Hyperscale operators demand 99.99% uptime while service costs erode margins—choosing the wrong AI approach risks competitive position.
Bruviti deployment data shows AI field service cuts mean time to repair from 7 days to 2 days on data center equipment. Executives choosing build vs buy should anchor the decision on that proven outcome, since a connected diagnostics, parts, and dispatch layer is hard to replicate in-house.
With server densities reaching 10-20 kW per rack and hyperscale SLAs demanding sub-4-hour response times, every truck roll to hyperscale data centers carries premium costs while low first-time fix rates force repeat visits that erode margins.
Senior technicians who understand BMC telemetry patterns, thermal anomaly diagnosis, and complex RAID configurations are retiring while hyperscale customers deploy increasingly diverse hardware stacks requiring specialized knowledge.
In-house AI development for predictive maintenance, parts forecasting, and technician guidance requires 18-36 months while competitors deploying faster solutions capture market share in the rapidly consolidating data center equipment sector.
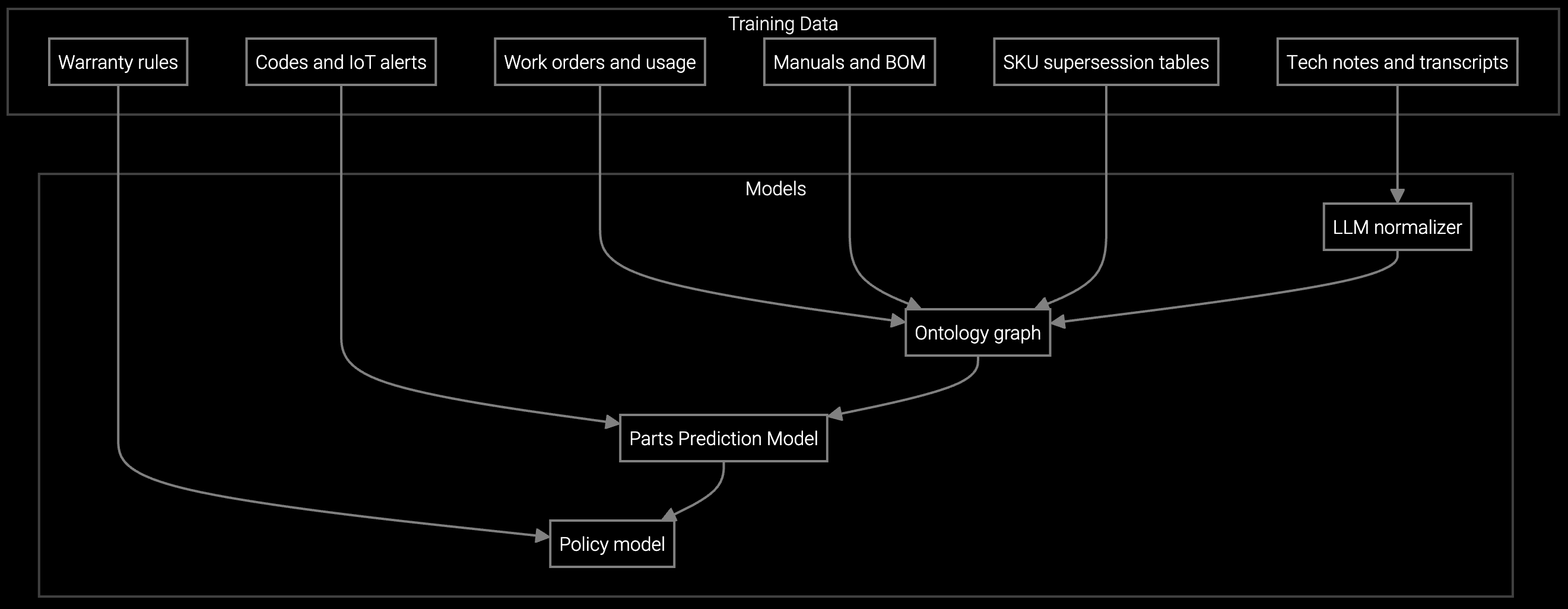
The optimal strategy for data center OEMs combines platform speed-to-value with strategic control. Bruviti's API-first architecture enables rapid deployment of pre-trained models for predictive parts failure, technician dispatch optimization, and knowledge capture—while preserving flexibility to customize diagnostics for proprietary BMC telemetry, thermal signatures, and hardware-specific failure patterns.
This hybrid approach delivers measurable ROI within 6-9 months through reduced truck rolls and improved first-time fix rates, while technical teams extend the platform's capabilities for competitive differentiation. The platform ingests IPMI data, firmware logs, and environmental sensors to predict component failures before they trigger customer SLA penalties, directly protecting service margins while building institutional knowledge as technician expertise transitions.
Predict which server components, power supplies, or cooling system parts technicians will need before dispatch to hyperscale data centers, ensuring first-visit resolution for time-critical hardware failures.
