
How we put your service data to work

The first phase of building an expert system capable of assisting your service and support teams is assembling and interpreting valuable data from across the organization. To automate this process, Bruviti applies machine-learning tech to onboard data from a wide variety of sources.
By Andy Chinmulgund
Data is at the heart of any intelligent system. In earlier blogs, we’ve looked at the challenges posed by data silos, discussed how data orchestration is a critical step on the path toward powering machine-learning applications, and how we apply AI in the pursuit of achieving specific business objectives. More recently, and with the COVID-19 pandemic affecting all service operations, we’ve looked at how AI-powered applications can help you reduce truck rolls and onsite visits.
In this month’s blog, we’ll take a look at how a wide variety of service- and product-related information from diverse sources is marshalled into order so that we can build the base models that are the foundation of our industry-specific solutions for service business units, warranty providers, and contact-center operations.
What data are we talking about?
Think for a moment about the data that your organization has created over the years: user manuals, service manuals, troubleshooting guides, installation and operations guides, FAQ databases, service bulletins, customer call transcripts, field service records, images, diagrams, and how-to videos. Some of this data is structured and located in a system of sort (which makes it fairly easy to access and combine with other data), while other forms of data are scattered around the organization or posted on the web.
In order to build a system capable of assisting your service and support teams, any and all of this data may be needed to train a machine-learning algorithm. An important first step, therefore, is to make this data accessible and so we can use it to power real-time decisions on the front line of service delivery — such as in the contact center or in the field.
Typically, this process involves a high degree of manual intervention because the data must be identified, understood (structure, relevance, attributes), normalized, and then tagged so that it can be used to train a machine-learning algorithm — in other words a model that can predictably perform specific actions on more of this data.
Broadly speaking, therefore, data ingestion consists of three steps:
- Extracting data from multiple heterogenous sources;
- Transforming the extracted data through a process of validation, parsing, cleaning, and normalizing for accuracy and reliability; and then
- Loading the data into target destinations as sources for specific applications.
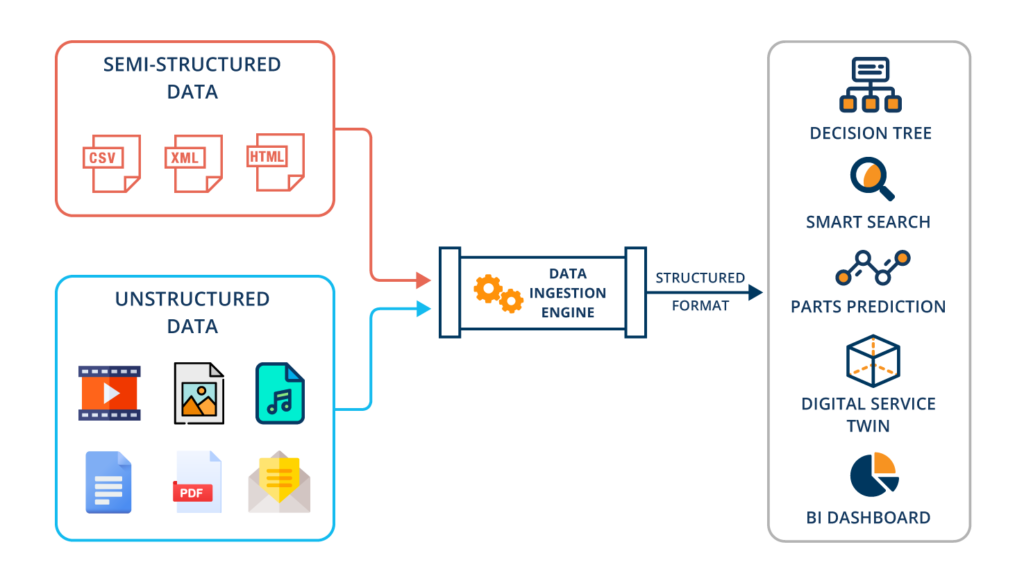
As depicted in the diagram, a mix of structured, semi-structured, and unstructured data is extracted, transformed and then categorized (along with metadata and tags) so it can be utilized to develop and train models that address industry-specific problems. Due to our deep experience with parsing these various data types, the Bruviti data science team has developed and perfected machine-learning algorithms to automate the data-ingestion process.
By applying machine learning at this stage, we eliminate the laborious hand tagging or coding that is typically required to convert customer data and content from disparate sources into a format that Bruviti’s machine-learning systems can understand. For Bruviti clients, this approach means we can move quickly through the data ingestion cycle and get to market faster with AI-powered apps for service organizations.
Suggested next steps
If you and your team are assessing how to leverage machine learning and AI to accelerate your internal process, our technical team can assist in the location of these diverse data sources, documenting current workflows and processes, and from this formulating a proof of concept. Contact us to set up a discussion with our sales team.