Hyperscale uptime demands leave no room for second truck rolls when RAID controllers and power supplies fail.
Bruviti deployment data shows AI raises first-time fix rate by 10 to 15 percentage points and reduces repeat truck rolls by 30% on data center server hardware. Operators end the cycle of return visits by arming technicians with AI-predicted picklists and guided diagnostics before dispatch.
Technicians arrive without the correct PSU, memory module, or drive model because dispatch relies on customer-reported symptoms instead of BMC telemetry. The tech diagnoses on-site, orders parts, and schedules a return visit.
Work orders show "server down" but not which blade, RAID status, or thermal history. Technicians spend 20-40 minutes on-site just gathering context that already exists in IPMI logs and warranty databases.
A failed drive cascades to RAID controller stress and thermal spikes. Techs fix the obvious symptom but miss root cause. The server fails again 72 hours later with a different component, triggering another truck roll.
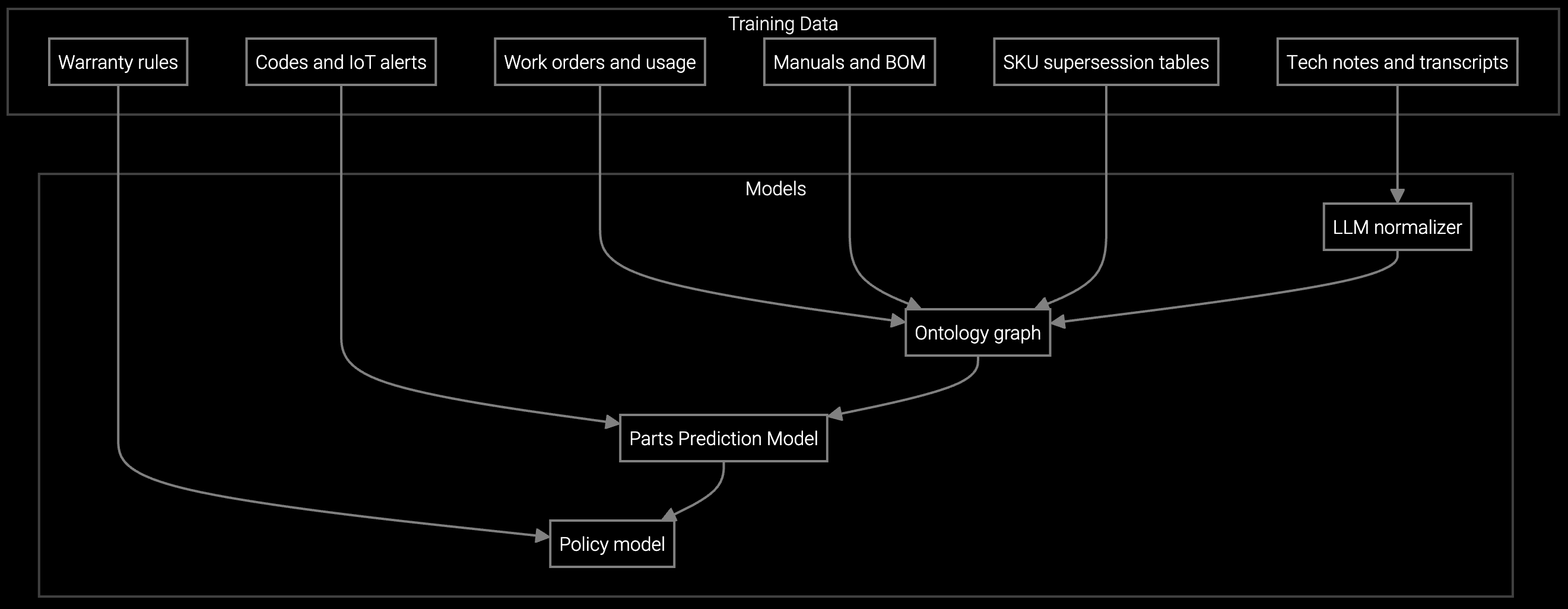
The platform analyzes BMC telemetry, IPMI event logs, and historical failure patterns before dispatch. It identifies probable root cause, predicts which parts will fail next, and pre-loads the work order with complete diagnostics context. Technicians arrive with the right parts and a guided repair plan.