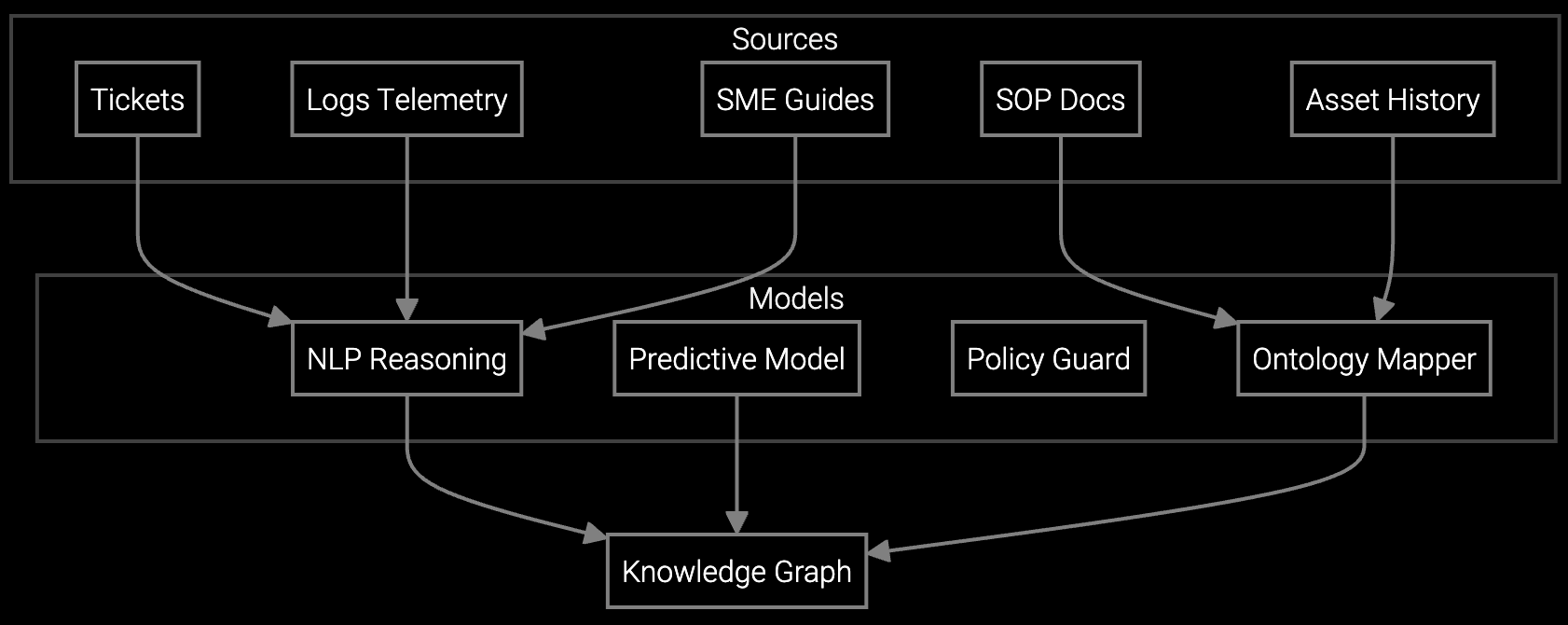
Correlate BMC telemetry, thermal sensor data, and firmware logs with historical failure patterns to identify root causes faster, reducing diagnostic time for complex server rack issues.
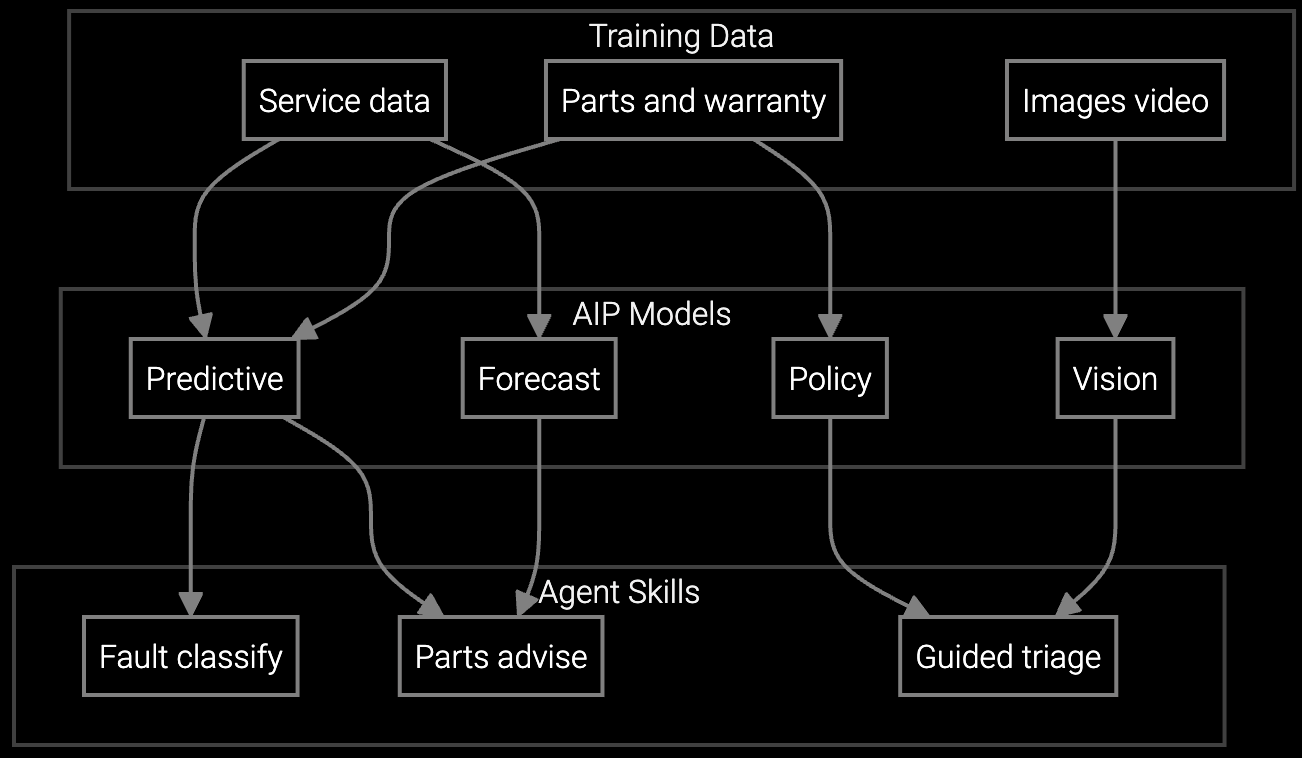
Mobile copilot delivers real-time guidance on RAID rebuild procedures, thermal containment checks, and IPMI diagnostics on-site, extending institutional knowledge to newer technicians at hyperscale facilities.
Data center equipment manufacturers serve customers where every minute of server downtime costs $5,000-$9,000 per rack, making field service effectiveness a competitive differentiator. Deploy AI capabilities incrementally: start with high-volume component failures (drives, memory, PSUs) where predictive models deliver immediate truck roll reduction, then expand to thermal management diagnostics and complex multi-component failures as the platform learns hardware-specific patterns.
The platform ingests BMC telemetry, IPMI logs, environmental sensor data, and technician repair histories to build predictive models specific to your server generations, storage architectures, and cooling system designs. This approach protects service margins while building the institutional knowledge foundation to support next-generation high-density compute deployments for AI workloads where failure prediction becomes even more critical.
In-house builds require dedicated ML engineering talent, proprietary training data pipelines, and 24-36 months before production deployment while competitors capture market share. Platform approaches deliver ROI in 6-9 months but require evaluating vendor lock-in, data ownership terms, and extensibility for proprietary hardware diagnostics. The hybrid approach mitigates both risks by enabling fast deployment of proven capabilities while preserving technical control over competitive differentiators.
