Senior technicians retire faster than juniors gain expertise, leaving data center OEMs with costly repeat visits and SLA exposure.
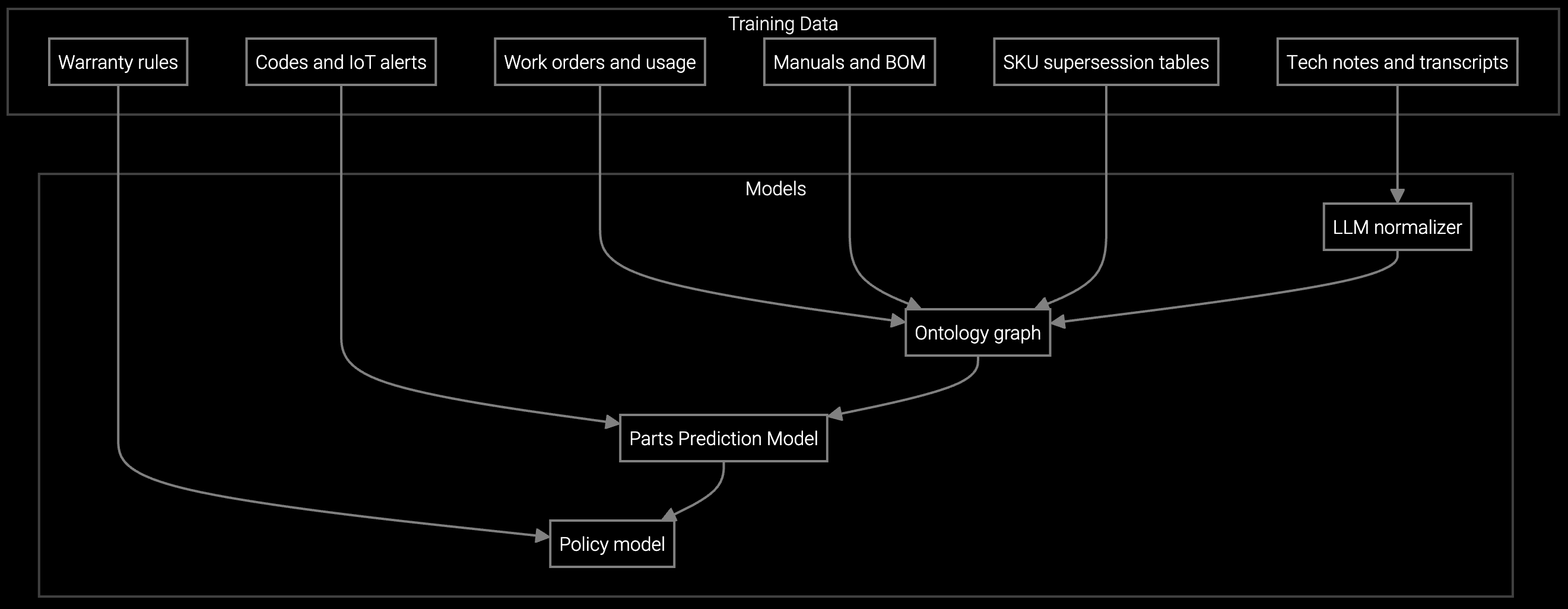
Bruviti deployment data shows AI-assisted diagnostics raise first-time fix rate from 75-80% to 88% on data center hardware. Builders solve repeat visits by connecting fault history, telemetry, and parts prediction into one guidance engine, so the technician carries the right fix and the right part on visit one.
Senior technicians who know BMC error codes by memory are retiring. Junior techs arrive on-site with procedure manuals, not pattern recognition. The gap shows up as repeat visits for issues veterans would diagnose in minutes.
Technicians arrive at hyperscale sites with generic part kits because dispatch systems lack failure pattern data. A faulty power supply cascades into drive failures, but the truck only carried PSU spares. Second trip required.
Proprietary diagnostic platforms promise intelligence but trap field service data in closed ecosystems. Engineers can't retrain models on new hardware generations or export knowledge graphs to integrate with custom FSM workflows.