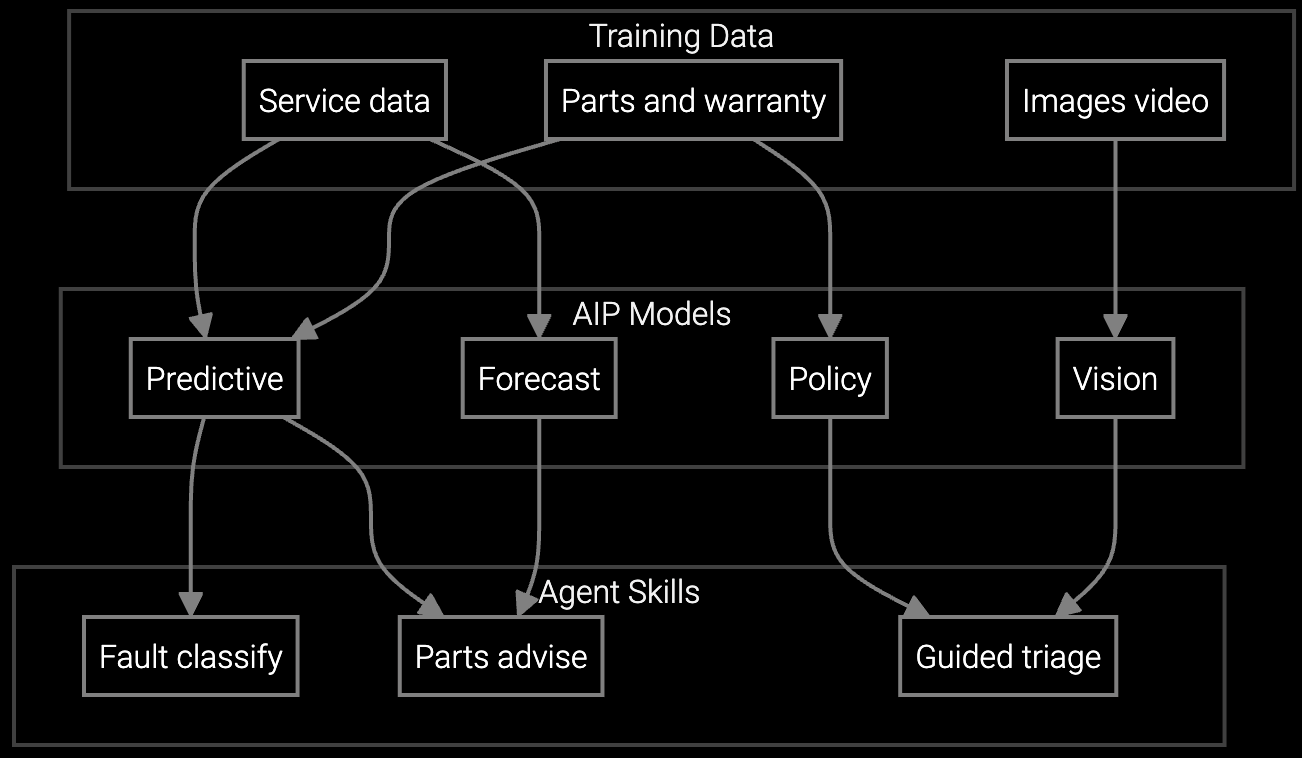
Instead of on-site diagnosis, technicians validate predictions and execute repairs. The mobile interface shows RAID rebuild status, thermal trends, and memory error counts in real time. Complex multi-component failures get flagged with escalation triggers, preventing partial fixes that lead to callbacks.
Predicts which server components will fail based on BMC telemetry, ensuring technicians carry the correct PSU, DIMM, or drive model before dispatch.
Correlates IPMI event codes with historical failure patterns across thousands of servers to identify cascading failures before they escalate.
Mobile copilot provides real-time RAID rebuild status, thermal anomaly alerts, and step-by-step repair procedures at the rack.
Hyperscale customers operate 50,000+ servers per facility. A 4% annual hardware failure rate means 2,000 service events per year per site. Coordinating parts inventory, dispatch windows, and SLA compliance at this scale overwhelms manual triage.
Server configurations vary by generation, SKU, and customer firmware versions. A RAID controller for a Gen 9 chassis won't work in Gen 10. Technicians need precise part numbers derived from BMC inventory data and warranty entitlements before dispatch, not guesses based on customer phone calls.
Missing parts at the site is the leading cause. Technicians diagnose on arrival and discover they need a different PSU model, memory module, or drive than initially assumed. Without BMC telemetry analysis before dispatch, parts prediction relies on incomplete customer descriptions.
