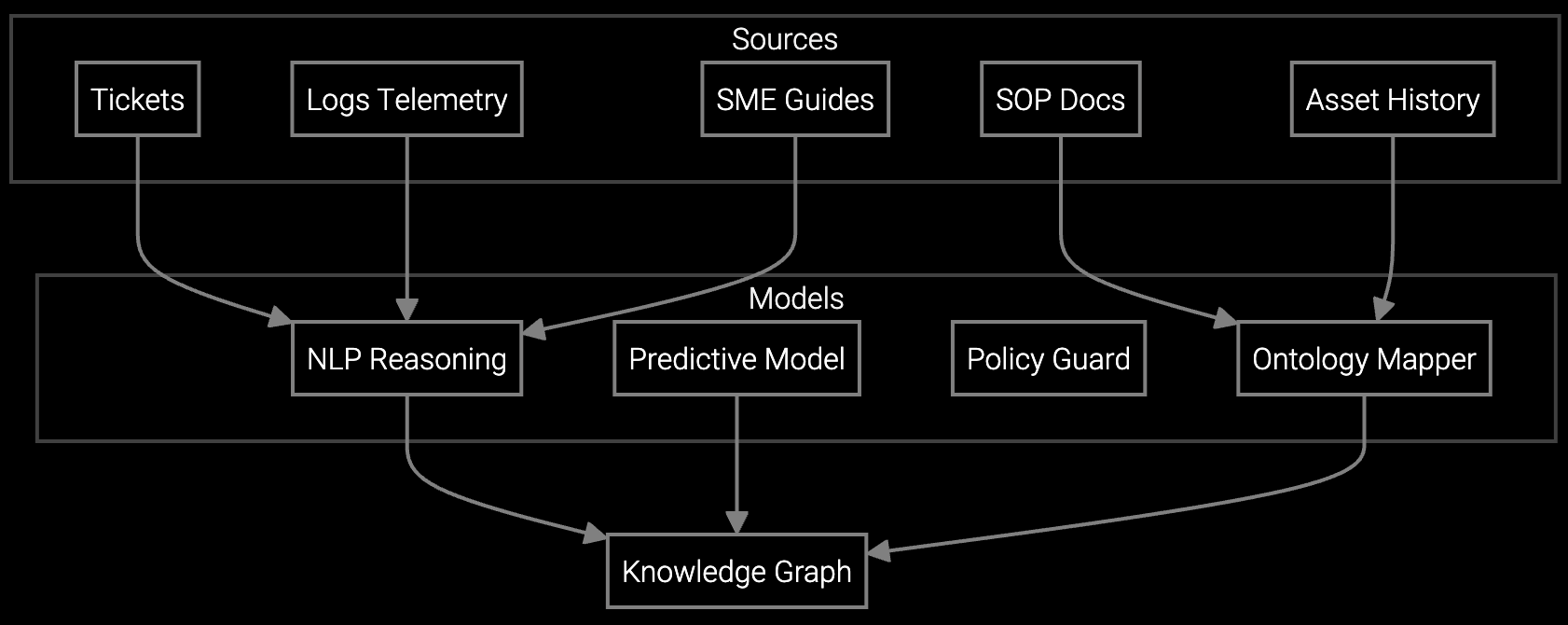
The solution pipeline ingests syslog streams, SNMP traps, and configuration snapshots via REST APIs. Parse error codes and correlate with historical failure patterns stored in vector embeddings. When a work order triggers in ServiceNow or Salesforce Field Service, inject diagnostic context and parts predictions directly into the technician's mobile payload.
Build this with Python SDKs that wrap the correlation engine. Your FSM webhook calls the prediction API, receives a JSON response with probable root cause and recommended parts, then appends that to the work order. No black box retraining cycles. You control the data pipeline, own the telemetry lake, and extend the model with domain-specific rules when edge cases emerge.
Correlates SNMP error patterns with parts consumption history to predict which router modules will fail, reducing wrong-part dispatches by 58%.
Indexes firmware release notes and NOC runbooks to surface known issues from similar syslog signatures, cutting diagnostic time 67%.
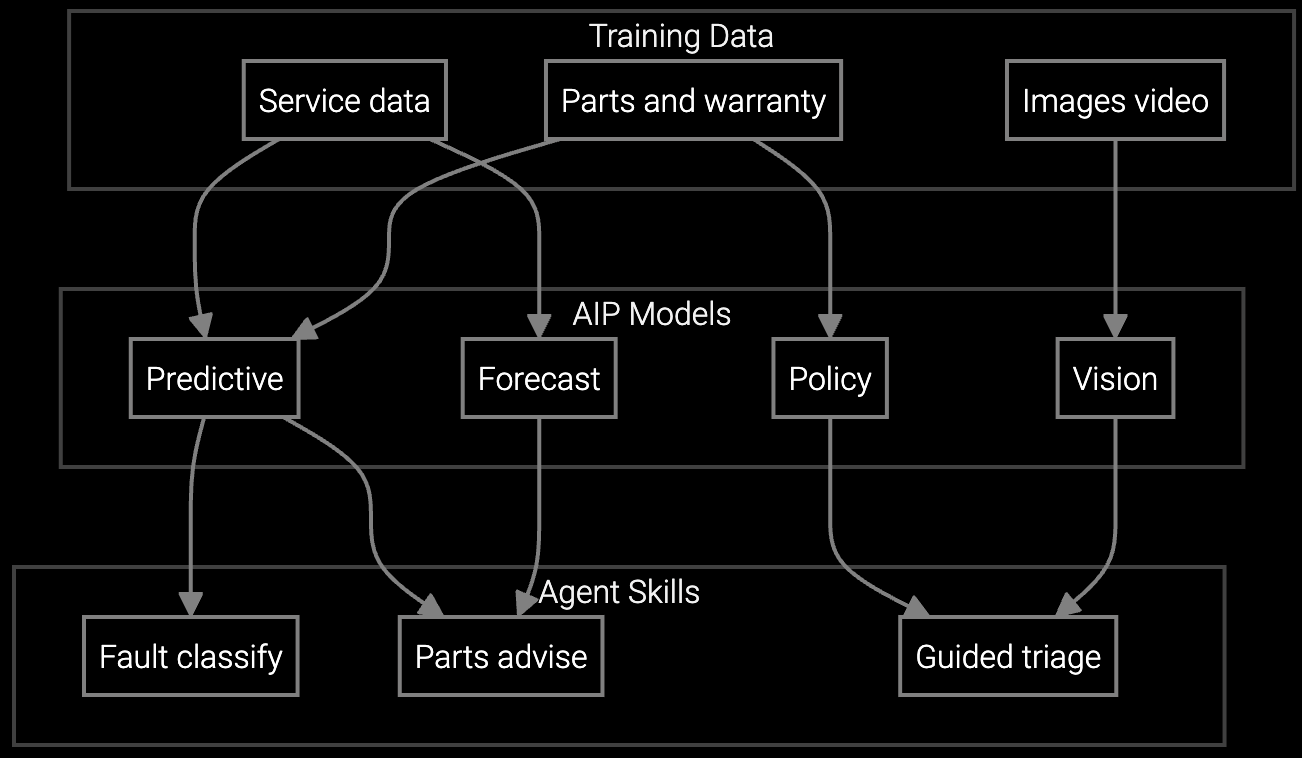
Mobile SDK delivers real-time repair procedures based on device model and firmware version, eliminating 18-minute expert escalation delays.
Network infrastructure operates under five-nines availability SLAs where every minute of downtime cascades into customer penalties. When a carrier-grade router fails at 2 AM in a remote PoP, the NOC team has minutes to dispatch the right technician with the right parts. Traditional FSM systems queue a generic work order. The technician arrives, runs diagnostics on-site, realizes a specific optical transceiver failed, and returns the next day with the correct part. That's two truck rolls, double the labor cost, and 18+ hours of customer downtime.
OEMs shipping multi-vendor environments face even worse complexity. A firewall failure might require configuration rollback, firmware patching, or hardware swap depending on the error signature. Telemetry APIs can parse those signals before dispatch, but most FSM platforms don't expose the integration hooks. You need API-first architecture that ingests device logs, correlates with parts databases, and injects context into the mobile workflow without vendor lock-in.