Calculate total annual truck roll costs (average $850+ per visit for data center equipment), multiply by achievable reduction percentage (industry benchmarks show 18-25% reduction), then add margin protection from improved first-time fix rates reducing SLA penalties. For mid-tier OEMs with 3,500-4,000 annual truck rolls, this typically yields $1.8M-$3.2M annual savings against platform costs of $400K-$600K, delivering sub-12-month payback while building strategic capabilities for market differentiation.
Modern platforms provide REST APIs and webhook integrations for bidirectional communication with field service management systems, enabling automated work order enrichment and dispatch optimization. For proprietary telemetry like custom BMC implementations or specialized thermal sensors, API-first platforms allow technical teams to build parsers and feature extractors while leveraging pre-trained predictive models for common failure modes, balancing integration speed with hardware-specific customization needs.
Initial improvements appear within 60-90 days as the platform analyzes historical failure patterns and begins predicting parts needs for common server component failures. Substantial FTF rate gains (10-15 percentage point improvement) typically materialize at 6-9 months once the system ingests sufficient BMC telemetry, work order histories, and technician feedback to refine predictions for hardware-specific failure modes and complex multi-component issues.
Without intervention, expertise walks out the door—diagnostic intuition for thermal anomalies, known RAID controller quirks, and undocumented fix procedures disappear. AI platforms with knowledge capture capabilities preserve this expertise by recording technician decisions, correlating fixes with telemetry patterns, and codifying diagnostic workflows into guided procedures accessible to newer technicians via mobile devices on-site. This transforms tacit knowledge into institutional assets that protect service quality during workforce transitions.

How AI bridges the knowledge gap as experienced technicians retire.

Generative AI solutions for preserving institutional knowledge.

AI-powered parts prediction for higher FTFR.
Discuss build-vs-buy tradeoffs and hybrid platform approaches with Bruviti's team.
Schedule Strategy Session