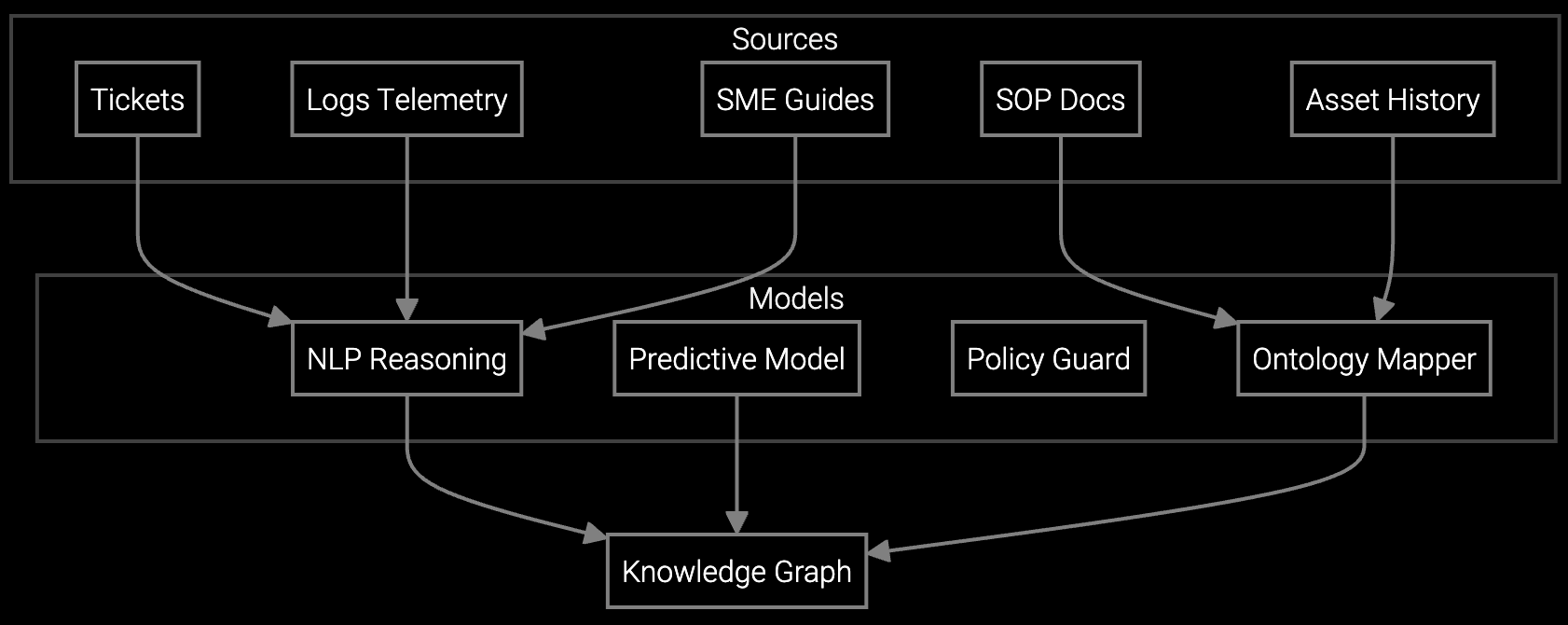
Bruviti's platform converts unstructured technician knowledge—work order notes, repair photos, IPMI logs—into graph-structured data accessible via Python SDKs and REST endpoints. Knowledge capture happens automatically during job completion, with senior tech insights tagged as high-confidence nodes. Junior technicians query this graph through mobile APIs that run locally on ruggedized tablets, delivering diagnostic guidance even when hyperscale sites block cellular connectivity.
The architecture separates model training (cloud-based batch jobs on your infrastructure) from inference (edge deployment on technician devices). You control where training data lives, which models deploy to which device cohorts, and when to retrain on new hardware failures. Integration with SAP Field Service Management, Oracle Service Cloud, or custom dispatch systems happens through standard REST calls—no vendor-specific adapters required.
API predicts which server components will fail based on BMC telemetry and historical patterns, pre-staging parts before dispatch to improve first-time fix rates at hyperscale sites.
Graph-based correlation engine connects IPMI error sequences with past failure modes captured from senior technicians, surfacing root cause hypotheses junior techs can test on-site.