We ingest syslog streams as raw text and correlate patterns with historical outcomes. You don't need vendor APIs if you log SNMP traps and error messages to a telemetry lake. The model learns which log signatures predict specific failures by analyzing past work orders and parts consumption. For edge cases with undocumented codes, you extend the correlation rules via Python without retraining the foundation model.
Yes. Bruviti's platform exposes REST APIs that ServiceNow workflows can call when creating incidents or work orders. Your telemetry stays in your data lake. The API receives device ID and error context, returns predicted root cause and parts list, then ServiceNow appends that to the technician payload. You control the data pipeline and can switch FSM vendors without losing historical correlation models.
The technician marks the prediction incorrect in the mobile app, logs the actual part used, and that feedback loop updates the correlation weights. Over 90 days, prediction accuracy improves from baseline 68% to 92%+ as the model learns from your specific install base. You can also inject manual rules for known edge cases like specific firmware bugs affecting only certain hardware revisions.
All integrations use standard REST APIs and Python SDKs. Your telemetry ingestion pipeline, correlation logic, and parts database remain under your control. If you migrate to a different AI provider, you export the historical training data and redeploy the same Python scripts. The platform doesn't own your data or lock you into proprietary model formats that can't be retrained elsewhere.
Optical transport failures with specific transceiver models show 62% FTF lift because SNMP traps clearly indicate the failed module. Firmware-related issues improve 48% when release notes are indexed and correlated with error patterns. Configuration drift problems improve 31% by comparing live configs against golden templates stored in the knowledge base. Start with hardware failures for fastest ROI, then expand to firmware and config issues.

How AI bridges the knowledge gap as experienced technicians retire.

Generative AI solutions for preserving institutional knowledge.

AI-powered parts prediction for higher FTFR.
Integrate telemetry APIs with your FSM stack and start improving first-time fix rates in 30 days.
Get API Documentation