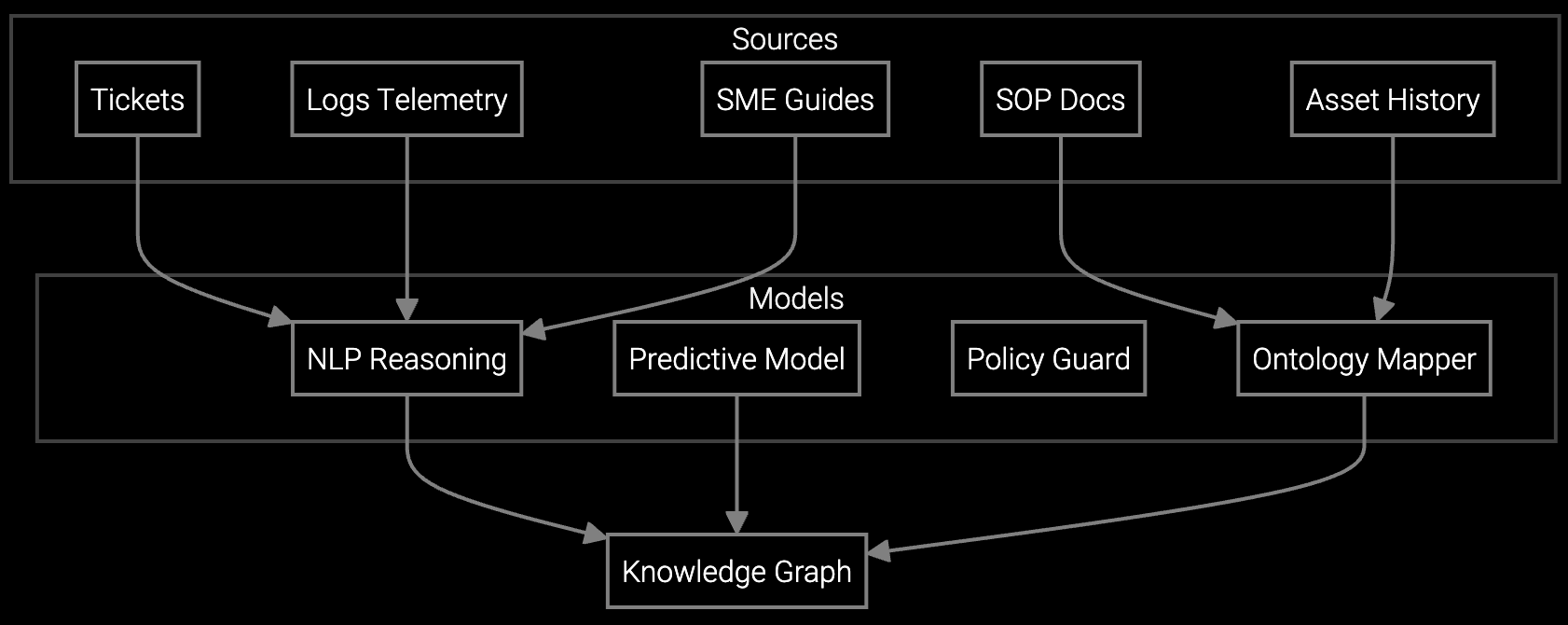
The platform correlates BMC event logs, IPMI sensor data, and historical failure patterns across similar server configurations. It identifies the probable failing component, checks warranty entitlement for exact part numbers, and flags secondary risks like thermal stress or RAID degradation that could trigger follow-on failures.
Yes. The mobile interface shows the AI's reasoning with supporting telemetry evidence. Technicians can accept, modify, or reject recommendations. Override data feeds back into the training loop to improve future accuracy for edge cases the model hasn't seen.
The platform flags cascading failure patterns like thermal spikes causing memory errors or RAID controller stress from drive failures. It recommends replacing both the symptom component and the root cause driver. Technicians get escalation triggers if on-site findings suggest a deeper issue requiring engineering review.
Track first-time fix rate, callback rate within 7 days, and average on-site diagnostic time. Compare truck roll costs before and after AI-assisted dispatch. Typical improvements include FTF rising from 68% to 89% and callbacks dropping from 18% to 4%, saving $420 per avoided return trip.

How AI bridges the knowledge gap as experienced technicians retire.

Generative AI solutions for preserving institutional knowledge.

AI-powered parts prediction for higher FTFR.
See how Bruviti arms your technicians with the right parts and diagnostics context before dispatch.
Schedule Demo