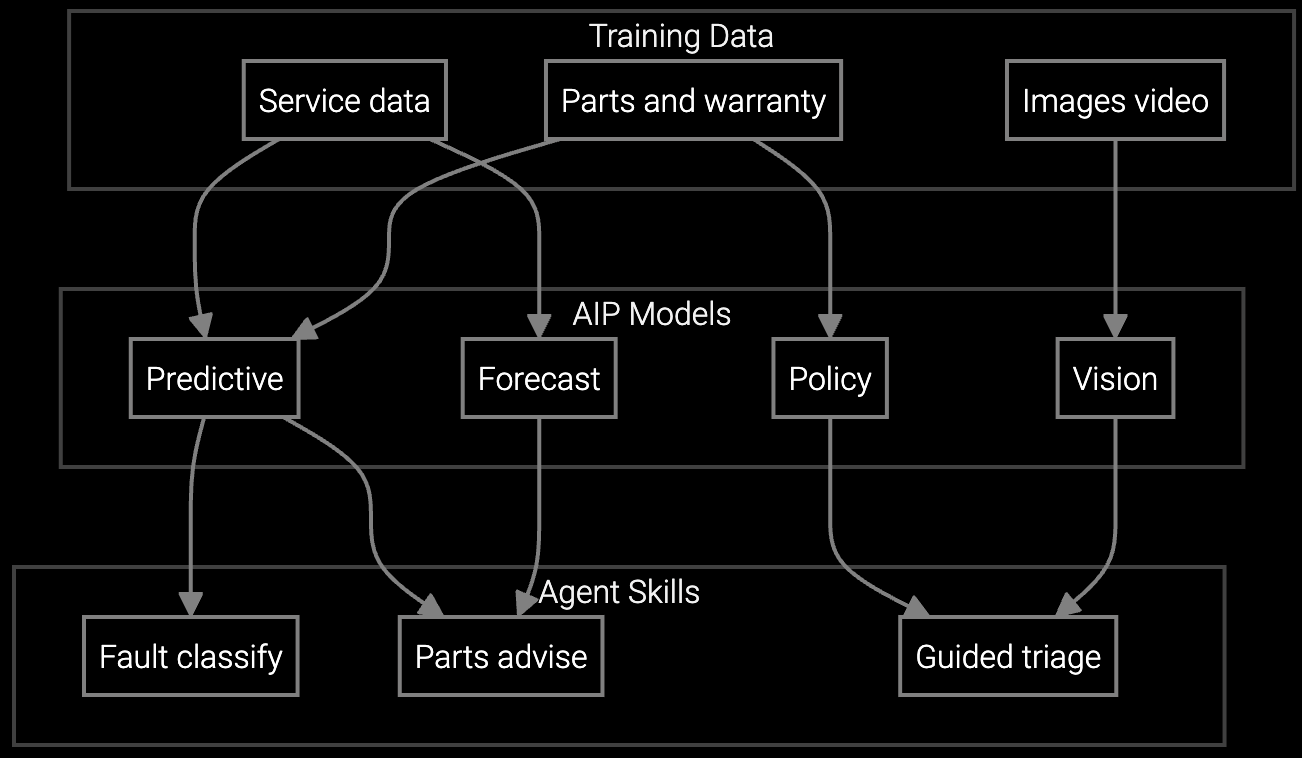
Mobile SDK delivers real-time diagnostic recommendations via edge-deployed models, providing repair procedures and troubleshooting steps even when data center facilities block network access.
Data center OEMs face unique field service constraints. Hyperscale operators demand four-nines availability, meaning unplanned downtime triggers penalty clauses. Technicians service racks with mixed hardware generations—legacy Xeon systems next to current EPYC nodes—requiring expertise across CPU architectures, RAID controller firmware versions, and cooling subsystem variations.
IPMI logs and BMC telemetry generate massive diagnostic datasets, but knowledge capture is manual. When a senior tech identifies that specific thermal patterns precede DIMM failures in certain motherboard revisions, that insight lives in their head. Junior techs arrive with procedure manuals that don't encode these correlations, leading to shotgun part replacements instead of targeted repairs.
Yes. Bruviti's platform runs model training as containerized jobs on your infrastructure. Training data never leaves your VPC. You export knowledge graphs via GraphQL queries to fine-tune models on new hardware generations using your own PyTorch pipelines.
Models sync during device charging cycles when tablets reconnect to corporate WiFi. Critical updates push via scheduled sync windows. Inference runs entirely on-device using quantized models optimized for ARM processors in ruggedized tablets.
Typical integration takes 2-3 weeks. REST APIs expose diagnostic recommendations that SAP FSM consumes as custom fields in work orders. Python SDK provides sample code for bi-directional sync of job status, parts consumption, and technician feedback.
Natural language processing extracts diagnostic patterns from terse notes like "replaced PSU, checked adjacent drives." Computer vision analyzes repair photos to identify components. IPMI log correlation fills gaps where notes are sparse, building knowledge graphs automatically.
Full export available via GraphQL API in RDF or JSON-LD formats compatible with standard knowledge graph tools. No proprietary schemas lock your data. You own the graph structure and can migrate to any system that supports semantic web standards.

How AI bridges the knowledge gap as experienced technicians retire.

Generative AI solutions for preserving institutional knowledge.

AI-powered parts prediction for higher FTFR.
Explore Bruviti's Python SDKs and see how knowledge graphs integrate with your FSM stack.
Talk to an Engineer