Hyperscale customers demand 99.99% uptime. Manual dispatch and missing parts cost millions in SLA penalties.
Bruviti deployment data shows automated workflows deliver 20 to 30% faster resolution with 60% of faults guided through auto-triage for data center equipment. Executives connect diagnostics, parts, and dispatch into one flow so service moves faster without adding technician headcount.
Manual triage routes thermal alerts to storage specialists and RAID failures to power techs. Wrong-skill dispatch doubles resolution time and burns hyperscale customer trust.
Technicians arrive without the failed power supply or drive. Each return trip to the depot adds 90 minutes to MTTR and risks SLA breach on four-nines availability contracts.
First-visit failures stem from incomplete diagnostics. Technician treats symptom not root cause, closes ticket, then returns days later when the real issue surfaces.
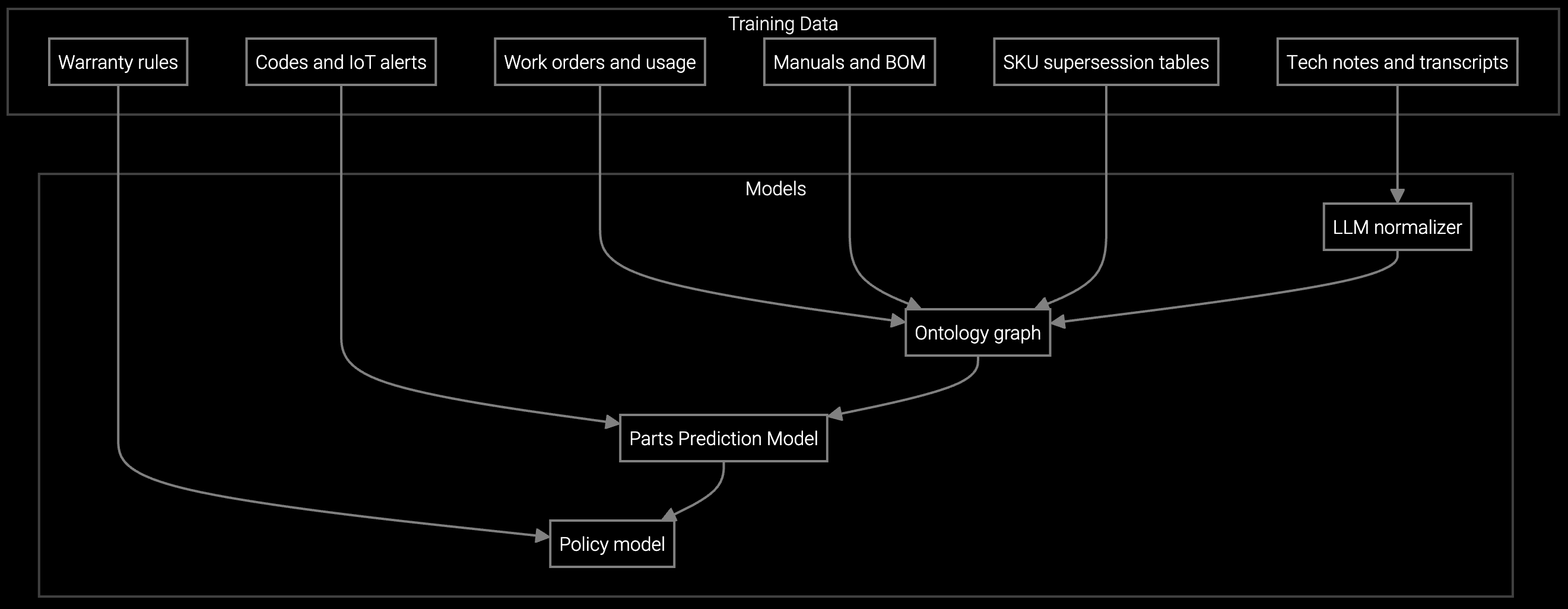
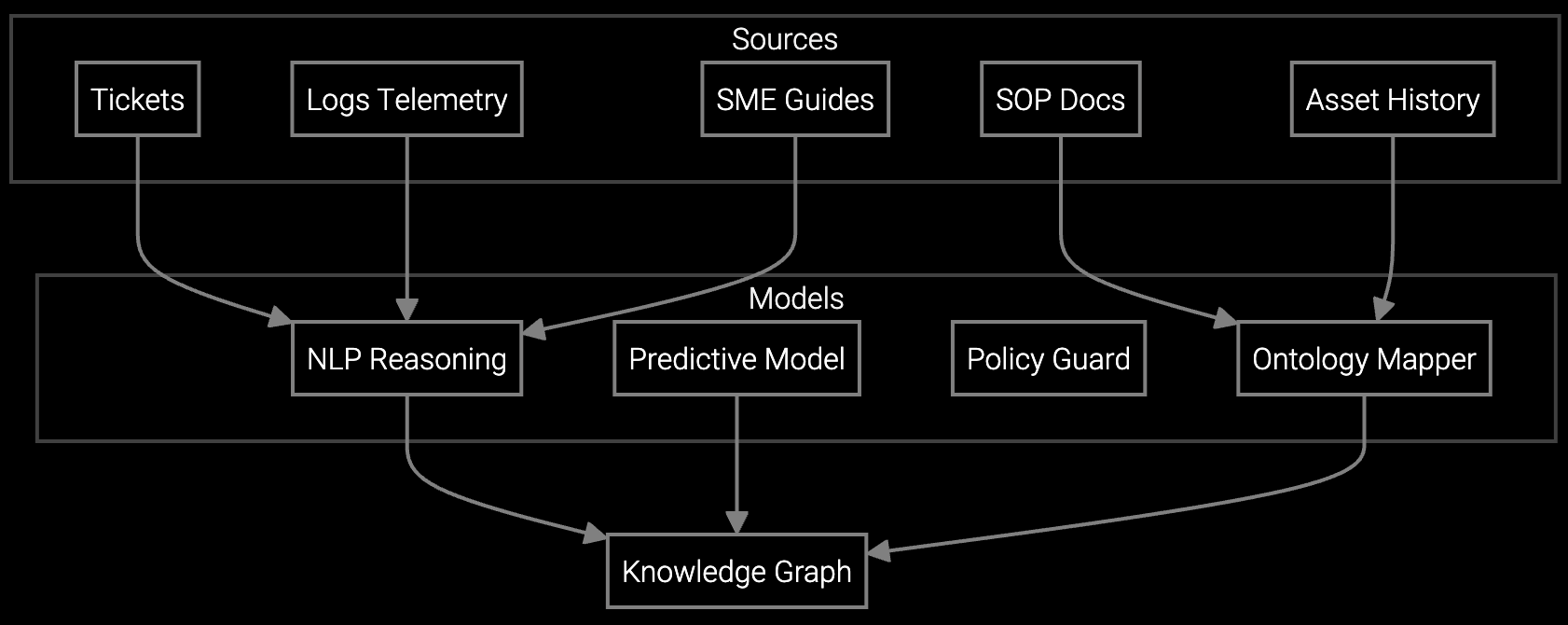
Bruviti orchestrates the complete field service lifecycle from failure detection to job closure. The platform ingests BMC telemetry and IPMI alerts, correlates them with historical failure patterns, and auto-generates work orders with root cause analysis already attached. Dispatch logic routes each job to the technician with the right skill profile and geographic proximity, while parts prediction pre-stages inventory before the truck rolls.
This eliminates manual triage queues and guesswork. The platform makes the skill-matching decision, triggers the parts order, and delivers a complete diagnostic brief to the mobile device. Technicians arrive knowing what failed, why it failed, and which parts to bring. Job completion triggers automated documentation, parts consumption reconciliation, and knowledge capture for future predictions.
Predicts which server components and cooling parts will fail next, ensuring technicians carry the right inventory to data center sites on first dispatch.
Correlates BMC alerts with historical failure patterns across hyperscale deployments, distinguishing thermal anomalies from power supply degradation automatically.
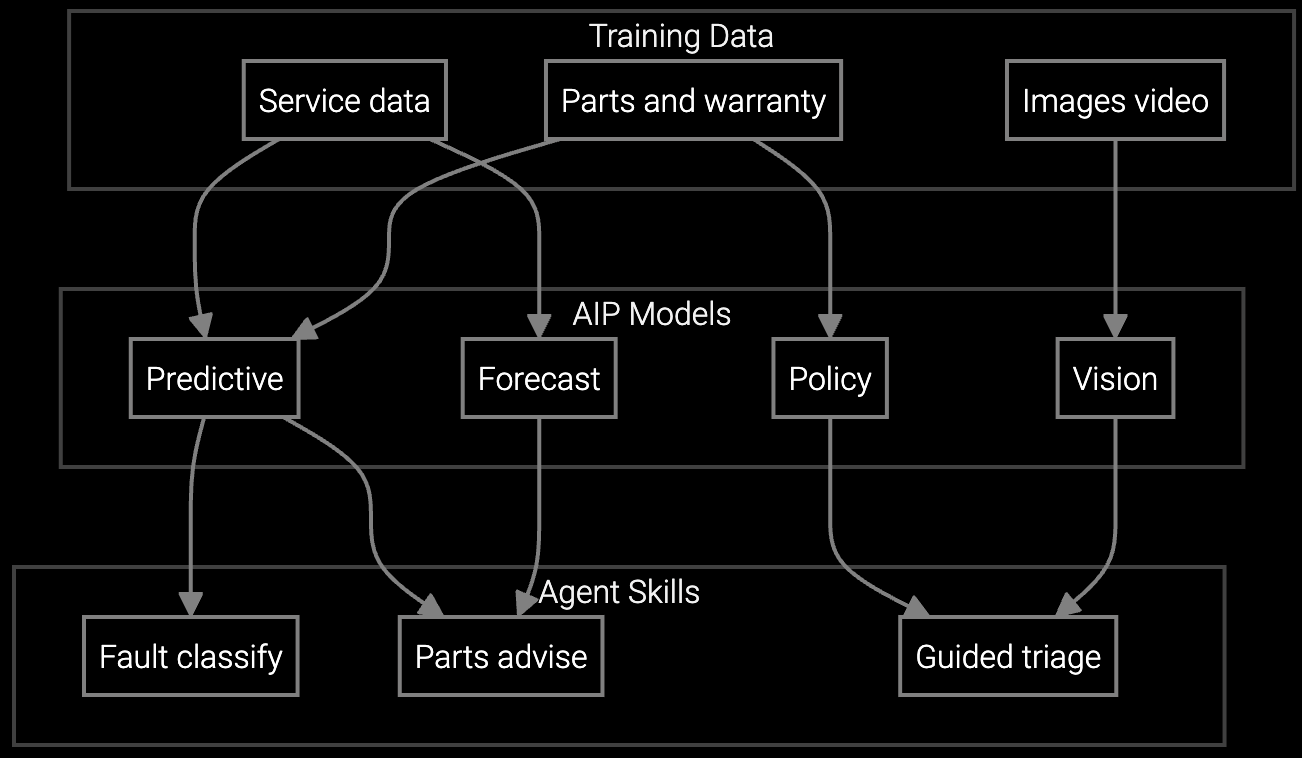
Delivers real-time RAID rebuild procedures and hot-swap guidance to mobile devices, eliminating delays from manual lookup during critical uptime windows.
Data center OEMs serve hyperscale operators managing hundreds of thousands of servers across distributed facilities. A single compute node failure cascades into workload migration costs and availability credits. Field service workflows must distinguish between drive degradation requiring hot-swap versus thermal issues needing HVAC adjustment—each demands different technician expertise and parts inventory.
The platform parses BMC sensor streams and correlates PUE anomalies with hardware telemetry. It routes cooling-related failures to HVAC specialists with thermal imaging tools, while storage controller errors trigger dispatch of compute techs carrying pre-staged RAID cards. This precision matching eliminates the margin erosion from wrong-skill truck rolls and parts expediting fees.
Automated triage analyzes BMC telemetry to distinguish between failures requiring on-site repair versus issues resolvable through remote firmware updates or configuration changes. Parts prediction ensures technicians carry the correct components on first dispatch, eliminating return trips. Skill-based routing matches job requirements to technician expertise, preventing misdirected visits that waste labor hours and delay resolution.
Start with compute node failures—BMC data quality is high and failure patterns are well-established. Automate work order generation from IPMI alerts, parts prediction for drive and power supply failures, and skill-based dispatch routing. These workflows deliver measurable impact on first-time fix rate within 60 days and require minimal custom integration beyond existing FSM systems.
The platform builds configuration-specific models by ingesting install base data and telemetry streams per server generation and vendor. It learns failure signatures unique to each hardware revision—distinguishing Gen 4 NVMe controller behavior from Gen 5, for example—and routes work orders accordingly. This prevents technicians from arriving with incompatible parts or outdated repair procedures.
Track first-time fix rate, truck roll cost per incident, technician utilization percentage, and MTTR before and after automation. Most data center OEMs see 30-40% improvement in first-time fix within 90 days, translating directly to reduced labor costs and SLA penalty avoidance. Measure parts carrying cost reduction as pre-staging accuracy improves and expedite shipping drops.
Bruviti connects via standard APIs to ServiceMax, Salesforce Field Service, and custom FSM platforms. It receives work order data and telemetry feeds, performs triage and parts prediction, then returns enriched work orders with skill requirements and parts lists. The FSM system handles scheduling and technician assignment using Bruviti's recommendations, preserving existing workflows while eliminating manual analysis steps.

How AI bridges the knowledge gap as experienced technicians retire.

Generative AI solutions for preserving institutional knowledge.

AI-powered parts prediction for higher FTFR.
See how Bruviti eliminates manual dispatch and reduces truck roll costs for data center OEMs.
Schedule Demo